
みなさんこんにちは!ヒロポンです!
「このSQL遅いんだけど見てくれない??」
業務SEの現場で一番投げられがちな相談のひとつです。
で、これを毎回DBAに丸投げしてると、後輩から「あの人SQLのことよく分かってないっぽいですよね」って評判が立つ。これ、結構しんどい。
実は実行計画って5箇所だけ押さえれば80%は1次切り分けできます。DBAレベルの細かい話は除外して、業務SEが「SELECT文の遅い原因をある程度推測する」ところまで行ければOK。
今回はSQL Serverの実行計画(Execution Plan)を、SSMSのグラフィカル無しで読む方法を、Dockerで実走したターミナル出力つきで解説していきます。
忙しい人向けに最初にまとめ
- 実行計画は
SET SHOWPLAN_TEXT ONでテキスト形式で取れる(sqlcmdでもOK) - 最初に見るのは① Index Seek/Scanの種別・② EstimatedとActualの乖離・③コスト%・④ Sort/Hashの登場・⑤ Key Lookupの有無の5箇所
- 件数が少ないテーブル(1万件以下くらい)はIndexを作ってもScanに倒れる。これがハマりポイント№1
実行計画の正体— EstimatedとActualの違い
実行計画には2種類あります。
- Estimated (見積):クエリを実行する前に、オプティマイザが「こう動くつもり」と立てた計画。統計情報を元に試算
- Actual (実測):クエリを実行した後に、実際にどう動いたかを記録した計画
業務SEが日常的に見るのはEstimated。SHOWPLAN_TEXTで出るのもこっち。ただし、EstimatedとActualが大きくズレている時に問題が起きる。
たとえばEstimatedが「100行返ってくる予定」でプランを組んだのに、実際は10万行返ってきた、みたいなケース。オプティマイザが間違った前提でプランを選んだから、結果として遅い。
ここで「統計情報が古いんじゃないか??」と疑える業務SEは、もうDBA半人前くらいの戦力です。
SET SHOWPLAN_TEXTで実行計画を取る
SSMSのグラフィカル機能無しで、こんな感じでテキストの実行計画が取れます。
SET SHOWPLAN_TEXT ON;
GO
SELECT * FROM dbo.tmp_orders WHERE customer_id = 1;
GO
SET SHOWPLAN_TEXT OFF;
GO
ポイントは2つ。
SET SHOWPLAN_TEXT ONを投げた後のSELECTは実行されず、計画だけ返ってくるGOでbatchを区切ること。SHOWPLAN_TEXTはbatchの唯一のstatementである必要がある(CREATEと同batchに置けない)
Azure Data Studioやsqlcmdでも普通に動くので、SSMSが現場PCに入ってない時の救世主です。
ハンズオン#1 — Index Seekが出るケース
実際にやってみます。10000件のオーダーテーブルに、customer_id列のインデックスを張った状態。
--準備:通常テーブル+インデックス+ 1万件投入+統計更新
IF OBJECT_ID('dbo.tmp_orders','U')IS NOT NULL DROP TABLE dbo.tmp_orders;
CREATE TABLE dbo.tmp_orders (id INT IDENTITY PRIMARY KEY, customer_id INT, amount INT);
CREATE INDEX IX_customer ON dbo.tmp_orders(customer_id);
WITH n AS (
SELECT TOP(10000)ROW_NUMBER()OVER (ORDER BY (SELECT 1))AS r
