
みなさんこんにちは!ヒロポンです!!
今回はC#業務SE現場でガチで混乱しやすいやつ!!の話。
「メソッド作る時に戻り値はList<T>?IEnumerable<T>?配列?」「引数の型は何にすればいい?」「IEnumerable<T>をforeachで2回回したらSQLが2回発行された」みたいなコレクション型選びの事故って、業務SEで誰しも一回はやらかしますよね??
俺も2社目くらいの流通系SIer時代に、Dapperで取ったIEnumerable<T>をリストっぽく持ち回してforeachを3箇所で呼んだら、同じSELECTが3回発行されて1リクエスト3秒くらい遅くなった事件をやらかしました。ん?なんで遅いんだ??って詰まった夕方の運用報告から半日デバッガで追ってハマったやつ。原因は完全に遅延評価のまま持ち回しただけで、こんな感じで.ToList()を1行追加するだけで解決しました。
C#でデータの集まりを扱う型は4系統:
- 配列
T[](固定長・最速・APIシグネチャで時々見る) List<T>(可変長・最も多用・内部は配列ベース)IEnumerable<T>(インターフェース・遅延評価・LINQの基本型)IList<T>(インデックスアクセス+編集可・汎用的なメソッド引数型)
この記事ではVS2019 / .NET Framework 4.7.2 / C# 7.3環境で、4種類の使い分け、戻り値・引数の選び方マトリクス、遅延評価でSQL 2回発行などの罠を、コード6本でまとめます。後ろの「現場メモ」で、業務系チームでルール化した時の話も書いてる。
3行で結論:
- 戻り値=
IEnumerable<T>(公開API)orList<T>(内部実装)- 引数=
IEnumerable<T>(読み取り専用)orIList<T>(編集も必要)- 固定数のデータ=配列
T[]/動的追加削除=List<T>/ LINQ連鎖の中間=IEnumerable<T>
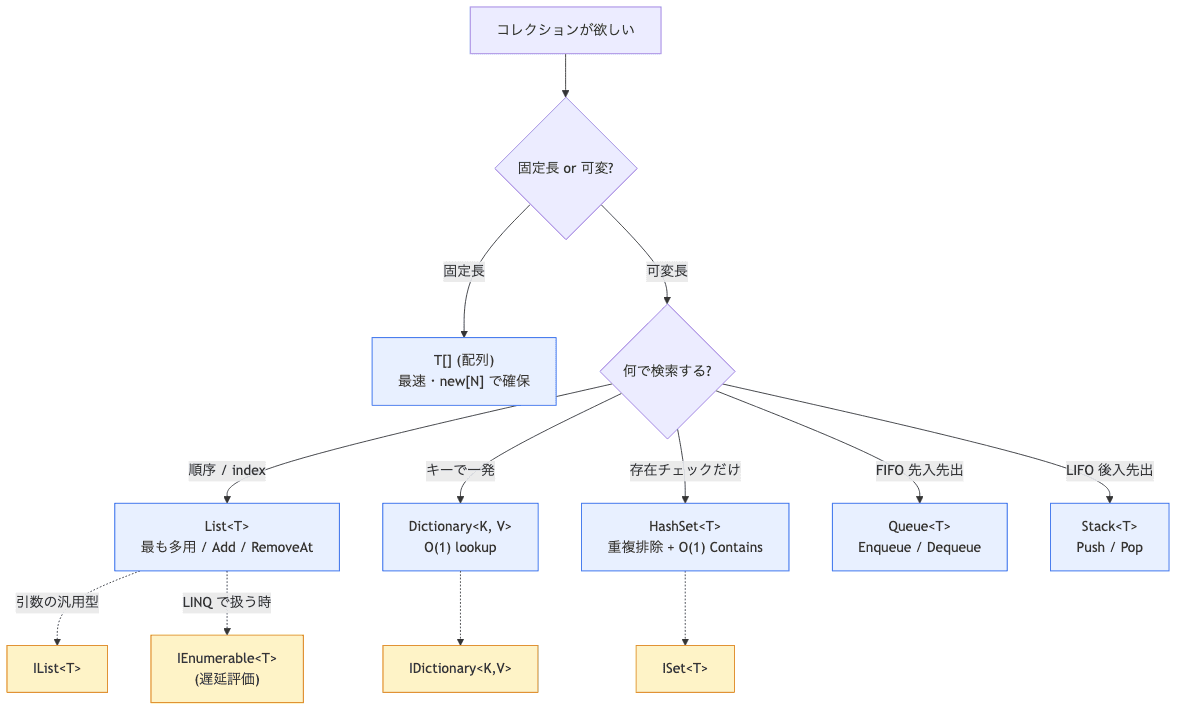
定石1:配列T[] —固定長・最速だがAPIでは出番が絞られる
C#の最も原始的なコレクション。固定長で初期化、サイズ変更不可:
// ✅定石1:配列T[] の基本
int[] daysInMonth = { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
string[] weekDays = new string[7] { "月", "火", "水", "木", "金", "土", "日" };
//インデックスアクセス
int firstMonth = daysInMonth[0]; // 31
// Lengthプロパティ(List<T>はCount、配列はLength)
for (int i = 0; i < daysInMonth.Length; i++){ /* ... */ }
// LINQも使える
int totalDays = daysInMonth.Sum(); // 365
// ❌動的追加はできない(固定長)
// daysInMonth.Add(31); //コンパイルエラー
