
SQL Server の BULK INSERT で CSV を大量取り込み — 業務SEの最短手順とハマり
みなさんこんにちは!ヒロポンです!
「このCSV、今日中にテーブルに入れといて」。業務でよく降ってくるやつです。数万〜数十万行の CSV を、一括でドカッと。
1行ずつ INSERT 文を回す?? 無理です。遅すぎる。こういう時は BULK INSERT が一発で効きます。
ただ、コピペしてそのまま動くかというと、そうもいかない。文字コード・改行・ファイルの置き場所。このあたりで、だいたい一度はハマる。俺も最初、CSV の文字化けと「全部1行扱い」で半日溶かしかけました。あれ、地味にしんどいんですよね。
この記事では、BULK INSERT で CSV を最短で取り込む手順と、業務SEが踏みがちな4つのハマりを、コピペで動く形でまとめます。
結論: BULK INSERT で一発。ただしサーバ側パス・文字コード・改行を明示する
先に答えです。
CSV を大量に入れるなら BULK INSERT が最短。ポイントは3つ。
- ファイルは SQL Server サービスから見えるサーバ側のパスに置く(クライアントのCドライブじゃない)
- 文字コードを
CODEPAGEで明示する(UTF-8 なら65001、SJIS なら932) - 改行コードを
ROWTERMINATORで合わせる(LF なら0x0a、CRLF なら0x0d0x0a)
この3つを外すと、文字化けか「全行が1行扱い」で止まる。逆に、ここさえ合えばいい感じに一瞬です。
最短手順: コピペで動く BULK INSERT
入れ先テーブルを用意して、CSV を流し込みます。FORMAT = 'CSV' は SQL Server 2017 以降で使えます。
-- 入れ先テーブル
CREATE TABLE dbo.Members (
MemberId INT,
Name NVARCHAR(50),
Email VARCHAR(100)
);
-- CSV を一括取り込み
BULK INSERT dbo.Members
FROM 'C:\import\members.csv' -- ★ SQL Server サービスが見えるサーバ側パス
WITH (
FORMAT = 'CSV', -- 2017+。フィールドの引用符を解釈してくれる
FIRSTROW = 2, -- 1行目はヘッダなので飛ばす
CODEPAGE = '65001', -- UTF-8 (SJIS なら '932')
FIELDTERMINATOR = ',', -- 列区切り
ROWTERMINATOR = '0x0a' -- LF (CRLF なら '0x0d0x0a')
);
-- 入った件数を確認
SELECT COUNT(*) FROM dbo.Members;
実行結果:
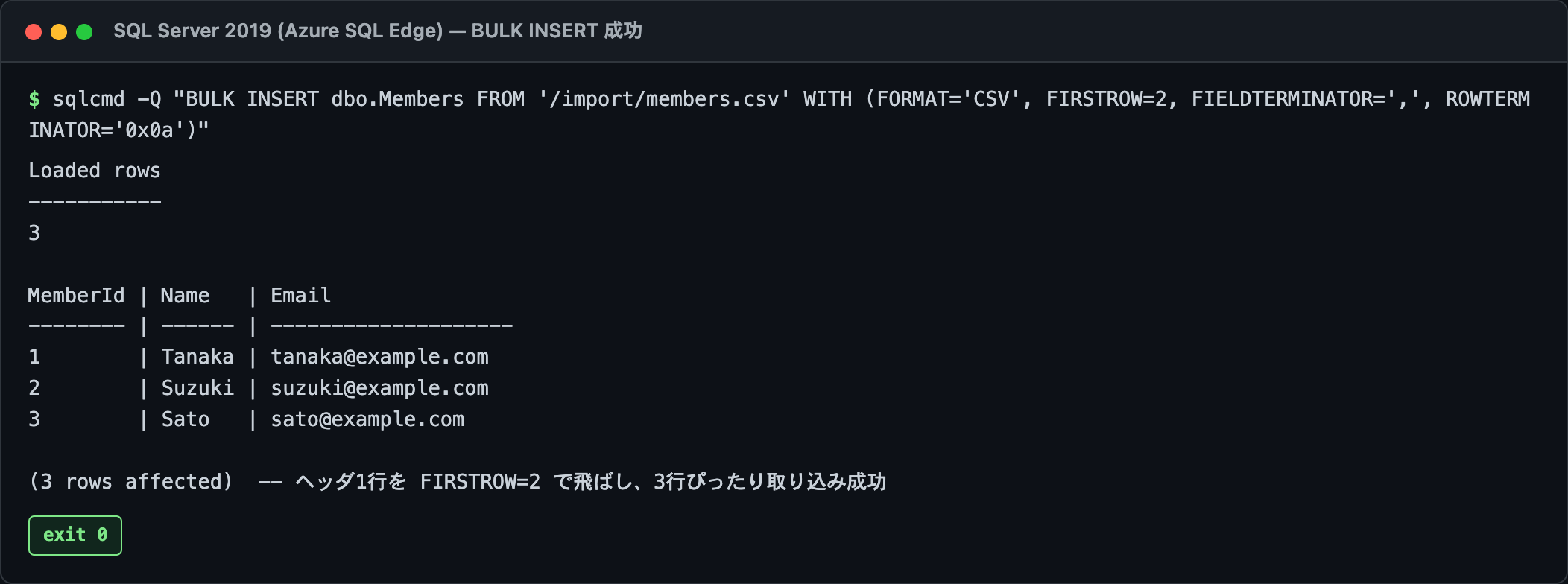
これで CSV の中身がまるごとテーブルに入ります!!FORMAT = 'CSV' を付けておくと、"田中, 太郎" みたいに値の中にカンマを含む引用符付きフィールドも、いい感じに解釈してくれます。地味だけど、これがあるのとないのとで全然ちがう。