FROM sys.all_objects a CROSS JOIN sys.all_objects b
)
INSERT INTO dbo.tmp_orders (customer_id, amount)
SELECT (r % 1000)+ 1, (r * 7)% 9999 FROM n;
UPDATE STATISTICS dbo.tmp_orders;
GO
--実行計画を取る
SET SHOWPLAN_TEXT ON;
GO
SELECT * FROM dbo.tmp_orders WHERE customer_id = 1;
GO
SET SHOWPLAN_TEXT OFF;
GO
Azure SQL Edge containerで実走した結果がこちら。
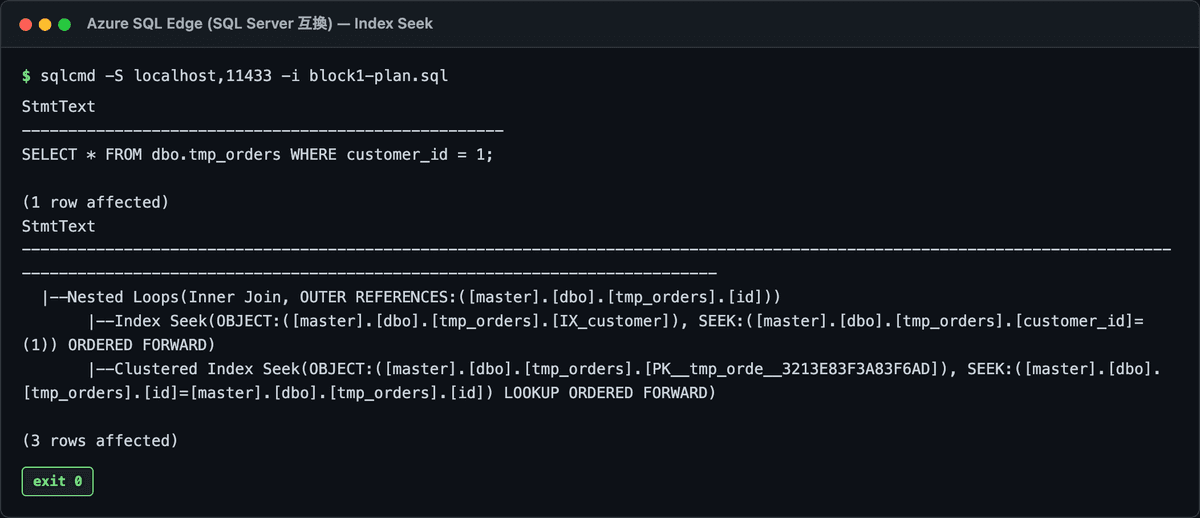
出てる構造は3段です。
|--Nested Loops(Inner Join, OUTER REFERENCES:([id]))
|--Index Seek(OBJECT:([IX_customer]), SEEK:([customer_id]=(1)))
|--Clustered Index Seek(OBJECT:([PK__tmp_orders]), SEEK:([id]=[id])LOOKUP)
これ、業務系で滅茶苦茶よく見る形です。
- 上から2行目:
Index Seek(IX_customer)でcustomer_id=1の行が入ってるインデックスから直接idを引っ張る - 上から3行目:
Clustered Index Seek ... LOOKUPで取ってきたidを使って、元テーブルから残りの列(amount)を取りに行く - 一番上:その2つを
Nested Loopsで結合
この3段目のLOOKUPがKey Lookupです。「IX_customer」にはcustomer_idとクラスタキー(id)しか入ってないので、SELECT *でamountを取るには元テーブルにもう1回潜る必要がある。これがコストになる。
Key Lookupを消すチューニング
SELECT *をSELECT customer_id, idに絞ると、IX_customerだけで完結するのでKey Lookupが消えます。もしくはCREATE INDEX IX_customer ON dbo.tmp_orders(customer_id)INCLUDE(amount);という被覆インデックスを作ってamountも含めると、同じく消える。
これ、知ってるだけで現場で「あ、こいつ実行計画読めるな」ってなるやつです!!
ハンズオン#2 — Clustered Index Scanが出るケース
逆にインデックス無し列で絞った場合がこちら。
IF OBJECT_ID('dbo.tmp_products','U')IS NOT NULL DROP TABLE dbo.tmp_products;
CREATE TABLE dbo.tmp_products (id INT IDENTITY PRIMARY KEY, name NVARCHAR(50), price INT);
INSERT INTO dbo.tmp_products (name, price)VALUES
(N'apple', 100),(N'banana', 200),(N'cherry', 300),(N'durian', 400);
SET SHOWPLAN_TEXT ON;
GO
SELECT * FROM dbo.tmp_products WHERE name = N'apple';
GO
SET SHOWPLAN_TEXT OFF;
GO
実行結果がこちら。
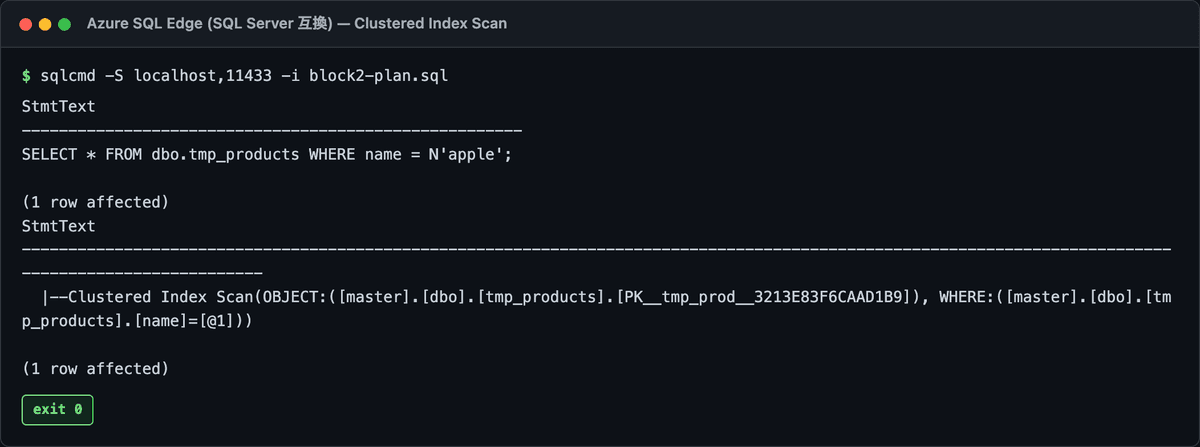
|--Clustered Index Scan(OBJECT:([PK__tmp_products]), WHERE:([name]=[@1]))