ポイント:
- 固定長:一度確保したらサイズ変更不可
.Lengthプロパティ(Listは .Countで命名が違う)- LINQは使える(
Sum/Max/Where等) - 性能は最速(数値配列の単純ループでList
より数%速い)
業務系の判断軸: 「曜日7」「月12」「ステータス5種類」のような固定数を意味的に表現する場面で配列を選ぶ。可変長操作が要るなら次のList<T>に切り替えます。
定石2: List<T> —可変長・最も多用される実装型
業務系で最も使用頻度が高いのがこれ。可変長でAdd / Remove / Insertができる:
// ✅定石2: List<T>の基本
var customers = new List<CustomerVm>();
//追加
customers.Add(new CustomerVm { Id = 1, Name = "サンプル商事" });
customers.Add(new CustomerVm { Id = 2, Name = "山田工業" });
//インデックスアクセス
var first = customers[0];
//削除
customers.RemoveAt(0);
customers.RemoveAll(c => c.Name.StartsWith("廃止"));
// AddRangeで配列・他コレクションから一括追加
var newOnes = LoadFromDb();
customers.AddRange(newOnes);
ポイント:
- 内部は配列ベース(容量が足りなくなると自動拡張・倍々で確保)
Countプロパティ(配列のLengthと違う名前)- 可変長操作が全部使える(
Add/Insert/Remove/RemoveAt/Clear) AddRangeで他コレクションから一括取り込み
ただし公開メソッドの戻り値でList<T>を返すと、呼び出し側で勝手にAddされるカプセル化違反の罠があります。次のIEnumerable<T>で対処する話に繋がる。
定石3: IEnumerable<T> —遅延評価・LINQの基本型
IEnumerable<T>はインターフェースで、「列挙可能なデータの集まり」を表す抽象型。LINQの戻り値はほぼ全部これ:
// ✅定石3: IEnumerable<T>と遅延評価
public IEnumerable<CustomerVm> GetActiveCustomers()
{
return _db.Customers
.Where(c => c.Status == "active")
.Select(c => new CustomerVm { Id = c.Id, Name = c.Name });
// ↑この時点ではSQLはまだ発行されない(遅延評価)
}
//呼び出し側
var customers = GetActiveCustomers();
// 1回目のforeachで初めてSQL発行
foreach (var c in customers)
{
Console.WriteLine(c.Name);
}
// ⚠️ 2回目のforeachで同じSQLがもう一度発行される!
