みなさんこんにちは!ヒロポンです!
X見てるとマジで「本番でだけページングが急に死んだ」って人多い!!!あーーみんなハマってるんだなーって。
ステージングはデータ少なくて400ページまでしか試してなくて1000ページ超えたあたりでoffsetが重くなって露呈する、みたいな罠。
同業から「Skip Takeで大量データ回すとスキップした分までDBが全部見るからなんと無駄に重くなる」って聞いた時あーー私もやったなーって思って笑えなかった。
offsetの値デカくなるとlimit+offsetは明らかに遅くなるから深いページではkeyset/cursorでキー指定して直接拾う方がマシらしいって話もよく聞く話。
でね、月締めの夜、CSV1万行を画面に小分けして表示したい場面に遭遇しません?忙しい時に限って。
「SQLでページング書き換えりゃいいだろ」って言うのは簡単ですよ簡単。いうのは簡単。
でもさDBAが翌朝じゃないとテーブル定義に触れない現場って業務系では普通にあるんですよね??ありますよね。多分あるはず。
で、そういう時に頼るのがC#側でDataTableをpageSizeずつスライスするやり方。
今回はDataTableのページング3パターン(Skip&Take / for + Rows[i] / GroupByページ番号化)を、.NET 9で実走したターミナル出力つきで並べていきます。
💡 DataTableにLINQをかける基本3パターン (Where / GroupBy / CopyToDataTable)は別記事 C# DataTableをLINQでフィルタ・GroupBy・分割する3パターンで解説しています。今回はページング軸に絞った応用編です。
忙しいあなた向けに最初にまとめ!!- DataTableをページングする3パターン: ① AsEnumerable + Skip&Take (LINQ標準・読みやすい)/ ② for + Rows[i] (LINQ不使用・メモリ効率)/ ③ GroupBy(i / pageSize) (全ページ一括分割)
- 1ページずつ画面表示するなら①Skip&Take、大量データのバッチ処理は②for、全ページを横断処理するなら③GroupBy
- ハマりは3つ: Skip(N)の線形コスト / 境界(pageSize >残り行数) / GroupBy版の全ページメモリ保持
- Docker (verify-dotnet9 / .NET 9 SDK)検証はC#言語仕様レベル。DataAdapterの実DB接続部分は別途SQL Server / Oracle実環境で確認してください
以上!!!!!
前提— AsEnumerable()とField()は#10で
ページング3パターンに入る前に、DataTableをLINQで扱う土台を1段だけ整理します。
DataTableはIEnumerable<DataRow>を直接実装してないので、WhereやSkipがそのまま生えません。
AsEnumerable()を噛ませるとLINQ一式が使えます。値の取り出しもrow["col"]のキャストじゃなくrow.Field<T>("col")の方がDBNullで落ちにくい。
この2点の詳細は別記事 C# DataTableをLINQでフィルタ・GroupBy・分割する3パターンで書いてあるので、今回は省略します。
これは関連する話なので、興味がある人は別タブ開いて後で読んでくださいな
今回はページング軸に集中。ってことで本題!!
パターン①: AsEnumerable().Skip(offset).Take(pageSize)
LINQ標準で一番素直なのがこれ。
verify-dotnet9 containerで実走した結果も貼ります。
using System;
using System.Data;
using System.Linq;
var dt = new DataTable();
dt.Columns.Add("id", typeof(int));
dt.Columns.Add("name", typeof(string));
for (int i = 1; i <= 10000; i++) {
dt.Rows.Add(i, $"item-{i}");
}
int pageSize = 1000;
int totalPages = (dt.Rows.Count + pageSize - 1) / pageSize;
Console.WriteLine($"Total rows: {dt.Rows.Count}, pageSize: {pageSize}, totalPages: {totalPages}");
for (int page = 0; page < 3; page++) { // 先頭3ページだけサンプル表示
var rows = dt.AsEnumerable()
.Skip(page * pageSize)
.Take(pageSize)
.ToList();
Console.WriteLine($"Page {page}: rows={rows.Count}, first id={rows.First()["id"]}, last id={rows.Last()["id"]}");
}
Docker (verify-dotnet9 / .NET 9 SDK)で実行した結果がこちら。
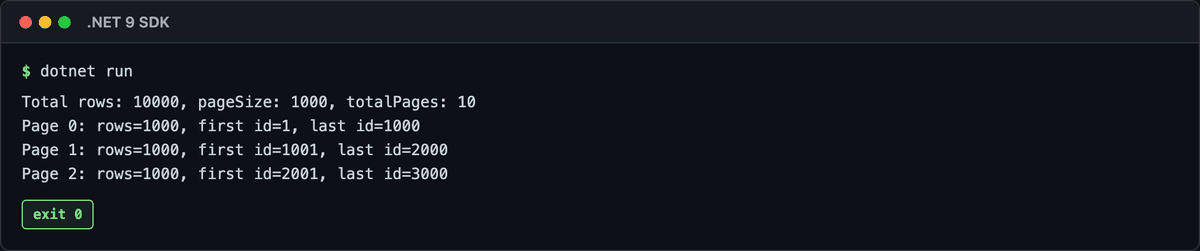
各ページがちょうど1000行ずつ、idも1-1000 / 1001-2000 / 2001-3000と綺麗に切れてます。
totalPages = 10で10000行を10ページに分割成功。よっしゃ!!
