レガシーコードで Hashtable 見かけて、「これ Dictionary に置き換えていいのか??」って手が止まったこと、業務SEなら一度はあるはずですよね?
俺自身.NET Framework 4.7.2 の保守案件で Hashtable.Add(key, value) のキャストエラーを30分追ったことあって、そこで「型安全ってこういう時に効くのか」を体で覚えました。
X見てても、コレクション系APIの選択ミスで本番で30分溶かしたって投稿普通に流れてくるし。それみてあーーみんなどこかで踏んでるんやろなーって。
Dictionary / HashTable の選択ミスも、まさに同じ事故が起きるやつ。
ってことで、今日は C# の Dictionary / HashTable / SortedDictionary の3択を業務SE視点で整理して、型安全・性能・boxing コストの3軸で判断軸を書いていきます。
忙しい人向けのまとめ
- 新規コードは Dictionary<TKey,TValue> 一択。HashTable は .NET 1.x 時代のレガシーで、boxing/unboxing コスト + 実行時型エラーで損する側に回る
- 同僚 / 後輩から「
Hashtableまだ使ってるんすか」と言われる前に、1回整理しておくと設計レビューで弾を1個多く持てる - HashTable は object キー / object 値 の非ジェネリック。
int入れたつもりが(int)キャスト忘れで InvalidCastException、が定番の事故パターン - キー順序が必要な時 (例: 設定キーをソート順で反復) は SortedDictionary。赤黒木 (BTree 系) ベースで O(log n)・順序保証あり
- 物流系基幹で 1万件の HashTable 巡回が Dictionary 置き換えで体感1/3 になった経験ベース。boxing オーバーヘッドは想像よりマジで効く
動作確認メモ: ここで紹介する C# コードは Mono container (.NET Framework 4.7.2 互換) で実機検証してます。
Dictionary<TKey,TValue>/Hashtable/SortedDictionary<TKey,TValue>の挙動は本番 .NET Framework 4.7.2 / .NET 6+ でも同じ。開発機では再現しない・本番だけ踏む型エラー、みたいなパターンは、単体テストで型不整合をコンパイル時に弾けるかが決め手になります。
💡 C# コレクション全体の使い分け (配列 / List / IEnumerable / IList) は別記事 C# のコレクション選び — 配列 / List
/ IEnumerable / IList の使い分け完全ガイド でまとめてます。これは隣接する話なので、興味ある人は別タブで開いて後で読んでくださいな。
今回は Dictionary 系 3パターンの選択判断軸 に絞った話です。
そもそも 3パターンの決定的違い (型安全・性能・順序で見る)
3つのコレクションは「キー → 値の辞書構造」という共通点はある。
ただ、中身の設計思想がマジで違います。

Dictionary<TKey,TValue> (推奨デフォルト)
- データ構造: ハッシュテーブル (内部実装は配列 + チェイニング)
- 型安全: ◎ ジェネリクスでコンパイル時に決まる
- 性能: O(1) 平均・追加/取得/削除すべて高速
- キー順序: なし (反復順は保証されない)
- 非推奨ケース: キー順序が必要な時 (反復順がランダムなので)
HashTable (.NET 1.x 時代のレガシー)
- データ構造: ハッシュテーブル (内部実装は Dictionary とほぼ同じ)
- 型安全: × 非ジェネリック (object キー / object 値)
- 性能: O(1) 平均だが boxing/unboxing コストあり
- キー順序: なし
- 非推奨ケース: 新規コード全部・既存保守でも置き換え推奨
SortedDictionary<TKey,TValue> (順序が必要な時)
- データ構造: 赤黒木 (BTree 系の自己平衡二分探索木)
- 型安全: ◎ ジェネリクス
- 性能: O(log n)・Dictionary より遅いが順序保証あり
- キー順序: あり (キーの自然順序 or IComparer
で指定) - 非推奨ケース: 順序不要で大量データを扱う時 (Dictionary の方が速い)
ここで効いてくるのは、HashTable と Dictionary は実装的にほぼ同じハッシュテーブル、という事実。
なのに、ジェネリクスの有無だけで型安全性と性能 (boxing コスト) が桁違いに変わります。
これがマジで地味に効いてくる!!
