
みなさんこんにちは!ヒロポンです!
検索画面で打ち込まれた名前を、DBのデータと突き合わせる。いわゆる名寄せってやつですね。
if (input == name) で書いた。合ってるはずのデータが、なぜかマッチしない。大文字小文字が違うだけ、全角と半角が違うだけで、まるっと別物扱い。あれ、合ってるのになんで??ってやつ。c# 文字列 比較 でつまずく、定番の入口です。
ここで「== がポンコツ」と決めつけると、半分は損します。== はちゃんと仕事してる。ただ、何を「同じ」とみなすかが、こっちの想定とズレてるだけ。それだけなんですよね。
今回は、== と Equals と StringComparison がそれぞれ何を比べているのかを、仕組みから積み上げます。腑に落ちれば、名寄せも突合も迷わなくなる。コードは Docker 上の .NET で実機確認済みです。
忙しい人向けに最初にまとめ
==は序数(ordinal)比較 — 文字コードをそのまま比べる。大文字小文字・全角半角を区別し、カルチャは見ない。- 大文字小文字を無視したいなら
StringComparisonを明示 —string.Equals(a, b, StringComparison.OrdinalIgnoreCase)。ToLower()で揃えるのはカルチャ事故のもと。 - null を含むなら静的
string.Equals—a.Equals(b)は a が null で落ちる。string.Equals(a, b)なら落ちない。 - 結論: 迷ったら明示的に
StringComparisonを渡す。暗黙に任せない。
そもそも、== は文字列の「何」を比べているのか
まず土台から。C# で文字列を == で比べると、内部では String.Equals の序数(ordinal)比較が走ります。
序数比較ってのは、文字を1文字ずつ、その文字コードの数値で比べる方式。'A' は 65、'a' は 97。コードが違えば別の文字です。だから "ABC" == "abc" は false になる。
Console.WriteLine("ABC" == "abc"); // False(大文字小文字を区別)
Console.WriteLine("ABC" == "ABC"); // False(全角と半角は別のコード)
これは == が壊れてるわけじゃない。「コードが完全一致するか」を、忠実に、速く判定してるだけなんです。むしろ突合やキー比較なら、この厳密さこそ正解。
ここまでで分かったこと:
==は文字コードの厳密一致(ordinal)。大文字小文字も全角半角も「違う文字」として扱う。
なぜ「カルチャ」で比較結果が変わるのか
ここが、多くの人がモヤッとする所。同じ文字列比較なのに、「ordinal(序数)」と「culture(カルチャ)」という2つの世界が同居してるんですよね。
序数比較は、さっきの通り文字コードで機械的に比べる。対するカルチャ比較は、「その言語圏で人間がどう同じとみなすか」で比べます。言語によっては、アクセント記号付きの文字を同じ扱いにしたり、並び順がガラッと変わったりする。
有名なのがトルコ語の I 問題。英語だと I の小文字は i ですが、トルコ語では I の小文字が点のない ı(ドットレス i)になる。カルチャを意識せず大文字小文字を揃えると、トルコ語環境で "FILE" と "file" が一致しなくなる、なんて事故が起きます。
using System.Globalization;
var tr = new CultureInfo("tr-TR");
// ToLower でカルチャ任せにすると、トルコ語環境で I が ı になって不一致
Console.WriteLine("FILE".ToLower(tr) == "file"); // False(I→ı)
// StringComparison.OrdinalIgnoreCase なら、カルチャに依存せず一致
Console.WriteLine(string.Equals("FILE", "file", StringComparison.OrdinalIgnoreCase)); // True
この 'fıle'(ドットレス i)化、.NET Framework 4.7.2 でも .NET 8+ でも同じように起きます。古い環境だから、新しいから、って話じゃない。
