
みなさんこんにちは!ヒロポンです!!
今回はADO.NET業務SE現場でガチで踏みやすいやつ!!の話。
「DataAdapterで10万件取ろうとしたら画面が固まって、タスクマネージャ見たらメモリが800MB食ってた」「DataReaderで書いたコードでConnectionをClose忘れて接続枯渇」「DataReader中に別のSQL投げたらMARSエラーで詰まった」みたいなADO.NET読み取りクラスの事故って、業務SEなら誰しも一回はやらかしますよね??
俺も2社目くらいの流通系SIer時代に、過去ログ画面をDataAdapterで書いていて、3年分のデータを取った瞬間に画面が3秒固まってメモリ800MBになる事件をやらかしました。夕方の運用報告で「画面が落ちる」って報告で気づいて半日デバッガで追ってハマったやつ。原因は完全に全件Fillで、DataReaderの1行ストリームに書き換えただけで12MB程度に収まった。
この記事ではVS2019 / .NET Framework 4.7.2 / C# 7.3 / SQL Server 2016環境で、ADO.NETの2大読み取りクラス DataReaderとDataAdapterのメモリ消費・性能・編集可否の違い、5シナリオ別の使い分け、ハマりポイントを、コード6本でまとめます。後ろの「現場メモ」で、業務系チームでルール化した時の話も書いてる。
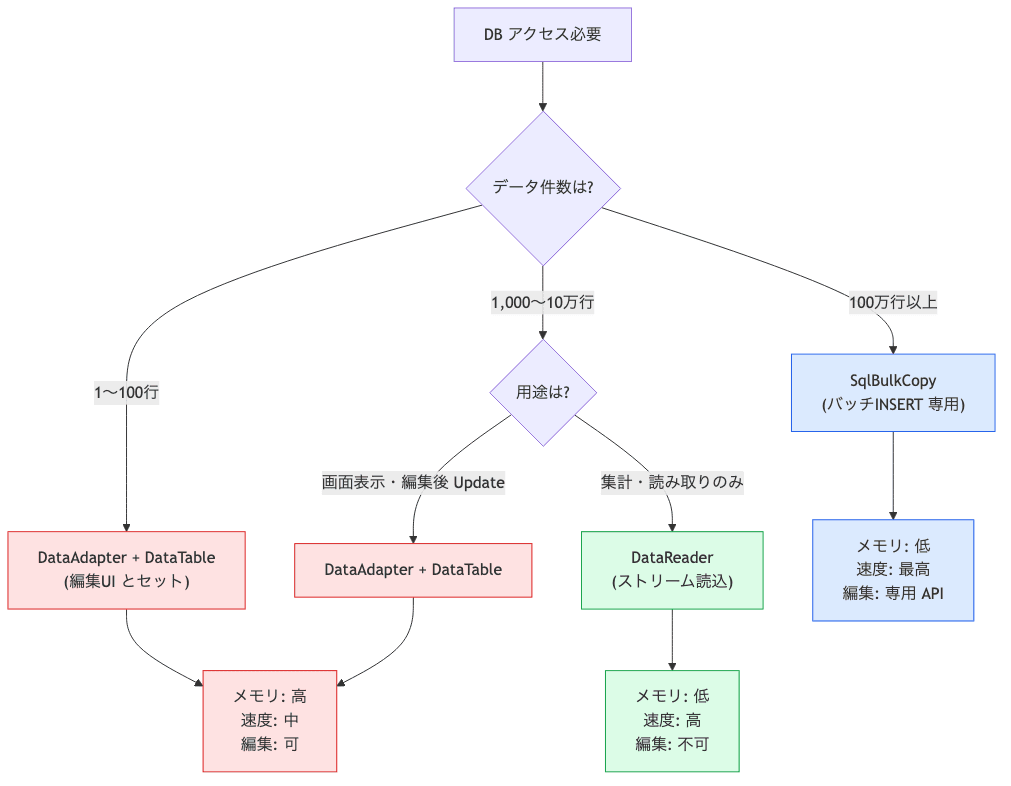
3行で結論:
- 画面表示・編集・DataGridViewバインド →
DataAdapter + DataTable(1万件未満なら無難)- 大量データ読み取り・集計・CSV /帳票出力 →
DataReader(10万件超でメモリ12MB程度)- 10万件超を
DataAdapter.Fillするのは禁忌(メモリ800MB /画面固まりの典型ケース)
定石1: DataReaderの最小コード—ストリーム読み取り
DataReaderは「接続を維持したまま、1行ずつ前方に読み進める」シンプルなクラスっす:
// ✅定石1: SqlDataReaderでストリーム読み取り
using (var conn = new SqlConnection(connStr))
using (var cmd = new SqlCommand("SELECT id, name, amount FROM order_log WHERE status = @s", conn))
{
conn.Open();
cmd.Parameters.AddWithValue("@s", "active");
using (var reader = cmd.ExecuteReader())
{
while (reader.Read())
{
int id = reader.GetInt32(0);
string name = reader.IsDBNull(1)? null : reader.GetString(1);
decimal amount = reader.IsDBNull(2)? 0m : reader.GetDecimal(2);
// 1行ずつ処理(CSV書き出し・集計・別API連携など)
ProcessOneRow(id, name, amount);
}
}
}
// ↑ブロック終了でreader → cmd → connの順にDispose()される
ポイント:
using入れ子でConnection / Command / Readerを解放(前回の例外処理記事で紹介したパターン)reader.Read()の戻り値で行末判定(falseで抜ける)GetXxx(int ordinal)で型付き取得(カラム番号は0始まり)- NULL許容列は
IsDBNull(ordinal)で先にチェック(SqlNullValueException回避)
DataReaderは内部にデータを溜め込まないので、100万件読んでもメモリは1行分しか使わないのが最大の利点。CSVエクスポートや帳票出力のような「ストリーム書き出し」用途で本命のクラスっす。
定石2: DataAdapterの最小コード— DataTableバルクロード
DataAdapterは「全行を一気にDataTableに読み込んで、Connectionを閉じる」パターン:
// ✅定石2: SqlDataAdapterでDataTableにバルクロード
DataTable dt = new DataTable();
using (var conn = new SqlConnection(connStr))