foreach (var c in customers)// ← 2回目のSQL発行
{
Logger.Info(c.Name);
}
// ✅対策: ToList()で具体化して持ち回す
var customerList = GetActiveCustomers().ToList(); //この時点でSQL 1回
foreach (var c in customerList){ /* 1回目 */ }
foreach (var c in customerList){ /* 2回目(SQL再発行なし)*/ }
ポイント:
- 遅延評価(実際に
foreach/ToList/ToArrayが呼ばれた瞬間に評価) - 複数回
foreachでSQL再発行のトラップ - 公開APIの戻り値型として優秀(呼び出し側を縛らない)
- インデックスアクセス不可(
enumerable[0]できない、First()/ElementAt(0)で代替)
業務系の判断軸: 遅延評価のメリットを活かす場面(LINQ連鎖の中間結果・大量データのストリーム処理)でIEnumerable<T>。複数回foreachする確定なら.ToList()で具体化が業務SE鉄則っす。
定石4: IList<T> —メソッド引数の汎用型
IList<T>はインデックスアクセス+編集可能な抽象型。List<T>や配列も実装している:
// ✅定石4: IList<T>をメソッド引数で受ける
public void ProcessCustomers(IList<CustomerVm> customers)
{
//インデックスアクセス
var first = customers[0];
// Count
int total = customers.Count;
//追加・削除も可能
customers.Add(new CustomerVm { Id = 999, Name = "新規" });
}
//呼び出し側: List<T>でも配列でも渡せる
List<CustomerVm> list = LoadFromDb();
CustomerVm[] array = list.ToArray();
ProcessCustomers(list); // OK
ProcessCustomers(array); // OK(配列もIList<T>実装)
// IEnumerable<T>だけ渡せない(編集できないので)
IEnumerable<CustomerVm> enumerable = LoadFromDb();
// ProcessCustomers(enumerable); //コンパイルエラー
ポイント:
- インデックスアクセス+編集可能なインターフェース
List<T>も配列もIList<T>を実装している- 呼び出し側の選択肢が広がる(具体型を縛らない)
ICollection<T>/IReadOnlyList<T>などの派生もある(用途別に絞り込む)
業務系の判断軸: メソッドの引数で「編集も必要」な場合にIList<T>寄せ。読み取り専用ならIEnumerable<T>、編集したいならIList<T>、List<T>直接指定は避けるが原則っす。
定石5:共変・反変の罠— IEnumerable<T>は共変・IList<T>は不変
これも業務系で地味にハマるところ。型パラメータの変位の話:
// ✅定石5:共変(covariance)の例
class Animal { }
class Dog : Animal { }
// ✅ IEnumerable<Dog>はIEnumerable<Animal>に代入可能(共変・out T)
IEnumerable<Dog> dogs = new List<Dog> { new Dog(), new Dog()};
IEnumerable<Animal> animals = dogs; // OK
//「Dogの列挙はAnimalの列挙としても扱える」
// ❌ List<Dog>はList<Animal>に代入できない(不変)
List<Dog> dogList = new List<Dog>();
// List<Animal> animalList = dogList; //コンパイルエラー
//「List<Animal>にCatをAddされる可能性があるので不可」
// ❌ IList<Dog>もIList<Animal>に代入できない(不変)
IList<Dog> dogIList = new List<Dog>();
// IList<Animal> animalIList = dogIList; //コンパイルエラー