ん?なんで世界が2つもあるん??ってなりますよね。理由は単純で、用途が違うから。人間に見せる並べ替え(ソート)はカルチャ比較が自然。でも、システム内部の突合・キー・識別子は、環境のカルチャに左右されない序数比較が安全。この2つを混ぜると事故ります。
ここまでで分かったこと: 比較には ordinal(機械的)と culture(人間的)の2世界がある。内部処理は ordinal、表示順は culture、が基本。
場面1: 大文字小文字を無視して比べたい
「コードが大文字でも小文字でも同じ扱いにしたい」。名寄せでいちばん多いやつです。
ここで ToLower() や ToUpper() で揃えてから == する人が多い。けど、さっきのトルコ語問題のリスクを背負うことになる。素直なのは、StringComparison.OrdinalIgnoreCase を明示することです。
// NG寄り: ToLower で揃える(カルチャ事故 + 余計な文字列生成)
if (input.ToLower() == name.ToLower()) { /* ... */ }
// OK: StringComparison を明示。カルチャに依存せず大文字小文字だけ無視
if (string.Equals(input, name, StringComparison.OrdinalIgnoreCase)) { /* ... */ }
OrdinalIgnoreCase は「序数比較だけど大文字小文字は無視」。突合・キー・ファイル名・コードの照合は、だいたいこれでいい感じに足ります。
ここまでで分かったこと: 大文字小文字を無視する突合は
OrdinalIgnoreCase。ToLower()揃えは避ける。
場面2: 並べ替えはカルチャ、突合は序数で使い分ける
「じゃあ全部 Ordinal でいいの?」というと、そうでもないんです。人間に見せる並び順はカルチャ比較のほうが自然。
// 突合・キー比較: 序数(環境に左右されない)
bool same = string.Equals(a, b, StringComparison.Ordinal);
// 表示用の並べ替え: 現在のカルチャ(人間の感覚に近い順)
var sorted = list.OrderBy(x => x, StringComparer.CurrentCulture);
判断の軸はシンプルです。「コンピュータが識別するための比較」か「人間に見せるための並べ替え」か。前者は Ordinal 系、後者は CurrentCulture 系。ここを意識するだけで、9割の文字列比較はこんな感じで迷わなくなります。
ここまでで分かったこと: 識別・突合は Ordinal、表示の並べ替えは CurrentCulture。
場面3: null を含む比較は静的 string.Equals で受ける
最後は null。業務データは null だらけです。ここで素朴に書くと、落ちます。
string a = null;
// NG: a が null だと NullReferenceException
// if (a.Equals(name)) { ... }
// OK: 静的 string.Equals はどちらが null でも落ちない
if (string.Equals(a, name, StringComparison.OrdinalIgnoreCase)) { /* ... */ }
// 空文字も一緒に弾きたいなら
if (!string.IsNullOrEmpty(a)) { /* ... */ }
肝は、インスタンスメソッドの a.Equals(...) は a が null だと例外になること。静的な string.Equals(a, b) なら、内部で null チェックしてくれるので落ちません。null が来うる業務データは、静的版で受ける。これが安全です。
ここまでで分かったこと: null を含む比較は静的
string.Equals。a.Equalsはインスタンスが null だと落ちる。
使い分け早見表
ここまでの概念を1枚に。突合の現場で「どれ使う?」となった時の早見表です。
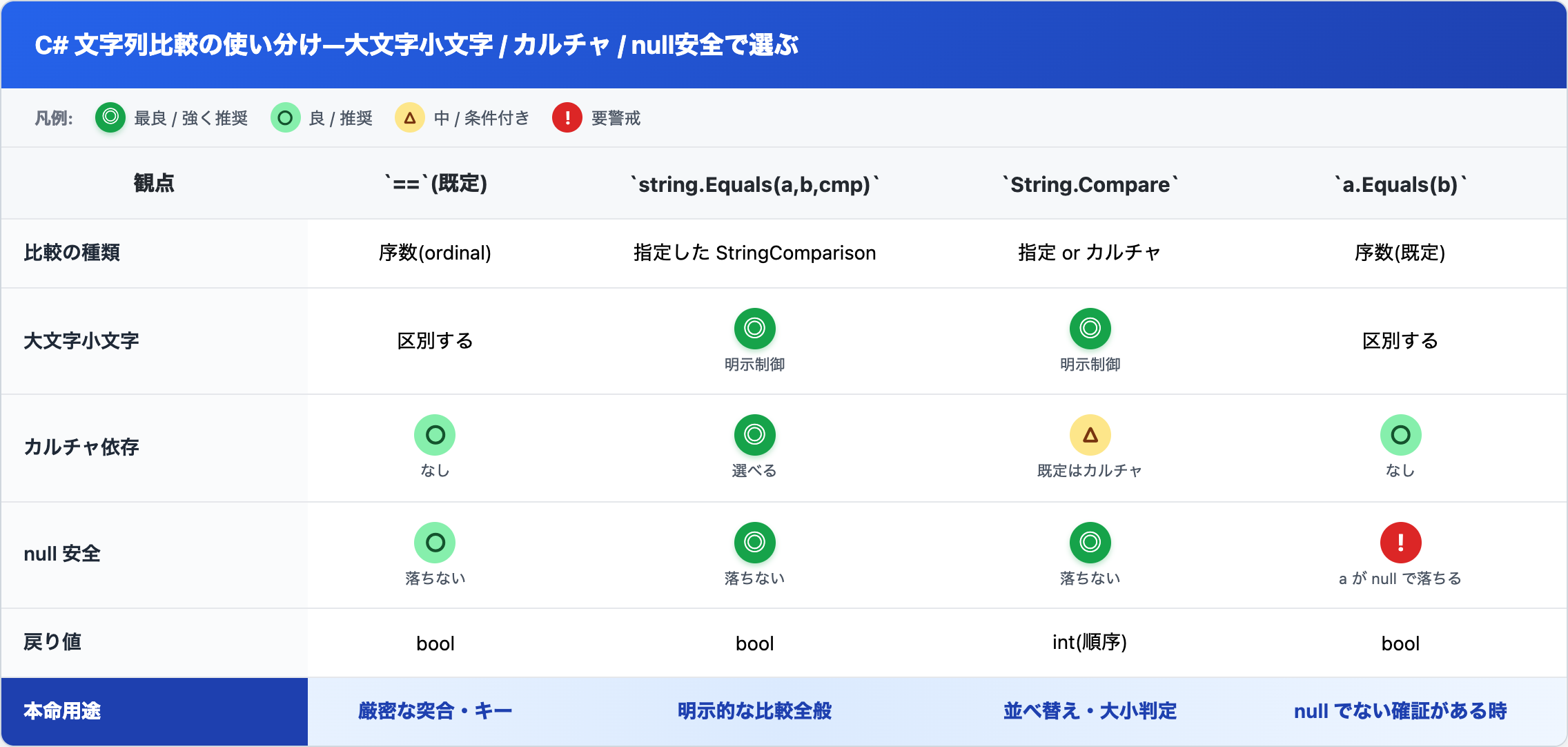
◎ 最適 / ○ 良い / △ 場合による / ! 要注意。
俺の現場ではこう使ってる
フリーで入った案件で、別々のシステムから流れてくる顧客名を名寄せする処理を書いたことがあります。最初は ToUpper() で揃えて ==。これでいいやろ、と。レビューで「それカルチャ事故るよ」と刺されて、OrdinalIgnoreCase に直しました。ちょっと冷や汗かいたやつです。