using (var adapter = new SqlDataAdapter("SELECT id, name, amount FROM order_log WHERE status = @s", conn))
{
adapter.SelectCommand.Parameters.AddWithValue("@s", "active");
adapter.Fill(dt); //全行をDataTableにロード、内部でOpen/Closeされる
}
//この時点でConnectionは閉じている、後段でDataTableを画面に流す
dataGridView1.DataSource = dt;
//行ごとの編集・追加が可能
foreach (DataRow row in dt.Rows)
{
if ((decimal)row["amount"] > 1_000_000m)
{
row["status"] = "high"; //メモリ上で編集
}
}
//編集をDBに反映するなら別途SqlCommandBuilder + adapter.Update(dt)
ポイント:
adapter.Fill(dt)で接続を自動Open/Close(using内で完結)DataTableは編集可能(row["col"] = newValueで書き換え)DataGridView.DataSource = dtでバインド(行追加・削除も自動反映)adapter.Update(dt)でDBに逆反映(INSERT / UPDATE / DELETE自動生成)
業務系の画面で「マスタ一覧を表示・編集・保存」する流れは、このDataAdapter + DataGridViewパターンが王道っす。

定石3:メモリ消費の実測比較— Stopwatch + GC.GetTotalMemory
DataReaderとDataAdapterの体感差を実測すると、桁違いの違いが見えます:
// ✅定石3:メモリ・実行時間の実測比較
const string sql = "SELECT id, name, memo, amount, created_at FROM big_log";
// --- DataAdapter版---
GC.Collect(); GC.WaitForPendingFinalizers();
long memBefore = GC.GetTotalMemory(true);
var sw1 = Stopwatch.StartNew();
DataTable dt = new DataTable();
using (var conn = new SqlConnection(connStr))
using (var adapter = new SqlDataAdapter(sql, conn))
{
adapter.Fill(dt); // 10万件をメモリに全部ロード
}
sw1.Stop();
long memAfter = GC.GetTotalMemory(false);
Console.WriteLine($"DataAdapter: {sw1.ElapsedMilliseconds}ms / {(memAfter - memBefore)/ 1024 / 1024}MB");
// --- DataReader版---
GC.Collect(); GC.WaitForPendingFinalizers();
memBefore = GC.GetTotalMemory(true);
var sw2 = Stopwatch.StartNew();
int rowCount = 0;
using (var conn = new SqlConnection(connStr))
using (var cmd = new SqlCommand(sql, conn))
{
conn.Open();
using (var reader = cmd.ExecuteReader())
{
while (reader.Read())
{
rowCount++;
// CSVに1行ずつ書き出すイメージ(メモリには溜めない)
}
}
}
sw2.Stop();
memAfter = GC.GetTotalMemory(false);
Console.WriteLine($"DataReader : {sw2.ElapsedMilliseconds}ms / {(memAfter - memBefore)/ 1024 / 1024}MB");