//「IList<Animal>.Add(new Cat())ができてしまうので不可」
ポイント:
IEnumerable<out T>は共変(outキーワード=派生型を基底型に変換可能)List<T>/IList<T>は不変(編集できる型は変位許可されない・型安全のため)IReadOnlyList<out T>も共変
業務系で意外と踏みやすい罠で、「派生クラスのリストを基底クラスのリストとして渡したい」時にIEnumerable<T>寄せにする判断軸の根拠になります。
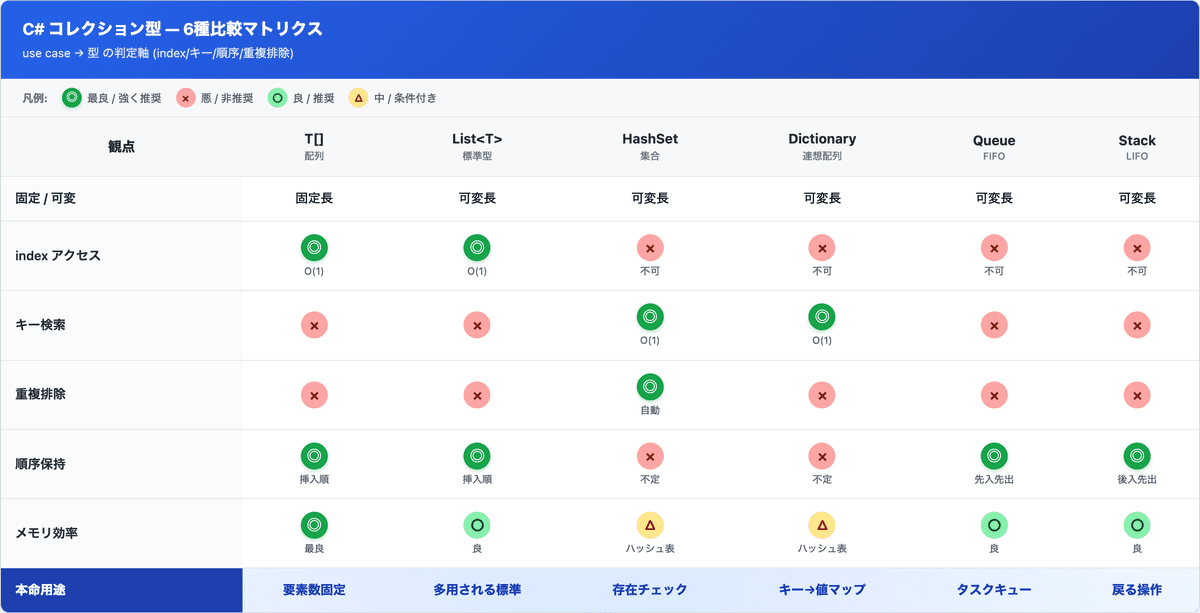
使い分けマトリクス—戻り値×引数×用途
業務系で迷う場面の使い分けマトリクスを表で整理:
| 場面 | 推奨型 | 理由 |
|---|---|---|
| 公開APIの戻り値(外向き) | IEnumerable<T> |
呼び出し側を縛らない・後から実装変えやすい |
| 内部実装の中間変数 | List<T> |
インデックスアクセス・Count・編集が要る |
| 公開APIの引数(読み取り) | IEnumerable<T> |
呼び出し側の自由度を奪わない |
| 公開APIの引数(編集もしたい) | IList<T> |
List |
| 固定数のデータ | 配列T[] |
「曜日7」「月12」を意味的に表現 |
| 動的追加・削除が頻発 | List<T> |
可変長操作が一通り使える |
| LINQ連鎖の中間結果 | IEnumerable<T> |
遅延評価で中間メモリ節約 |
| インデックスアクセスとカウントが要る | IList<T> or List<T> |
[0]と.Countの両立 |
| 派生型のリストを基底型として | IEnumerable<T> |
共変が効くのはこれだけ |
ハマりポイント—実体験ベースの本番事故3点
1. IEnumerable<T>の複数回foreachでSQL 3回発行(半日デバッガで追ってハマった)
Dapperで取った結果をIEnumerable<T>のまま持ち回して、foreachを3箇所で呼んだら同じSELECTが3回発行されて1リクエスト3秒遅くなる事件。夕方の運用報告で気づいて半日デバッガで追ってハマった末に、最初の取得時に.ToList()で具体化して解決。遅延評価系を持ち回す時はToList()でメモリに確定を業務系チーム規約に揃えた。
2.公開メソッドでList<T>返したら呼び出し側で勝手にAddされた(30分溶かした)
公開クラスのプロパティをList<T>で公開していて、外部からcustomers.Add(...)で勝手に追加される事故。カプセル化違反で内部不整合が起きた事件。30分溶かした末に、戻り値をIEnumerable<T>に変更(or IReadOnlyList<T>を採用)して解決。公開APIはIEnumerable
3. int[]の.LengthとList<int>.Countを取り違えた(夕方の運用報告で気づいた)
ジェネリックメソッドで配列とList.Lengthを.Countと書いてコンパイルエラー、逆にList.Countを.Lengthと書いてエラー、を繰り返した。夕方の運用報告で「ビルドエラー残ってる」って指摘で気づいた。IList.Countに統一
俺の現場メモ—業務系チームでのコレクション規約
流通系SIer時代に過去コードをgrep -rnE "List<|IList<|IEnumerable<" .で100箇所近くひっかけたら、公開メソッドでList<T>返してる箇所・IEnumerable<T>を複数回foreachしてる箇所・配列とList.Length .Countが混乱してる箇所、全部入りだった。後輩と一緒に3行ルールにまとめた:
- 公開APIの戻り値は
IEnumerable<T>、内部実装はList<T>(カプセル化) IEnumerable<T>を複数回foreachする確定なら.ToList()で具体化(SQL再発行予防)- メソッド引数は読み取り
IEnumerable<T>/編集IList<T>/固定数配列(呼び出し側の自由度)
このルール化で、コレクション周りのカプセル化違反/ SQL再発行/ .Length .Count混乱が消えた。書き方を1パターンに揃えるだけで保守工数と事故率が両方下がるので、業務系チームにはおすすめのルールっす。
C# 7.3 + .NET Framework 4.7.2のレガシー業務系って、コレクションAPIは10年以上変わってないのに、書き方が現場ごとにバラバラなコードベースが本当に多い。書き方のアップデートだけで保守工数が下がる実例だと思ってます。