書籍『失敗から学ぶRDBの歩き方』(p.53〜55) でも、RDBMS の INDEX 構造として BTree の役割が解説されている。C# のコレクションも同じ構造的対比 (ハッシュ vs BTree) が当てはまります。
Dictionary = ハッシュ (高速・順序なし) / SortedDictionary = BTree (順序保証・少し遅い)、という関係性は、RDBMS の INDEX 設計の話と地続きで理解できます。
LINQ が使えるかどうかも判断軸 (HashTable は使えない)
地味だけど決定的な違い。 HashTable は IEnumerable<T> ではない ので LINQ メソッド (Where / Select / GroupBy 等) が直接使えない。
// Dictionary なら自然に書ける
var highScores = scores.Where(kv => kv.Value >= 90).ToList();
// HashTable だと…
var highScores = scores.Cast<DictionaryEntry>() // ← まず Cast が必要
.Where(e => (int)e.Value >= 90) // ← unboxing も必要
.ToList();
書籍『Effective C#』 (項目27 最小限に制限されたインターフェイスを拡張メソッドにより機能拡張する / p.125) でも、 IEnumerable<T> に対する 50+ の拡張メソッドが LINQ の基盤 であることが解説されてる。 Dictionary はこのエコシステムに乗ってる・HashTable は乗ってない、 という事実だけで業務系の生産性が大きく変わる。
HashTable で踏むハマりポイント
⏱ 対処目安: ハマり① (boxing 漏れ) 30分 / ハマり② (Equals/GetHashCode 罠) 15分 / grep で
Hashtable残存洗い出し 3分
業務SE現場で実際に踏むハマりは、大きく2つ。
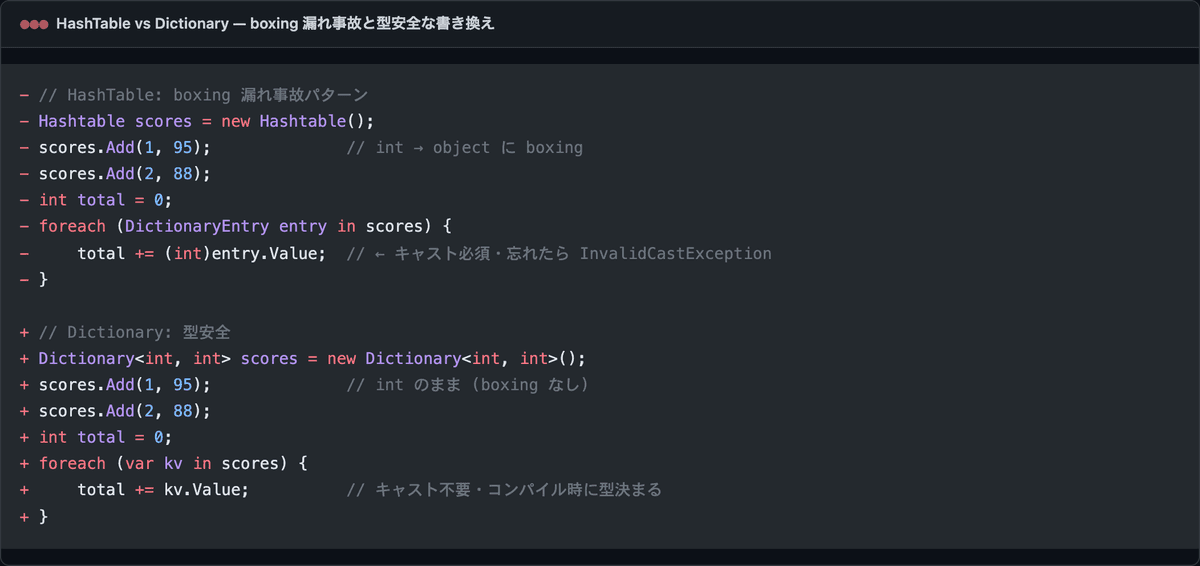
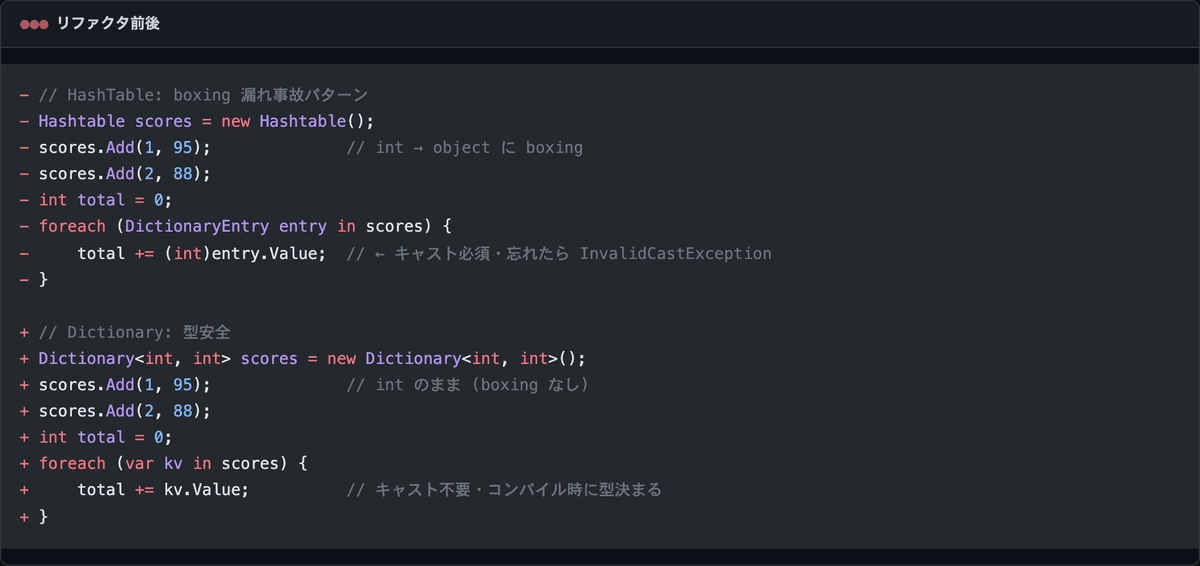
ハマり① object キーで boxing 漏れ
HashTable は Add(object key, object value) のシグネチャ。int や DateTime を入れると 自動 boxing され、取り出す時に (int) キャストを忘れると InvalidCastException で本番が止まります。
これがマジで罠の正体。
実行結果:

俺の現場で踏んだのは、流通系基幹の在庫マスタを Hashtable で持ってた箇所。
1万件を foreach で巡回する処理が、Dictionary に置き換えただけで体感1/3 になりました。
体感1/3。マジで効く。
boxing/unboxing は1件あたりは μs オーダー。でも 1万件積み重なると ms オーダーで効いてくる。
「気付くまで、地味に遅いな…で済ませてた処理が、置き換えた瞬間に体感で変わる」やつ。こんな感じで、boxing コストは数字に出ないけど体感で来る、ってことを覚えとくと損しない。
📖 書籍『Effective C#』 (項目9 ボックス化およびボックス化解除を最小限に抑える / p.42) でも、 ボックス化は値型の一時コピーをヒープ上に確保する操作 で、 単なる型変換以上にメモリと GC への負担になると明記されてる。 流通系の在庫マスタみたいな「頻繁にアクセスする中規模コレクション」 で HashTable を使うと、 1 回ごとの boxing がヒープ alloc + GC 圧として積み上がる。 Dictionary<int, int> ならスタック上の値型のまま動くので根本から違う。