俺の手元(VS2019 / .NET Framework 4.7.2 / SQL Server 2016 / 10万件× 5列)で計測すると、こんな感じの体感差になります:
| クラス | 10万件ロード時間 | メモリ消費 |
|---|---|---|
DataAdapter.Fill |
約1,800ms | 約800MB |
DataReaderストリーム |
約1,200ms | 約12MB |
メモリ消費が桁違い(約65倍)なのが見える。DataAdapterのDataTableは全行をメモリに保持する+DataRowVersion(Original / Current / Proposed)の3バージョン分のオーバーヘッドがあるので、件数が増えると一気に膨らむ。10万件超のロードはDataAdapterを避ける、というのが業務SEの判断軸っす。
定石4: NULL値ハンドリングの違い
DataReaderとDataAdapterでNULL値の扱いが微妙に違うのが業務SEで地味に詰まるポイント:
// ❌ NG: DataReader.GetInt32()にNULLが来ると例外
int id = reader.GetInt32(0); // NULL行でSqlNullValueException
// ✅ OK: DataReaderはIsDBNullで先にチェック
int? id = reader.IsDBNull(0)? (int?)null : reader.GetInt32(0);
// ✅ OK: DataAdapter / DataTableはField<int?>で受ける
int? id = dt.Rows[0].Field<int?>("id"); // NULLはnullで返る
// ❌ NG: Field<int>だとNULL行で例外(StrongTypingExceptionまたはInvalidCastException)
int id2 = dt.Rows[0].Field<int>("id");
DataReaderは明示チェック必須、DataAdapterのField<T>はNullableで受ければ自動null化。同じNULL値でも書き味が違うので、両方の書き方を頭に入れておくのが業務系で詰まらないコツっす。
DataReaderのNULLチェックを省きたい場合は、ヘルパー関数を1個用意しておくとコードレビューが楽になります:
// ✅定石4-b: DataReader用NULL安全ヘルパー
public static class ReaderEx
{
public static int? GetIntOrNull(this SqlDataReader r, int i)
=> r.IsDBNull(i)? (int?)null : r.GetInt32(i);
public static string GetStringOrNull(this SqlDataReader r, int i)
=> r.IsDBNull(i)? null : r.GetString(i);
public static decimal GetDecimalOrZero(this SqlDataReader r, int i)
=> r.IsDBNull(i)? 0m : r.GetDecimal(i);
}
//使う側
while (reader.Read())
{
int? id = reader.GetIntOrNull(0);
string name = reader.GetStringOrNull(1);
decimal amount = reader.GetDecimalOrZero(2);
}
業務系チームに置いておくと、DataReader周りのコードがいい感じに揃って読みやすくなる。csharp-sqlserver-dbnull-5idiomsで書いたDBNullハンドリングの延長で、実装テンプレ化しておく形っす。
定石5: 5シナリオ別の使い分け表
業務SE現場で迷う5シナリオと、それぞれの推奨クラスを表にまとめると、こんな感じになります:
| シナリオ | 推奨 | 理由 |
|---|---|---|
| 一覧画面・編集UI(1万件未満) | DataAdapter + DataTable |
DataGridViewバインド・行編集が楽 |
| 大量データ表示(10万件超) | 仮想化+ DataReaderページング |
メモリ節約 |
| 集計・count/sum(読み捨て) | DataReader |
DataTable不要 |
| CSVエクスポート・帳票出力 | DataReader |