ハマりポイント: 知らないと一度はつまずく4つ
ここからが本題かもしれません。BULK INSERT が「動かない」「変な値が入る」。原因は、だいたいこの4つに集約されます。
① 文字コード: CODEPAGE のミスと BOM 化け
CSV の文字コードと CODEPAGE が合っていないと、日本語が文字化けします。UTF-8 = 65001、Shift-JIS = 932。Excel から「CSV(コンマ区切り)」で保存すると SJIS になりがち。そこは先に確認しておきたいところです。
もう一つ、環境差が出やすいのが BOM 付き UTF-8。ファイル先頭の BOM(3バイト)が、1列目の頭に紛れることがあります。FORMAT = 'CSV'(2017以降)だと基本は処理されるんですが、古い書き方や環境によっては先頭列が化ける。保険として BOM 無しの UTF-8 で保存しておくと、環境差で詰まりません。
なお CODEPAGE は Windows 版 SQL Server の機能です。Linux 版 SQL Server や Azure SQL Edge では CODEPAGE がサポートされていないので、その環境ではファイル側をあらかじめ UTF-8 に変換してから取り込む。現場が Windows 版 SQL Server なら、上のコードのままで大丈夫です。
② 改行コード: ROWTERMINATOR のミスで全行が1行扱い
改行コードの指定ミスは、症状が派手です。
ファイルが CRLF(Windows の標準)なのに ROWTERMINATOR = '0x0a'(LF)を指定すると、各行末に \r が残って最終列の値に \r が紛れ込む。逆に、LF のファイルに '0x0d0x0a'(CRLF)を指定すると、改行が見つからず全行がまるごと1行扱いになって落ちる。これ、エラーメッセージだけ見てると原因に辿り着けないやつです。
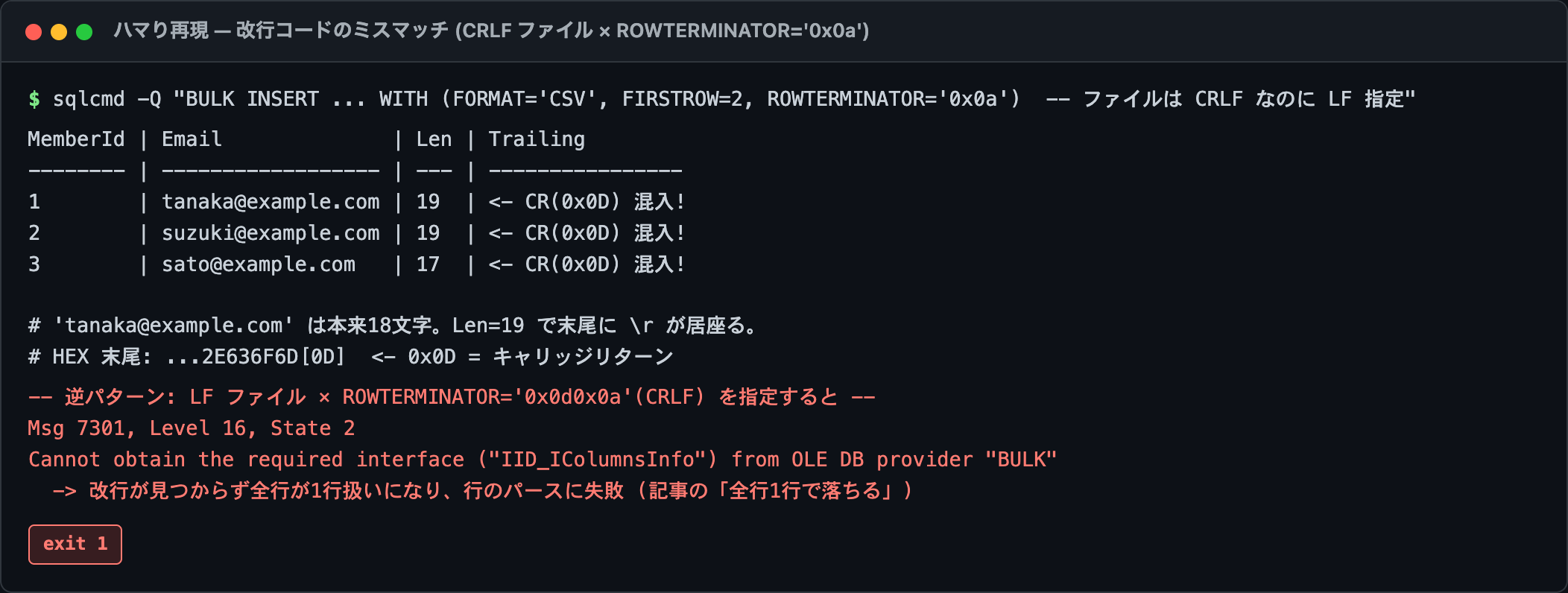
ファイルの改行が CRLF か LF かを先に確認して、ROWTERMINATOR を合わせる。これだけで防げます。
③ ファイルはサーバ側パスに置く(+権限)
これ、リモートで作業してると一度はハマります。やったことある人、いますよね?
BULK INSERT の FROM に書くパスは、あなたの手元のPCじゃなくて、SQL Server サービスが動いているサーバから見えるパスです。SSMS を自分のPCで動かしていても、'C:\import\...' が指すのはサーバの C ドライブ。ここを勘違いすると延々ハマります。
さらに、SQL Server サービスアカウントに、そのパスの読み取り権限が要る。共有フォルダ(UNC パス \\server\share\...)を使うなら、サービスアカウントに共有の権限を付ける。「ファイルが見つからない」エラーの大半は、結局これです。
④ エラー行で全部止まる: MAXERRORS / ERRORFILE
