みなさんこんにちは!ヒロポンです!
一覧画面とか CSV 出力で「重複を消したい」。で、SELECT DISTINCT をペタッと付ける。業務SEなら一度はやりますよね。俺もやる。
ただこの DISTINCT、軽い気持ちで使うと足をすくわれます。「列ごとに効くと思ってた」。「件数が想定と合わない」。「開発機では一瞬なのに本番で急に固まる」。全部 DISTINCT あるあるなんですよね。
ん? DISTINCT 付けたのに重複が消えてなくない?? ってやつ。俺も2年目の頃に何回かやらかしました。原因はだいたい、これから書く3つのどれか。
今回は SQL Server DISTINCT で業務SEが実務で踏む3つの罠を、現場でやった話ベースでまとめます。複数列 / NULL / 大量行。最後に GROUP BY・ROW_NUMBER との使い分け早見表も付けるんで、朝礼で「なんで DISTINCT 使ったの?」って詰められた時の弾薬にしてください。
⏱ 対処目安サマリ
- 罠1(複数列) — 結果がおかしい原因の切り分け:5分。GROUP BY か別書き方に変えるだけ
- 罠2(NULL) — 件数のズレ確認:5分。NULL の集約挙動を知ってれば即わかる
- 罠3(大量行で遅い) — 実行計画の確認+INDEX/GROUP BY 見直し:30分〜
罠1. 複数列に DISTINCT — 列ごとじゃなく「行全体」で効く
一番多い勘違いがこれ。DISTINCT は 指定した列の組み合わせ(行全体)で重複を消す。列ごとに別々には効きません。
-- 部署を一意にしたいつもりで…
SELECT DISTINCT department, status
FROM employees;
これ、department だけの重複排除にはなりません。department と status の ペアが一意になるだけ。同じ部署でも status が違えば、別の行として残る。
-- department だけ一意にしたいなら GROUP BY で集約条件を明示する
SELECT department
FROM employees
GROUP BY department;
こう書けば、部署だけがいい感じに一意になります。DISTINCT と GROUP BY、見た目は似てるのに効く単位がそもそも違うんですよね。
実行結果(DISTINCT 複数列は組み合わせで残る・GROUP BY は部署だけ一意):
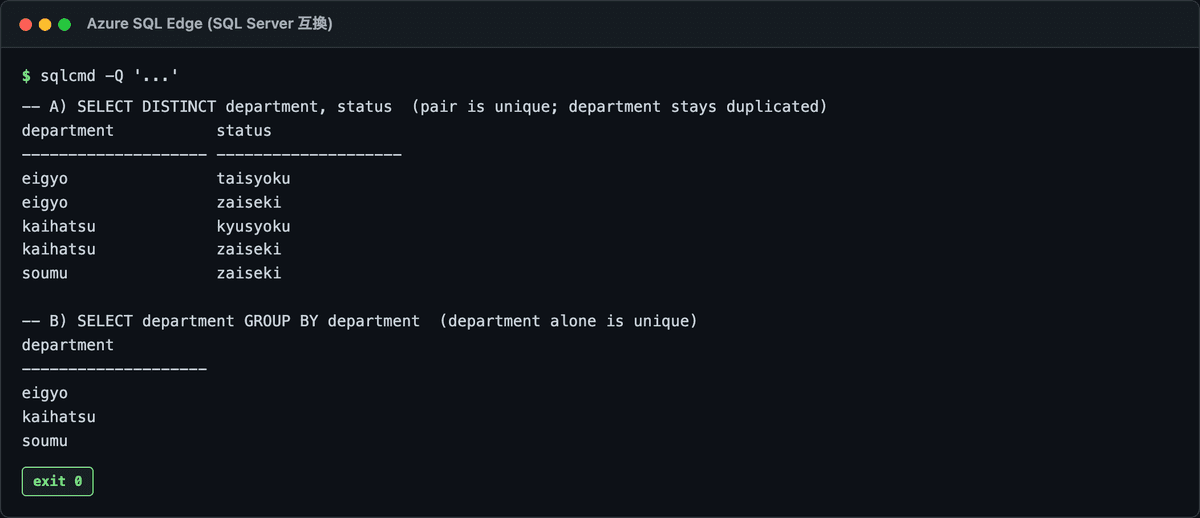
教訓:DISTINCT は「行の重複排除」、列単位の集約がしたいなら GROUP BY。ここを混同すると「DISTINCT 付けたのに重複が残ってる??」で30分溶かします。
罠2. NULL 同士は1行に集約される
DISTINCT の NULL の扱いは、WHERE の = とは別物。NULL 同士は「同じ値」とみなされて1行にまとまります。
-- bonus に NULL が複数行あっても…
SELECT DISTINCT bonus
FROM employees;
-- → NULL は1行だけ返る(複数の NULL は1つに集約)