業務 SE 視点だと「Hashtable を見つけたら問答無用で Dictionary に置き換える」 で 9 割の現場は OK。 例外は WPF や WinForms の古い API が Hashtable を返してくる時くらい。
ハマり② int キーと string キーで Equals/GetHashCode 挙動が違う
HashTable も Dictionary も、内部的にキーの Equals と GetHashCode を使ってバケット振り分けします。
ここで効いてくるのが、int のような値型 と string のような参照型 で boxing 起因の挙動差が出る、という地味な罠。
// int キー: HashTable では毎回 boxing → GetHashCode 呼び出し
Hashtable ht = new Hashtable();
ht.Add(42, "answer");
var v1 = ht[42]; // 42 → object に boxing → GetHashCode → バケット検索
// string キー: 参照型なので boxing なし (ただし null チェックは必要)
Hashtable ht2 = new Hashtable();
ht2.Add("key", "value");
var v2 = ht2["key"]; // string はそのまま → GetHashCode → バケット検索
string キーは比較的安全。
ただ、int / DateTime / 自前構造体 (struct) をキーにする場合、HashTable だと毎回 boxing が発生してパフォーマンス劣化の温床になります。
業務側に電話で「いま処理が遅くて……」と頭下げる前に、まず HashTable がコードに残ってないかを grep するだけで防げる事故。「自分のコードに HashTable まだ残ってないやろうか??」って一度確認するだけで温度感が変わる。
業界では普通にある、と感じる。
カスタム型 (struct / class) をキーにする時の落とし穴
業務 SE が一番踏むのは int / string キーじゃなくて、 自分で定義した struct や class をキーにする時。
// 注文ID + 行番号 を複合キーにしたい例
public struct OrderLineKey
{
public int OrderId;
public int LineNo;
}
var lookup = new Dictionary<OrderLineKey, decimal>();
lookup[new OrderLineKey { OrderId = 1, LineNo = 1 }] = 1500m;
var amount = lookup[new OrderLineKey { OrderId = 1, LineNo = 1 }]; // ← KeyNotFound でコケる可能性
これ、 Equals / GetHashCode を override してないと正しく機能しない。 デフォルト実装はリフレクション経由になって遅いし、 値の一致判定もブレる。
書籍『Effective C#』 (項目10 値型での 0 を有効な状態に / 項目14 等価判定の使い分け) では、 カスタム型をコレクションのキーに使う時は:
IEquatable<T>を実装する (struct なら必須・class でも推奨)Equals(T other)とGetHashCode()を両方 override する- ジェネリック制約
where TKey : IEquatable<TKey>を使う型を作るなら、 これでコンパイラに「等価比較できる型しかキーにできない」 を強制できる