CSV に1行でも型不一致(数値列に文字が入ってる等)があると、既定では取り込み全体が止まります。数万行のうち、たった数行のゴミで全滅。なかなかつらい。
MAXERRORS で許容するエラー行数を指定して、ERRORFILE で失敗した行をファイルに吐き出します。
BULK INSERT dbo.Members
FROM 'C:\import\members.csv'
WITH (
FORMAT = 'CSV', FIRSTROW = 2, CODEPAGE = '65001',
FIELDTERMINATOR = ',', ROWTERMINATOR = '0x0a',
MAXERRORS = 10, -- 10行まではスキップして続行
ERRORFILE = 'C:\import\errors.log' -- 失敗した行をここに記録
);
これで、ゴミ行は errors.log に逃がしつつ、正常な行だけこんな感じで取り込めます。あとはログを見て直す。
もっと速く: 大量なら TABLOCK でミニマムロギング
行数が数十万〜数百万になると、トランザクションログの書き込みがボトルネックになります。ここで効くのが TABLOCK と復旧モデル。
BULK INSERT は、復旧モデルが BULK_LOGGED か SIMPLE で、対象が空テーブル等の条件を満たすと、ミニマムロギング(最小ログ記録)になって速くなります。WITH (..., TABLOCK) を足してテーブルロックを取ると、この条件に乗りやすい。
この仕組み、Pro SQL Server Internals(Dmitri Korotkevitch, p.642)にズバリ書かれています。
FULL 復旧モデルと BULK LOGGED 復旧モデルの違いは、最小ログ記録される操作——
CREATE INDEX、ALTER INDEX REBUILD、BULK INSERT、INSERT INTO、INSERT SELECTなど——を SQL Server がどうログに記録するかにある。FULL 復旧モデルではこれらは完全にログ記録され、SQL Server は操作の影響を受けた全データ行についてログレコードを書く。一方 BULK LOGGED 復旧モデルでは、SQL Server は最小ログ記録される操作を行単位ではログに記録せず、代わりにエクステントの割り当てを記録する。
俺の解釈はこうです。BULK INSERT がそもそも「最小ログ記録できる操作」の仲間だから、復旧モデルを BULK_LOGGED(か SIMPLE)にして TABLOCK を足すと、行ごとのログを省けて速くなる。
ただし、ただ乗りじゃありません。同じ書籍の p.643 では、BULK LOGGED にするとポイントインタイム リカバリ(特定時点への復元)ができなくなる点が指摘されています。本番でやるなら、取り込みの前後でフルバックアップを取る運用とセットにする。これが安全です。
4手法の使い分け: BULK INSERT / bcp / OPENROWSET / SqlBulkCopy