まとめ
| 場面 | 推奨型 |
|---|---|
| 公開API戻り値 | IEnumerable<T> |
| 内部実装の中間変数 | List<T> |
| 公開API引数(読み取り) | IEnumerable<T> |
| 公開API引数(編集も) | IList<T> |
| 固定数のデータ | 配列T[] |
| 動的追加削除頻発 | List<T> |
| LINQ連鎖の中間 | IEnumerable<T> |
| 複数回foreach確定 | .ToList()で具体化 |
| 共変を使いたい(派生→基底) | IEnumerable<T>(out T) |
C#のコレクション選びは、「戻り値は外向き/内向きで分ける」「複数回foreachはToListで具体化」「引数は呼び出し側を縛らない」の3点で9割困らなくなります。List<T>を裸で公開メソッドに返すと、カプセル化違反+性能事故の両方を踏みやすい。業務系の判断軸として「IEnumerable / List / IList /配列の使い分けを1パターンに揃える」のが本命の対処です。
よくある質問
Q1.メソッドの戻り値はList<T>とIEnumerable<T>、どっちにすべき?

A. 公開APIはIEnumerable<T>(呼び出し側を縛らない・後から実装を変えやすい)、内部実装はList<T>(インデックスアクセス・Countが要るな処理向き)が業務SE鉄則です。List<T>を返すと呼び出し側で勝手にAddされる事故が起きるので、外向きはIEnumerable<T>でカプセル化するのが安全。逆に内部処理でList<T>同士を渡し合うのは可読性のためにOKです。
Q2. IEnumerable<T>をforeachで複数回回したらどうなる?
A. 遅延評価のクエリだと、回すたびにSQLが発行される事故が起きます。EF6 / DapperのIQueryable<T>や、File.ReadLinesのような遅延評価系をIEnumerable<T>として持ち回した時、foreachの2回目に同じSQLを再実行する。対策は最初に.ToList()で具体化する。1回しか回さない場合は遅延評価のままでOK、複数回回す確定なら.ToList()してから持ち回すのが業務SE鉄則です。
Q3.メソッドの引数はIList<T>とList<T>、どっちにすべき?
A. 読み取り専用ならIEnumerable<T>、編集もしたいならIList<T>、List<T>直接指定は呼び出し側を縛るので原則避けます。IList<T>はインデックスアクセス(list[0])とCountとAdd/Removeが使えるインターフェースなので、List<T>や配列など複数の実装を受け取れる柔軟性がある。引数の型は呼び出し側の自由度を奪わない選び方が原則です。
Q4.配列T[]とList<T>の性能差はどれくらい?
A. 10万件規模の単純ループでは配列がList<T>より数%速い程度で、業務系の現実では誤差レベルです。配列を選ぶ理由は性能じゃなく、固定長を意味的に表現したい場合(曜日7、月12、ステータスコード5種類など)。可変長操作(Add / Remove)が頻発するならList<T>、固定数なら配列、と用途で選ぶのが業務SE鉄則です。
Q5. nullと空コレクションの判定はどう書く?
A. list?.Any()== trueが現代的な書き方です。list == nullだけだと空コレクションを取りこぼし、list.Count == 0だけだとnullでNullReferenceExceptionが飛ぶ。?.Any()でnull安全に判定しつつ要素ありをチェックできる。LINQのAny()は遅延評価でも最初の1要素で判定するので性能的にも問題ありません。
ここまででC#コレクション4種類の使い分け・遅延評価の罠・共変反変は押さえた。Linq / DataTableの隣接トピックも貼っておきます。
関連記事



以上!
同じ罠でハマってる業務SE仲間いたら、どんどんシェア待ってるぜ!!
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。 現職は SEO 直轄部の AI アドバイザー兼 PL、 副業で中小 SIer の CTO。 SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」 の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る