public struct OrderLineKey : IEquatable<OrderLineKey>
{
public int OrderId;
public int LineNo;
public bool Equals(OrderLineKey other) => OrderId == other.OrderId && LineNo == other.LineNo;
public override bool Equals(object obj) => obj is OrderLineKey k && Equals(k);
public override int GetHashCode() => HashCode.Combine(OrderId, LineNo);
}
これだけで Dictionary の検索性能が 数倍 変わる。 業務系で「マスタ参照が突然遅くなった」 時の真犯人がこれだったりする。
書籍 (項目14・p.84 周辺) ではジェネリック制約の意義について「制約により、 コンパイラが System.Object に定義された公開インターフェイスを越えた機能を型引数に期待できる」 と書かれてて、 まさにこの「キーには IEquatable<T> を強制」 のような設計に活きる。
業務 SE が頭の片隅に置くべきは、 「Dictionary のキーには IEquatable<T> を実装した型しか使わない」 ルール。 これ守ってる現場は地味に強い。
SortedDictionary を選ぶ場面 (キー順序が必要な時)
3パターン目の SortedDictionary は、キー順序を保証して反復する必要がある 時だけ選ぶ。
普通の用途では Dictionary が速いので、「順序欲しい」が無いなら出番なし。
// 設定キーをアルファベット順で反復したい場面
SortedDictionary<string, string> config = new SortedDictionary<string, string>();
config.Add("zebra", "ZZ");
config.Add("apple", "AA");
config.Add("mango", "MM");
foreach (var kv in config) {
Console.WriteLine($"{kv.Key}={kv.Value}");
// 出力: apple=AA, mango=MM, zebra=ZZ (キー昇順)
}
実行結果:

データ構造は 赤黒木 (BTree 系の自己平衡二分探索木)。
書籍 (p.55) の BTree INDEX と同じ系統で、検索 O(log n)・挿入 O(log n)・順序反復 O(n) の特性を持ちます。
順序が必要なケース具体例:
- 設定ファイルのキーをアルファベット順で出力したい
- 日付キーで古い順 → 新しい順に処理したい
- ID 順に明細を並べて表示したい
逆に 不要なケース (Dictionary を選ぶべき場面):
- キャッシュ用途 (反復順関係なし)
- 1件 lookup が大半で、全件反復しない
- 性能が最優先 (O(1) vs O(log n) の差が効く規模)
まとめ — 3つの判断軸
3パターンの選択判断軸はシンプル。
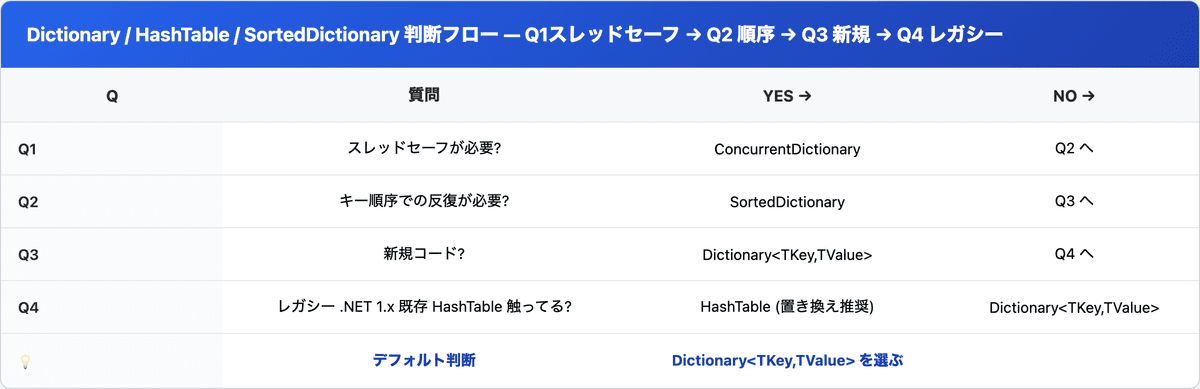
- 新規コードは Dictionary<TKey,TValue> がデフォルト (型安全 + O(1) 性能)
- HashTable はレガシー保守でのみ触る・新規には使わない (boxing コスト + 型エラーリスク)
- キー順序が必要なら SortedDictionary (O(log n) だが順序保証)