CSV を SQL Server に入れる方法は、BULK INSERT だけじゃありません。実行場所と権限で使い分けます。
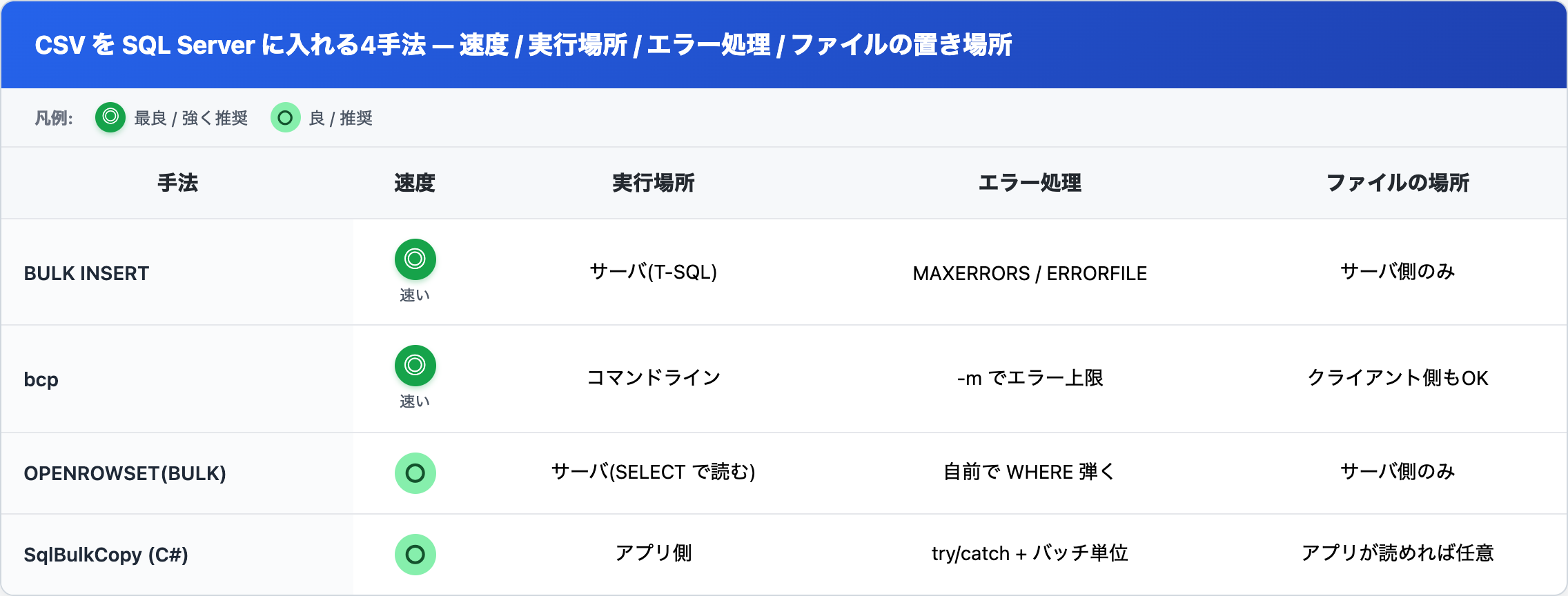
ざっくり言うと、サーバにファイルを置けるなら BULK INSERT、手元のPCのファイルを入れたいなら bcp か SqlBulkCopy、SELECT の中で他テーブルと混ぜたいなら OPENROWSET。迷ったら BULK INSERT が一番手軽です。
現場メモ
俺が最初に BULK INSERT を本番で使った時、見事に「全行1行扱い」で落ちました。
原因は改行コード。なんで全行1行やねん??って、画面の前で30分固まりました。受領した CSV が Linux 系のシステムから出力された LF で、こっちは Windows の感覚で CRLF を前提に書いてた。ROWTERMINATOR が合わず、ファイル全体が1行と判定されて、長すぎる行でエラー。納期も迫ってたから、けっこう焦りました。
そこから学んだのは、取り込み前にファイルの素性(文字コード・改行・BOM の有無)を一度ちゃんと見ること。エディタで開いて確認するだけで、4つのハマりの大半は事前に潰せます。CSV って「ただのテキスト」に見えて、素性で挙動が変わるんですよね。
まとめ
SQL Server の BULK INSERT で CSV を取り込む時のポイント、整理するとこうです。
- 最短は
BULK INSERT ... WITH (FORMAT='CSV', ...)— サーバ側パスに置くのが大前提 - 文字コードは
CODEPAGE(UTF-8=65001 / SJIS=932・Windows 版限定)。BOM 付き UTF-8 は環境によって先頭列が化ける - 改行は
ROWTERMINATOR(LF=0x0a / CRLF=0x0d0x0a)。ミスると全行1行扱い - エラー行は
MAXERRORS/ERRORFILEで逃がす - 大量なら
TABLOCK+ 復旧モデルでミニマムロギング(ただし復元制約とセット)
取り込み前にファイルの素性を1回見る。これだけで、CSV 取り込みはいい感じに10分案件になります。
よくある質問
Q1. ファイルが見つからないと言われます。パスは合ってるはずなのに。
BULK INSERT のパスは、SSMS を動かしている手元のPCではなく、SQL Server が動いているサーバから見たパスです。サーバのローカルに置くか、共有フォルダ(UNC パス)に置いて、SQL Server サービスアカウントに読み取り権限を付けてください。
Q2. 日本語が文字化けします。
CODEPAGE がファイルの文字コードと合っていません。UTF-8 なら 65001、Shift-JIS なら 932(CODEPAGE は Windows 版 SQL Server の機能で、Linux 版では未対応です)。Excel 由来の CSV は SJIS のことが多いです。加えて、BOM 付き UTF-8 だと環境によって先頭列が化けることがあるので、BOM 無しで保存し直すと直る場合があります。