WHERE bonus = NULL は1件も返さない。NULL 同士の = は「不明=偽」だから。なのに DISTINCT だと NULL がまとまる。この非対称が地味にハマる。
実行結果(DISTINCT で NULL は1行に集約・= NULL は0件・COUNT(*) と COUNT(bonus) で件数が違う):
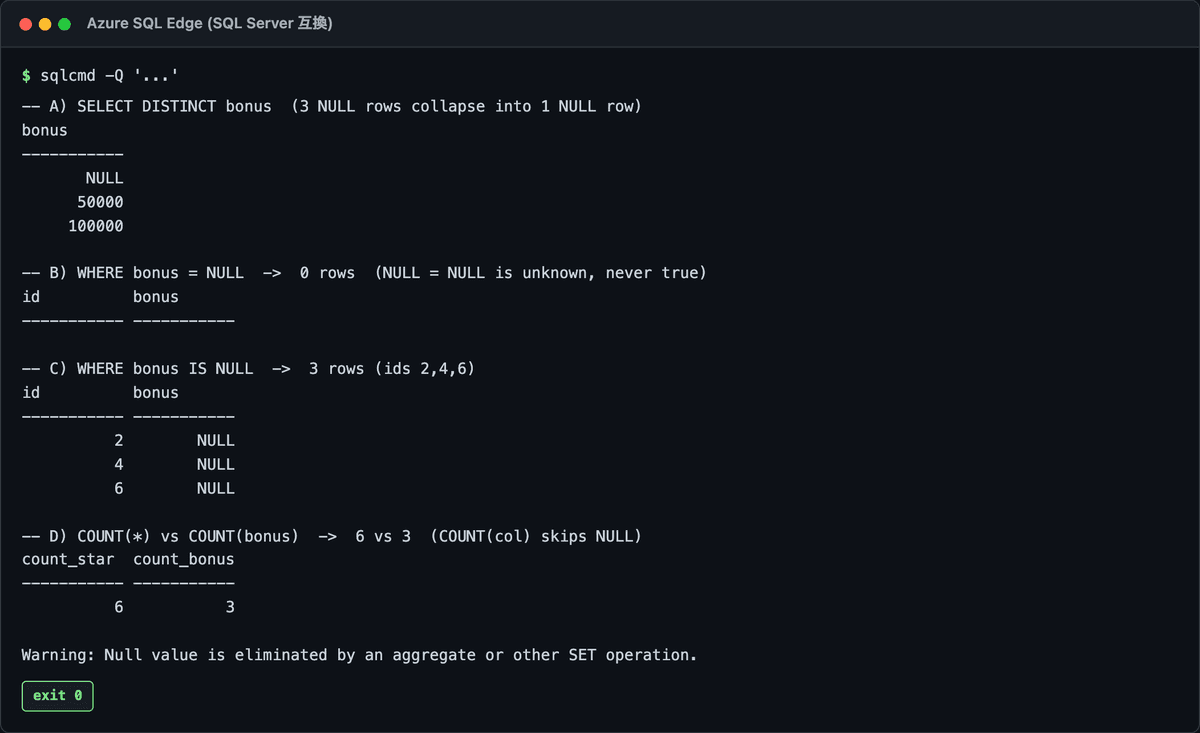
「NULL を1件として数えたくない」なら、WHERE bonus IS NOT NULL で先に除く。あるいは件数を数える時に COUNT(bonus)(NULL を数えない)を使う。COUNT(*) と COUNT(列) で結果が変わるのも、根っこはこの NULL 挙動です。
ここを押さえとくと、件数が1ズレた時に「あ、NULL か」ってすぐ当たりがつきます。こんな感じで NULL の挙動は、一回腹落ちさせれば一生モノ。
教訓:DISTINCT の NULL は「1行に集約」、= の NULL は「常に偽」。同じ NULL でも、文脈で挙動が真逆になる。
罠3. 大量行では並べ替えコストで遅くなる
開発環境では一瞬。なのに本番で急に固まる。これ、DISTINCT が 内部で全行をソートして重複を潰してるのが原因です。行数が増えると、この並べ替えコストがそのまま効いてくる。
『失敗から学ぶ RDB の歩き方』(曽根 壮大, 第6章「ソートの依存」p.89)でも、ソートが効くクエリで ORDER BY に INDEX を効かせたら 実行時間が 11.51秒 → 0.01秒 まで縮んだ例が出てきます。ポイントは「ソートの処理が不要になる」こと。INDEX の順序をそのまま使えれば、並べ替え自体が消える。
DISTINCT も理屈は同じ。重複排除のためのソートを INDEX で肩代わりできれば、速くなります。
-- 数百万行の orders から customer_id の重複を消す
SELECT DISTINCT customer_id
FROM orders;
-- → customer_id に INDEX が無いと、全行ソートが走って重い
俺の現場でも、数十万行のログテーブルに DISTINCT をかけた一覧が本番で固まったことがあって。実行計画を開いたら Sort 演算子がドンと乗ってました。やったのは2つ。
DISTINCTする列に INDEX を張る(ソートを INDEX で肩代わり)- そもそも DISTINCT が要るのかを見直す(JOIN の重複が原因なら、JOIN 条件側を直す方が筋がいい)
この2つで、固まってた一覧がいい感じにサクッと返るようになりました。
教訓:DISTINCT が遅い時は、まず実行計画で Sort 演算子を疑う。書籍では ORDER BY の例ですが、業務SE視点だと「重複排除のソートも INDEX で消せる」と読み替えると効きます。
まとめ / チートシート
DISTINCT の3つの罠、整理するとこう。
- 罠1(複数列) — 行全体で効く。列単位の集約は GROUP BY
- 罠2(NULL) — NULL 同士は1行に集約。