向き/不向き:
- ◎画面に1ページずつ表示(ASP.NETのPaged List / DataGridViewの手動ページング)
- ×大きいoffset (Skip(9000)など)は線形コストが効いて遅くなる←ハマりポイント①で詳説
パターン②: forループ+ Rows[i] (LINQ不使用・メモリ効率)
LINQを使わない素直な書き方。
業務SE流の枯れた書き方で、メモリ効率では最強。
var dt = new DataTable();
dt.Columns.Add("id", typeof(int));
dt.Columns.Add("name", typeof(string));
for (int i = 1; i <= 10000; i++) {
dt.Rows.Add(i, $"item-{i}");
}
int pageSize = 1000;
int totalRows = dt.Rows.Count;
int totalPages = (totalRows + pageSize - 1) / pageSize;
for (int page = 0; page < totalPages; page++) {
int start = page * pageSize;
int end = Math.Min(start + pageSize, totalRows); // 境界処理
for (int i = start; i < end; i++) {
DataRow row = dt.Rows[i];
// ここでバッチ処理 (DB INSERT / API POST など)
}
Console.WriteLine($"Page {page} processed: {end - start} rows");
}
ポイントはMath.Min(start + pageSize, totalRows)の境界処理。
最終ページはpageSizeより少ない行数になる(10000行÷ pageSize=300なら最終ページは100行)ので、ここを忘れるとIndexOutOfRangeExceptionで死にます。
これがマジで罠のハマりポイント②。
向き/不向き:
- ◎大量データのバッチ処理(1ページずつDBに流すなど・行参照のみでコピー無し)
- ×「画面のNページ目だけ取り出す」用途には冗長
パターン③: GroupBy((row, i)=> i / pageSize)で全ページ一括分割
LINQで「全ページを一気にグループ化」する変則パターン。
全ページを横断処理する時に楽。
using System;
using System.Data;
using System.Linq;
var dt = new DataTable();
dt.Columns.Add("id", typeof(int));
dt.Columns.Add("name", typeof(string));
for (int i = 1; i <= 10000; i++) {
dt.Rows.Add(i, $"item-{i}");
}
int pageSize = 1000;
var pages = dt.AsEnumerable()
.Select((row, i) => new { row, i })
.GroupBy(x => x.i / pageSize)
.ToList();
Console.WriteLine($"Total pages: {pages.Count}");
foreach (var page in pages.Take(3)) {