ここで業務SEがよく詰まるポイントがあります。
「Table Scanって書いてある記事多いけど、俺の実行計画にはClustered Index Scanとしか出ない…??」
これ、ハマりポイントなんですけど、SQL Server 2008以降はPRIMARY KEYが自動的にClustered Indexを作るので、(Heapテーブル以外は)Table Scanという表記は出ません。代わりにClustered Index Scanと表示される。
意味的にはほぼ一緒で、「全行スキャンしてる」という事実は同じ。旧版の解説記事を見て「Table Scanを探してたのに無い…」と混乱するのは、ここが原因です。
ちなみにWHERE:([name]=[@1])の[@1]はパラメータ自動置換 (auto parameterization)。同じクエリの再実行時にプランキャッシュが効くようにしてくれてるSQL Serverの親切機能です。
最初に見る5箇所
ここからが今回の本題。業務SEが実行計画を見た時に最初に確認する5箇所を順番に並べます。
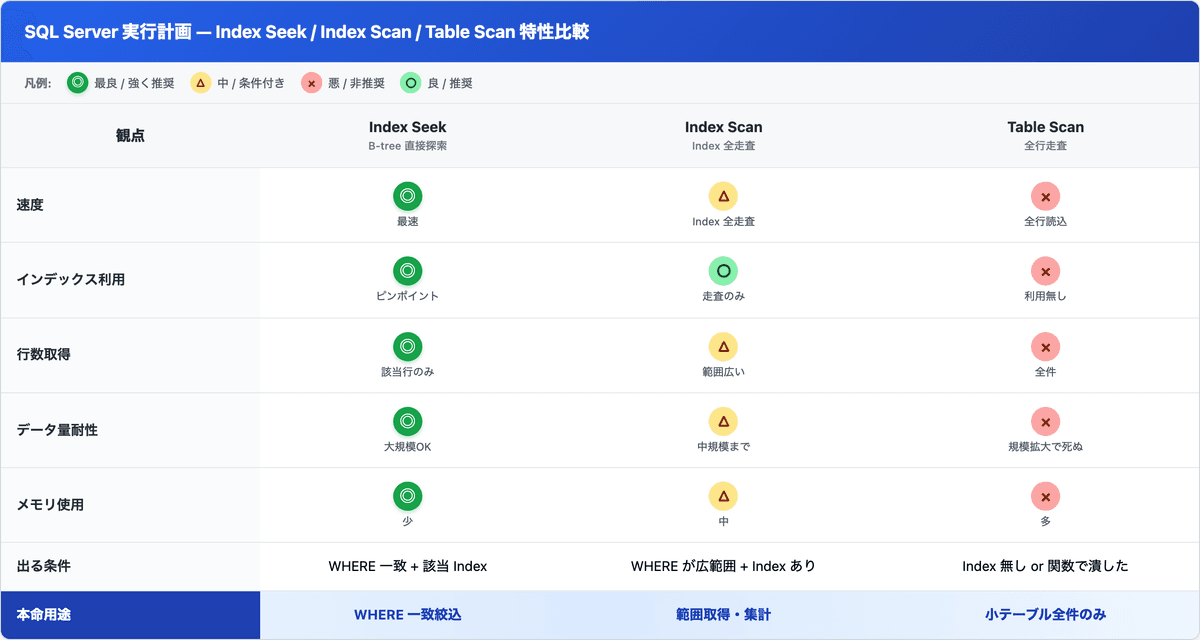
① Index Seek vs Clustered Index Scan vs Table Scan
これが大原則。Seekなら速い、Scanなら全件走査で遅い。
3者の特性をマトリクスで並べたのが下の表です。
② Estimated rowsとActual rowsの乖離
SET STATISTICS PROFILE ONで実行すると、各演算子のEstimatedとActualの行数がこんな感じで両方出ます。
SET STATISTICS PROFILE ON;
SELECT * FROM dbo.tmp_orders WHERE customer_id = 1;
SET STATISTICS PROFILE OFF;
ここでEstimated 100、Actual 10000、みたいに2桁以上ズレている演算子があれば、統計情報が腐ってる確率が高い。
③演算子のコスト割合(Cost%)
SET STATISTICS XML ONで出るXMLに各演算子のCost%が入ってます。全体の80%以上を占める演算子が「真犯人」。そこを潰すのが最短ルート。
④ Sort / Hash Matchの登場
SortやHash Match (Aggregate)が出てきたら、メモリで並べ替えやハッシュ集計してる証拠。大量データだとtempdbに溢れるので地獄を見ます。
ORDER BYを外せる場面なら外す、もしくはORDER BYの列にインデックスを張る、が定石。
⑤ Key Lookupの有無
さっきハンズオン#1で見たやつ。Index Seekの後にLOOKUPが出てれば、必要列を取りに2度手間してる証拠。INCLUDE付きインデックスかSELECT列を絞るで消えます。
ハマりポイント(オプティマイザが裏切る理由)
ここまで「Index作れば速い」みたいな雰囲気で書いてきましたが、そうじゃないケースが現場で結構あります。
①件数が少なすぎるとIndexを使ってくれない
これ、さっきのハンズオン#1で実は仕込みがあって、「5件しか入れないとIndex SeekじゃなくClustered Index Scanになる」んです。
オプティマイザは賢くて、「全件スキャンしても5行しか読まないなら、Indexジャンプするコストの方が高い」と判定する。だから1万件投入してやっとIndex Seekが出る形にしました。
開発環境で「Index作ったのに使ってくれない…??」となるのは、たいがいテストデータが少なすぎるのが原因。本番想定のデータ量で検証するのが大事。
②統計情報が古い