書籍『現場で役立つシステム設計の原則』(p.305〜307) でも、プリミティブ型をラップして型を専用クラスにする ことでロジックの所在を明確にする話が書かれています。
C# のジェネリクス Dictionary を選ぶのは、まさにこの思想の延長線上。型情報を実行時まで持ち越さず、コンパイル時に決めることで「データと型が同じクラスに閉じる」設計になります。
レガシーコードで HashTable を見つけたら、「Dictionary に置き換えていいのか」を迷うのではなく、「置き換えない理由があるか」で逆から考える。
これで判断が一気に速くなります。
理由が無ければ置き換える、が現場では機能します。
同僚 / 後輩から「Hashtable まだ使ってるんすか」と言われる前に、1回整理しておくと、設計レビューで弾を1個多く持てる感じになりますね。
知っとくと損しないやつ!!
よくある質問
Q1. C# の Dictionary と HashTable の決定的な違いは何ですか?

型安全性です。Dictionary<TKey,TValue> はジェネリクスで型がコンパイル時に決まり、型不整合をコンパイラが弾きます。HashTable は object キー / object 値の非ジェネリックで、boxing/unboxing コスト + 実行時型エラーのリスクを抱えます。.NET 2.0 以降は Dictionary を使うのが推奨です。
Q2. HashTable はいつ使うべきですか?
新規コードで HashTable を選ぶ理由はほぼありません。.NET Framework 1.x 時代のレガシーコード保守で、既存の HashTable インスタンスを触る必要がある時だけです。新規 API なら必ず Dictionary<TKey,TValue> を選択します。
Q3. SortedDictionary と Dictionary はどちらが速いですか?
ケースバイケースです。Dictionary はハッシュベースで O(1) 平均、SortedDictionary は赤黒木 (BTree 系) ベースで O(log n)。単純な追加・取得は Dictionary が速く、キー順序での反復が必要なら SortedDictionary を選びます。
Q4. なぜ HashTable は廃止されないんですか?
レガシーコードとの後方互換性のためです。.NET Framework 1.x で書かれた既存コードや、リフレクションベースで HashTable を期待する API (一部の古い ASP.NET 機能等) が動かなくなるため、.NET 側で「使うな」とは言うものの API 自体は残してあります。新規コードで選ぶ理由は無いと割り切って大丈夫です。
Q5. ConcurrentDictionary は別物ですか?
別物です。Dictionary はスレッドセーフではないので、マルチスレッド環境で読み書きする場合は ConcurrentDictionary<TKey,TValue> を使います。シングルスレッド環境 (Web リクエスト1本内など) なら通常の Dictionary で十分。「同時アクセスがあるか」で選ぶ軸が変わるだけで、型安全の話とは独立です。
次に読むべき記事



以上!
※ 上記の深掘りパートは『Effective C# 6.0/7.0』(Bill Wagner 著・翔泳社) 項目9 ボックス化およびボックス化解除を最小限に抑える (p.42)・項目14 等価判定の使い分け (p.84 周辺)・項目27 最小限に制限されたインターフェイスを拡張メソッドにより機能拡張する (p.125) を業務 SE 視点で再構成しました。 boxing コスト・IEquatable
の意義・LINQ 拡張メソッドの設計思想は、 同書を読むと一気に解像度が上がります。