var rows = page.Select(x => x.row).ToList();
Console.WriteLine($"Page {page.Key}: rows={rows.Count}, first id={rows.First()["id"]}, last id={rows.Last()["id"]}");
}
実際にやってみた結果がこれ。
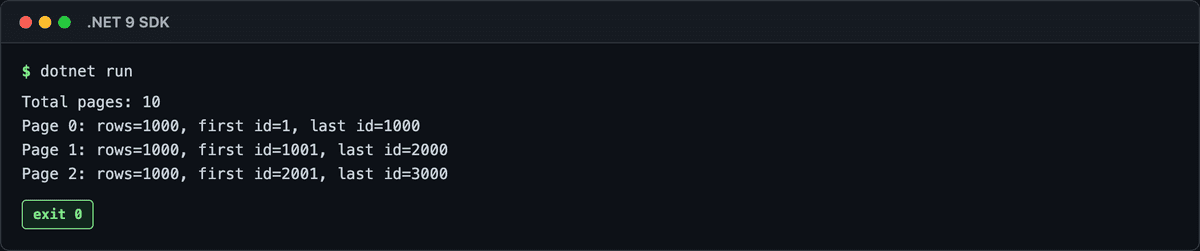
Select((row, i) => ...)でindexを取り出して、i / pageSizeで0, 0, 0… 1, 1, 1…とページ番号に変換。
GroupByでそのまま分割。Total pages: 10、各ページちょうど1000行で揃ってます。
向き/不向き:
- ◎全ページを横断処理(各ページごとに別ファイル出力など)
- ×
ToList()した瞬間に全ページがメモリに乗るので大量データ向きじゃない←ハマりポイント③で詳説
3パターン比較表— 3軸で違いを並べる
3パターンを大量行耐性/メモリ効率/再実行可能性の3軸で並べたのが下の表です。
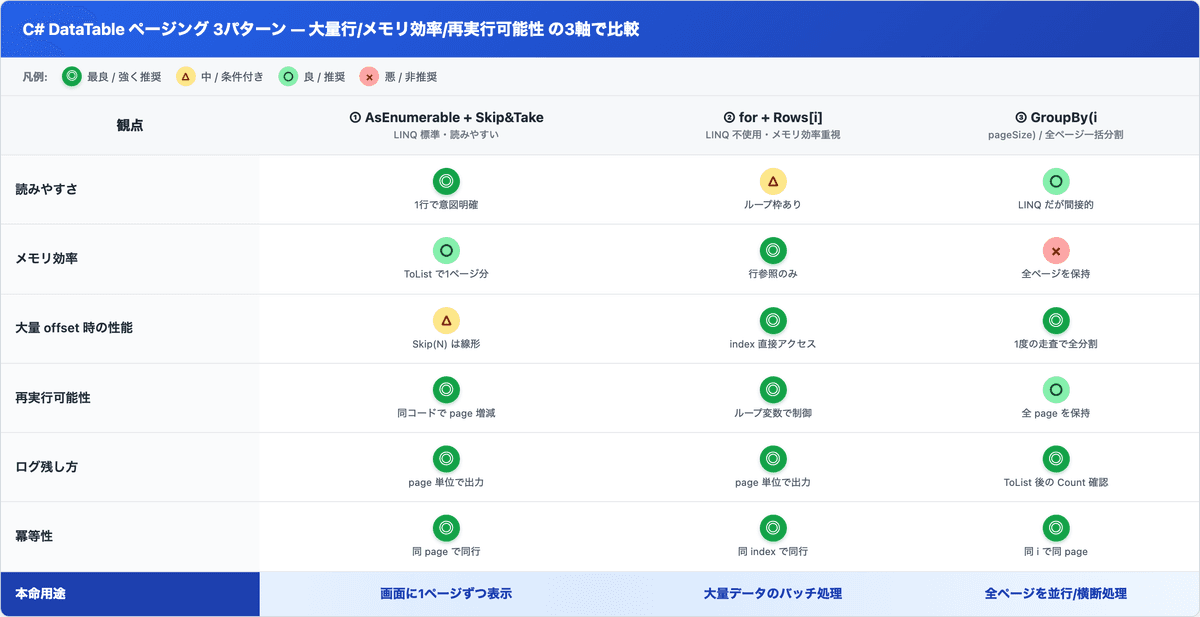
要点:
- 画面に1ページずつ表示したいなら①Skip&Take (LINQ 1行で意図が明確)
- 大量データを順に流すバッチ処理は②for + Rows[i] (メモリ効率最強)
- 全ページを横断処理したいなら③GroupBy (ただしメモリ全保持の罠あり)
「1万行を1000件ずつ処理する」という入口の同じ要件でも、出口の用途次第で正解が変わる、ってのが業務系のリアル。
ハマりポイント—そうじゃないケースが3つあります
ここまで「3パターン使い分けでいい感じに回る」みたいに書いてきましたが、そうじゃないケースが3つあります。
あなたのために特別に共有しておきます。
① Skip(N)の線形コスト—大きいoffsetで詰まる
Skip(N)はN行を1個ずつ進めて捨てる実装なので、Nが大きいほど遅くなります。
1万行でSkip(9000).Take(1000)をやると、9000行を空読みしてから10ページ目を取る挙動。
ある夜間バッチで10万行のDataTableをSkip&Takeで順処理してたら、後半のページが明らかに遅くなって朝の処理がなんと30分オーバーした経験。私もあります。
後で計測したら、後半ページの平均処理時間が前半の8倍。朝礼までに戻さないとアカン。。という時間制約で背中に冷や汗ダラダラ。
まじでやらかした。
対策は大きいoffsetではfor + Rows[i] (パターン②)に切り替える。
10万行クラスから上はLINQ Skipよりindex直接アクセスの方が安全です。
② forループ版で境界処理を忘れる
パターン②のMath.Min(start + pageSize, totalRows)を書き忘れると最終ページでIndexOutOfRangeExceptionが出ます。
私もこれで、後輩のコードレビューで「pageSize=1000固定で9999行のDataTableを回したら最後1行で落ちます」という事象に2時間付き合ったことがあります。
定時で帰る予定が。。。残業。その後後輩と飲みながら反省会www
ループ内でdt.Rows[i]を呼ぶ前にindexが範囲内か確認するクセは付けた方が安全。
対策は境界処理を1行で書く: int end = Math.Min(start + pageSize, totalRows);。