Q3. 全部が1行に入ってしまう / 行の途中で落ちます。
改行コードの指定ミスです。ファイルが CRLF なら ROWTERMINATOR = '0x0d0x0a'、LF なら '0x0a'。指定とファイルがズレると、全行1行扱いか、最終列に \r が紛れ込みます。先にファイルの改行を確認してください。
Q4. 手元のPCにある CSV を、サーバに置かずに入れたいです。
BULK INSERT はサーバ側ファイル前提なので、その場合は bcp コマンド(クライアント側ファイルを読める)か、C# の SqlBulkCopy(アプリ側で読んで流し込む)を使います。サーバにファイルを置けない事情があるなら、この2つが選択肢です。
関連記事
- SQL Server UPDATE … FROM SELECT 3パターン — 取り込んだ後、既存テーブルへ反映する時の更新。JOIN / CTE / MERGE の使い分け
- SQL Server の CAST と CONVERT でハマる3箇所 — CSV の文字列を数値・日付に変換する時の定番の罠。取り込み後の型変換とセットで
- SQL Server DISTINCT の3つの罠 — 取り込んだデータの重複を排除する時の注意。NULL や複数列の挙動
- SQL Server の一時テーブル・テーブル変数・CTE を使い分ける3つの判断軸 — 取り込んだ生データをいったん一時テーブルで加工する時の基礎
- 「客先常駐しかない」業務SEが技術+αで抜ける道 — データ移行を安全にこなせる SE は、現場でどう評価が変わるか。手を動かす人のキャリア論
以上!
「CSV の文字化けで一晩潰した」経験ある人いたら、どんどんシェア待ってるぜ!!
この記事の参考文献
ここまでの知見は以下の書籍から引用しています。業務SE視点で再構成していますが、元の体系的な知識を学ぶには直接読むのがおすすめです。
📖 『Pro SQL Server Internals』(著: Dmitri Korotkevitch)
引用範囲: p.642 / p.643(第30章 トランザクションログ内部・最小ログ記録)
本の特徴: SQL Server の内部構造(ストレージ / インデックス / トランザクション / ロック / バックアップ / 復旧モデル)を DBA レベルで深掘りした技術書。BULK INSERT がなぜ速くできるのか(最小ログ記録)の根拠まで理解できる。
こんな人におすすめ: 業務SE / DBA / SQL Server 案件担当・大量データ処理を任されたエンジニア
執筆者
バイブス父さん — 業務SE 7年(SIer 正社員2 / フリーランス5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SIer の正社員からフリーランスに転じ、複数のエージェント経由で案件を回してきた経験ベースで「業務SE視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524(日々の現場メモ更新中)
📝 About Me で経歴詳細を見る

コメント