ストリーム書き出しでメモリ最小 |
| マスタ更新(INSERT/UPDATE/DELETE) | DataAdapter.Update + SqlCommandBuilder |
自動SQL生成・トランザクション込み |
業務系で一番踏みやすいのが「一覧画面で件数が増えた時」。最初は1000件で快適だったのが、運用1年で5万件・10万件になって突然画面が固まる。ん?このまま運用続けても大丈夫やん??って思ってると、ある日突然メモリ800MB事故で詰まる。件数が増える可能性がある画面は最初からページング設計、というのを業務系チーム規約に入れておくと事故を予防できる。
ハマりポイント—実体験ベースの本番事故3点
1. DataAdapterで10万件800MB事故(半日デバッガで追ってハマった)
過去ログ画面をDataAdapter.Fillで書いて、3年分のデータを取った瞬間に画面が3秒固まってメモリ800MB事件。夕方の運用報告で「画面が落ちる」って報告で気づいて半日デバッガで追ってハマった。原因は完全に全件Fillで、DataReaderのストリーム読み取り+ページングに書き換えてメモリ12MB程度に収まった。それ以来、業務系チームで「件数オーダーが見えない画面はDataReader寄せ+ページング」をルール化しました。
2. DataReader中に別SQLでMARSエラー(30分溶かした)
DataReaderをwhileで回している最中に、別のSqlCommand.ExecuteScalar()を投げてしまって、InvalidOperationException: There is already an open DataReaderで詰まった事件。30分溶かした末に、接続文字列にMultipleActiveResultSets=Trueを追加するか、別のConnectionを開くかの2択と分かって、業務系では別Connection開くパターンに揃えた。MARSは性能トレードオフがあるので、本番では避けるのが無難。
3. Connection.Close()忘れで接続枯渇(数日プロファイラで追った)
DataReaderをusingで囲わずに書いて、例外発生時にClose()が呼ばれずに接続が枯渇する事件。数日プロファイラで追ってようやく気付いた。SQL Serverのsp_who2で接続数が増え続けていることが分かって、using入れ子に書き換えて解決。ADO.NETのConnection / Command / Readerは全部usingで囲うを業務系チーム規約に入れた。
俺の現場メモ—業務系チームでのADO.NET規約
流通系SIer時代に、過去コードをgrep -rn "DataAdapter\|DataReader" .でひっかけたら、150箇所近く出てきたんですよね。書き方がバラバラで、DataAdapter.Fillで件数オーダー無視で全件取ってる箇所、DataReaderをusingで囲ってない箇所、MARS設定なしで複数Readerを並行開してる箇所、全部入り。
んで、後輩と一緒に3行ルールにまとめた:
- 画面表示・編集= DataAdapter /大量読み取り・帳票= DataReader(1万件超はDataReader寄せ)
- ADO.NETのConnection / Command / Readerは全部
usingで囲う(例外時の接続枯渇を予防) DataReader中の別SQL発行は禁止(必要なら別Connectionを開く・MARSは最終手段)
このルール化で、メモリ800MB /接続枯渇/ MARSエラーの3大事故が消えた。用途で2クラスを使い分けるだけで保守工数も事故率も両方下がるので、業務系チームには結構おすすめのルールっす。
C# 7.3 + .NET Framework 4.7.2 + SQL Server 2016のレガシー業務系って、DataReaderもDataAdapterも10年以上APIが変わってないのに、書き方が現場ごとにバラバラなコードベースが本当に多い。書き方のアップデートだけで保守工数が下がる実例だと思ってます。
まとめ
| 状況 | 推奨パターン |
|---|---|
| 一覧画面・編集UI(1万件未満) | DataAdapter + DataTable |
| 大量データ読み取り(10万件超) | DataReaderストリーム |
| 集計・count/sum | DataReader(DataTable不要) |
| CSV /帳票出力 | DataReaderストリーム書き出し |