UPDATE STATISTICSテーブル名;で更新できます。自動更新もデフォルトONですが、大量INSERT/UPDATE直後は手動で叩いた方が確実。
俺もこれで、ある日「夜間バッチで30倍遅くなった」と呼び出されて、統計情報更新したら直った、という事故があります。朝の3時に対応した記憶、まだ残ってます。
③パラメータスニッフィング
ストアドプロシージャの初回コンパイル時のパラメータ値で組まれたプランが、別の値で使われた時に効かないやつ。
OPTION (RECOMPILE)で都度コンパイル、もしくはOPTION (OPTIMIZE FOR UNKNOWN)で典型値用プランに固定、が対処の定番です。
④ WHERE列を関数で潰してる
-- ✗ Index効かない
WHERE CONVERT(VARCHAR, created_at, 23)= '2026-05-15'
-- ✓ Index効く
WHERE created_at >= '2026-05-15' AND created_at < '2026-05-16'
WHEREの左辺に関数をかけると、Indexが無視されてScanに倒れる。これは古典的な落とし穴です。
まとめ
実行計画の入口はSHOWPLAN_TEXTで十分。グラフィカル無しで読めます。
見るのは5箇所:
- Seek / Scanの種別
- EstimatedとActualの乖離
- コスト%
- Sort / Hash Matchの登場
- Key Lookupの有無
これで遅いSQLの80%はいい感じに1次切り分けできるようになります。残りの20% (パラスニ・統計情報・複合インデックス順序)はDBAに渡す時に「ここまでは見たんですけど…」と材料を渡せる業務SEになれば、ぶっちゃけ現場での信用は段違いに変わります。これ、効きます!!
動作確認メモ:今回のスクリプトはAzure SQL Edge (SQL Server 2019互換)containerで全部実走済。SHOWPLAN_TEXTはbatchの唯一のstatementである必要があるため、setupとGOで区切る点だけ注意。SHOWPLAN_TEXTは読み取り権限のあるユーザーなら本番でも安全に取れます(クエリ自体は実行されない)。
よくある質問
Q1.実行計画ってグラフィカル(SSMS)じゃないと読めないんですか?

A. SET SHOWPLAN_TEXT ONでテキスト形式が取れます。sqlcmd / Azure Data Studio / VS Code SQL拡張、ぜんぶで読めます。むしろテキスト形式の方がdiffやGitで履歴管理しやすいという利点もあります。業務系のDBAレビューでテキストの方が好まれる現場もあるくらい。
Q2. Index Seekが出てるのに遅いんですが
A. Key Lookupが走ってる可能性が高い。SELECT *を必要列だけに絞るか、CREATE INDEX ... INCLUDE(必要列)で被覆インデックスを作ると消えます。ハンズオン#1で見たLOOKUP ORDERED FORWARDのことです。
Q3. EstimatedとActualが大きく違うのは何が原因ですか?
A.統計情報が古いのが最多。UPDATE STATISTICSテーブル名;で更新するとほぼ揃います。それでも乖離するならパラメータスニッフィングを疑う流れ。ストアドならOPTION (RECOMPILE)を試すのが定石です。
関連記事


以上!
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。 現職は SEO 直轄部の AI アドバイザー兼 PL、 副業で中小 SIer の CTO。 SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」 の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る