それ以来、文字列比較を書く時は、頭の中で2つだけ自問してる。「これは識別のため? 表示のため?」と、「null は来うる?」。この2つが決まれば、使うメソッドは自動的に決まる。識別なら Ordinal 系、null が来るなら静的 string.Equals。
慣れてくると、== をそのまま書く場面のほうが少なくなります。明示的に StringComparison を渡すのが、いい感じに体へ馴染んでくるんですよね。
まとめ
C# の文字列比較がややこしく見えるのは、ordinal(機械的)と culture(人間的)という2つの世界が同居してるからです。ここさえ腑に落ちれば、迷いは消える。
==は序数比較 — 厳密な突合・キーには最適。大文字小文字も全角半角も区別する- 大文字小文字を無視するなら
StringComparison.OrdinalIgnoreCase—ToLower()揃えは避ける - 表示の並べ替えは
CurrentCulture、内部の識別はOrdinal - null を含むなら静的
string.Equals—a.Equalsは落ちる
結論はシンプルです。迷ったら、明示的に StringComparison を渡す。暗黙の既定に任せないだけで、名寄せも突合もカルチャ事故も、まとめて避けられます!!
よくある質問
Q1. == と Equals は何が違いますか?
文字列の場合、== も既定の Equals も、どちらも序数(ordinal)比較で結果は同じです。違うのは、Equals には StringComparison を渡せるオーバーロードがあること。大文字小文字やカルチャを制御したいなら Equals(または静的 string.Equals)を使います。
Q2. ToLower() で揃えて比較するのはダメですか?
動く場面は多いですが、おすすめしません。カルチャによって大文字小文字の対応が変わる(トルコ語の I など)ため、環境依存のバグを生むことがあります。比較のたびに新しい文字列を生成するので、ムダもある。StringComparison.OrdinalIgnoreCase のほうが安全で速いです。
Q3. データベースの照合順序(COLLATE)とは関係ありますか?
別物ですが、考え方は似ています。DB側の比較は照合順序(COLLATE)で決まり、C#側の比較は StringComparison で決まる。アプリとDBで大文字小文字の扱いが食い違うと名寄せがズレるので、両方の設定を意識しておくと事故が減ります。
Q4. 結局どれを使えばいいですか?
迷ったら string.Equals(a, b, StringComparison.OrdinalIgnoreCase) です。null に強く、大文字小文字を無視した突合ができて、カルチャにも左右されない。大文字小文字を区別したいなら StringComparison.Ordinal に変えるだけ。表示の並べ替えだけ CurrentCulture 系を使います。
次に読むべき記事
- C# TryParse の正解 — int / DateTime / Enum.TryParse の3つのハマり — 入力値の「変換」側。文字列比較と並んで名寄せ・突合で詰まる定番
- C# Dictionary と HashTable の使い分け — 文字列キーの辞書は StringComparer で比較方法を指定する。この記事の応用編
- C# 正規表現の業務系基本 — 入力検証5パターン — 比較の前段、入力の正規化・検証の話。全角半角の揺れもここで吸収する
- C# 文字列連結のパフォーマンス — 同じ文字列まわり。比較とセットで知っておきたい速度の話
- 「客先常駐しかない」と感じてる業務SEへ — こういう地味な基礎を1つ深掘りできると、現場での立ち位置が変わる話
以上!
執筆者
バイブス父さん — 業務 SE 7 年 (SIer 正社員 2 / フリーランス 5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SIer の正社員からフリーランスに転じ、複数のエージェント経由で案件を回してきた経験ベースで「業務 SE 視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る

コメント