=の挙動とは別物 - 罠3(大量行) — 内部ソートで遅い。INDEX か GROUP BY 見直しで回避
で、「DISTINCT / GROUP BY / ROW_NUMBER、結局いつどれ使うん??」の早見表がこれ。
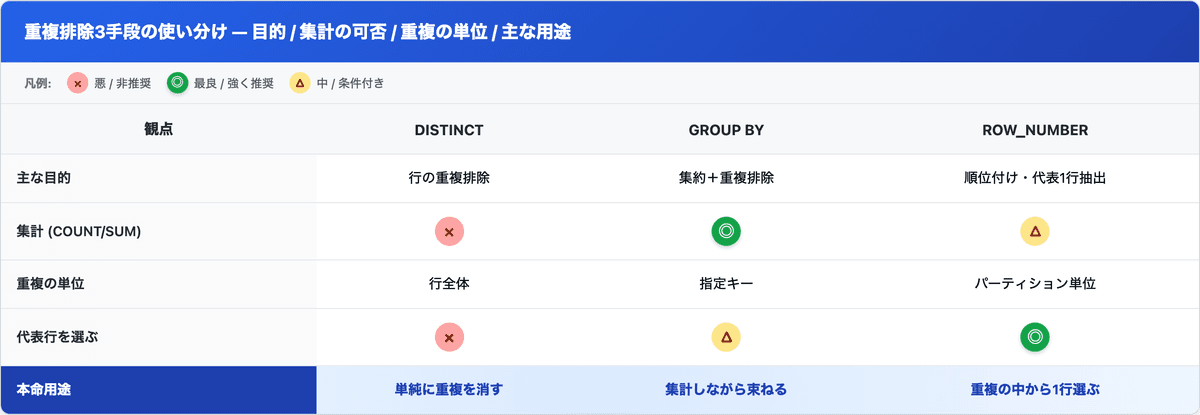
ざっくり言うと、消すだけなら DISTINCT、集計するなら GROUP BY、重複の中から特定の1行を選ぶなら ROW_NUMBER。この3択を朝礼でスッと言えると、技術選定の説明が一気に通りやすくなります!!
よくある質問
Q1. SQL Server で DISTINCT と GROUP BY はどちらが速いですか?

A. 重複排除だけが目的なら、どちらも内部でソートやハッシュが走るので大差は出ません。COUNT や SUM を同時にしたいなら GROUP BY、単純に重複を消すだけなら DISTINCT が読みやすい。速度より「何をしたいか」で選ぶのが正解です。
Q2. 複数列に DISTINCT を付けると列ごとに効きますか?
A. 効きません。SELECT DISTINCT a, b は a と b のペアが一意になるだけで、a 単独の重複は残ります。列単位で束ねたいなら GROUP BY を使ってください。
Q3. JOIN したら行が重複した。DISTINCT で消していい?
A. 消せます。ただ、まず JOIN 条件を疑うのが筋です。1対多の JOIN で増えた重複を DISTINCT で潰すと、大量行で重いソートが走る。JOIN 側で絞れるなら、そっちを直す方が速くて安全です。
ここまでで DISTINCT の罠は押さえられたはず。
こういう「SQL 一発の裏で何が起きてるか」を読めるかどうかって、地味だけど現場でめっちゃ効くんですよね。で、こういう判断を積み重ねてる業務SEほど、なぜか自分の市場価値を低く見積もりがち。SQL が読めることが実は単価にどう効くのか——その話を下の関連記事の最後に置いときます。
関連記事





以上!
同じところで詰まってる人いたら、どんどんシェア待ってるぜ!!
この記事の参考文献
罠3(大量行での並べ替えコスト)は、以下の書籍の知見を業務SE視点で参照しています。
- 『失敗から学ぶRDBの歩き方』 曽根 壮大 著(技術評論社, 2019 / ISBN 978-4297104085)
- 引用箇所: 第6章「ソートの依存」(p.89-90)
- RDB の設計・運用・性能チューニングで、業務SEが現場で踏みがちな失敗パターンを実例ベースで網羅。BTree インデックス / 統計情報 / 実行計画など、SQL Server 案件でも直接効く知識が多い1冊です。
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。 現職は SEO 直轄部の AI アドバイザー兼 PL、 副業で中小 SIer の CTO。 SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」 の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る