これだけで最終ページの行数がpageSize未満でも落ちなくなります。
③ GroupBy版で全ページをメモリ保持する
パターン③のGroupBy(...).ToList()は便利なんですが、全ページのIGroupingをメモリに展開するので、大量データだとメモリを食い潰します。
月締めバッチで50万行のDataTableをGroupByで全ページ分割したら、プロセスのメモリ使用量がなんと3倍に膨らんでOOM寸前までいった事象もまあまああるらしい
対策は大量行でforeachする用途ならSkip&Takeを都度生成する方が省メモリだと思う。
GroupByは「全ページの統計を1度に出したい」等の横断処理が必要な時に絞るのが安全。
まとめ
DataTableのページングは入口は同じでも出口の用途で正解が変わる領域。
3軸で整理すると:
- 画面表示のページング → ①Skip&Take (LINQ 1行で意図明確)
- バッチ処理で1ページずつ流す → ②for + Rows[i] (メモリ効率最強)
- 全ページを横断処理 → ③GroupBy (ただし大量行は要注意)
これでDataTableの月締めバッチはいい感じに9割は捌けます!!!
ぶっちゃけ、「ページング」って単語でSQLのLIMIT/OFFSETを最初に思い浮かべる業務SEが多いんですけど、こんな感じでC#側でも普通に書ける選択肢を持っとくと、DBAが掴まらない夜中の障害対応で「ん??こっちでC#側で分割すりゃ朝までに終わるんじゃない?」と即判断できるようになるので、結構美味しいスキルです!!!!
実際、SQLのページング書き換えを依頼するよりC#でループ書いた方が当日対応が現実的な現場、結構あるんですよね。。。
よくある質問
Q1. 1万行のDataTableにSkip(9000).Take(1000)は遅いですか?

A. Skip(N)はN行を線形に走査するので、pageが末尾に近づくほど遅くなります。
1万行クラスならまだ実用範囲ですが、10万行クラスから上はfor + Rows[i] (パターン②)に切り替えた方が安全です。ハマりポイント①で詳しく書きました。
Q2. GroupByで全ページ分割した結果は遅延評価ですか?
A. ToList()を呼んだ瞬間に全ページ分のIGroupingがメモリ上にマテリアライズされます。
大量行でforeachする用途には向きますが、省メモリ目的ならSkip&Takeを都度生成する方が軽いです。ハマりポイント③で詳しく書いた通り、大量データだとOOMリスクあります。
Q3. AsEnumerable()のリファレンスが見当たらないエラーが出ます
A. System.Data.DataSetExtensionsの参照が必要です。
.NET Framework 4.0+なら標準で含まれていますが、.NET 6+ではNuGet経由でインストールする必要があります。詳細は別記事 C# DataTableをLINQでフィルタ・GroupBy・分割する3パターンの前提節で書いてあります。
関連記事


以上!
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。 現職は SEO 直轄部の AI アドバイザー兼 PL、 副業で中小 SIer の CTO。 SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」 の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る