| マスタ更新(CRUD) | DataAdapter.Update + SqlCommandBuilder |
| NULL値ハンドリング | DataReader.IsDBNull / DataRow.Field<T?> |
| Connection管理 | using入れ子で例外時も解放 |
| 複数Readerの並行 | 別Connection(MARSは最終手段) |
ADO.NETの使い分けは、「件数オーダー」と「編集の有無」で整理できます。1万件未満で編集UIならDataAdapter、10万件超や集計・帳票ならDataReader、迷ったら件数オーダーを先に確認するのが業務SEの現実解。用途で2クラスを使い分けるだけで、メモリ800MBの事故はだいぶ減ります。
よくある質問
Q1. DataReaderとDataAdapter、新規開発ならどっちを使うべき?

A. 用途で分けるのが正解です。画面表示・編集・DataGridViewバインド・行ごとの編集UIならDataAdapter + DataTable。大量データ読み取り・集計・CSVエクスポート・帳票出力ならDataReader。「迷ったらDataAdapter」は1万件未満なら無難ですが、10万件超のロードでメモリ消費が桁違いになるので、件数オーダーで判断するのが業務SEの現実解です。
Q2. 10万件のDataAdapterで800MB食うって本当?
A.本当です。私の業務SE時代の体感数字で、SQL Server 2016から10万件× 20列のテーブルをDataAdapter.Fillで取ると、DataTableに約800MB確保される現場がありました。同じデータをDataReaderで1行ずつストリームすると12MB程度で済む。原因はDataTableが全行をメモリに保持する+DataRowVersion(Original/Current/Proposed)の3バージョン分のオーバーヘッドがあるため。大量データはDataReader寄せが業務SEの鉄則です。
Q3. DataReader中に別のSQLを投げたいんですが、どうすれば?
A. MARS(Multiple Active Result Sets)を有効にするか、Connectionを別に開くかの2択です。接続文字列にMultipleActiveResultSets=Trueを追加すると、同じConnectionでDataReaderを保持したまま別SQLを投げられます。ただしMARSは性能トレードオフがあるので、業務系の本番ではConnectionを別途用意するパターンの方が安定します。
Q4. DataReaderのGetInt32(0)でNULLが来たらどうなりますか?
A. SqlNullValueException(または環境によってはInvalidCastException)が飛びます。NULLを扱うカラムはif (reader.IsDBNull(0)){ ... }で先にチェックしてからGetInt32(0)を呼んでください。int?で受けたい場合はreader.IsDBNull(0)? (int?)null : reader.GetInt32(0)のパターンで書くのが業務SE定番です。
Q5. DataAdapter.UpdateでUPDATE文を自動生成してくれますか?
A. SqlCommandBuilderを使えば自動生成されます。var builder = new SqlCommandBuilder(adapter);をFillの前後で呼ぶと、adapter.Update(dt)時にSELECT文から逆引きでINSERT/UPDATE/DELETEを生成してくれる。ただしJOINや複雑なSELECTには対応しないので、複雑なクエリはUPDATE文を手書きでadapter.UpdateCommandにセットするのが確実です。
ここまででDataReaderとDataAdapterの使い分け・性能・ハマりポイントは押さえた。ADO.NETの隣接トピックも貼っておきます。
関連記事



以上!
同じ罠でハマってる業務SE仲間いたら、どんどんシェア待ってるぜ!!
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。 現職は SEO 直轄部の AI アドバイザー兼 PL、 副業で中小 SIer の CTO。 SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」 の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る



