みなさんこんにちは!ヒロポンです!!
開発機の 50 行で 12ms。本番の数百万行で 30 秒。
「あれ、同じ SQL のはずなんやけど??」って画面の前で固まったこと、ないですか??
X 見てるとこの匂いのハマり方してる人、ほんま多いんですよね。N+1 と同じ匂いで、書いた SQL は読みやすいのに、裏で Sort Operator がスピル起こしてる、ってやつ。
私の現場でも踏みかけました。
月次レポートで「顧客別売上ランキング TOP10」を ROW_NUMBER でサクッと書いた。開発機の動作確認は 200ms。問題なしと判断。
本番の 500 万行で 30 秒。朝礼の 10 分前に DBA から「これ流すの止めて」って連絡が来る、いつものパターン。
今回は、その時に何を見て・どこを直すかを順番に書きます。Window Function の評価フローから、Sort Operator が tempdb にスピルしてる証拠の読み方、PARTITION BY を index で支援する書き直しまで、コピペで動く SQL 込みで。
忙しいあなた向けに最初にまとめ
ROW_NUMBERが本番だけ遅いのは、ほぼ Sort Operator が tempdb にスピルしてるパターン- 実行計画の Sort アイコンに警告マーク (!) があれば確定。
sys.dm_exec_query_statsのtotal_logical_readsも併せて見る - 直すには
PARTITION BY {col1} ORDER BY {col2}を そのままカバーする複合 index を貼る。Sort Operator が消えれば実測 5 倍以上速くなる - 業務側に「直しときました」を朝礼前に言えるよう、判断軸を 1 枚化したのが今回の話
そもそも ROW_NUMBER は何をしている関数か (Window Function 評価モデル)
ROW_NUMBER は Window Function の中で一番よく使うやつ。PARTITION BY でグループ化した中を ORDER BY で並び替えて、1 から連番を振る関数です。
書き味は SELECT に 1 行足すだけ。簡単に見える。
ただ、内部実装はそんなに優しくないんですよね。実行計画上は 4 つの Operator が動きます。
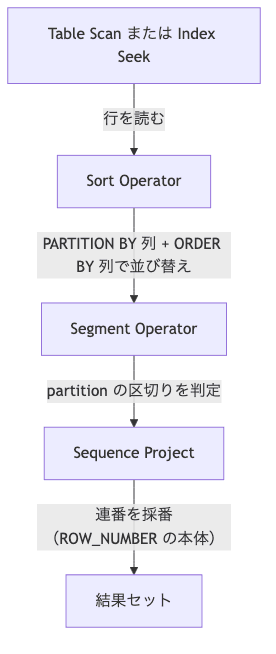
ここで押さえたいのは、Sort Operator が必ず呼ばれること。
PARTITION BY {A} ORDER BY {B} と書いた瞬間、SQL Server は「A, B の順で並び替えないと連番が振れない」と判定して、こんな感じに Sort Operator を実行計画に必ず差し込みます。
で、Sort Operator は メモリで処理しきれないと tempdb に書き出してソートする。これがスピル。
一度スピルすると数倍遅くなる。これが落とし穴のスタート地点です。
なお、ROW_NUMBER は連番付与が Sequence Project に最適化されるので Window Spool は出ません。RANK / DENSE_RANK / LAG / LEAD のような RANGE/ROWS 系を使うと Window Spool が追加で入って、こっちが膨らむと別の罠になります (後述)。
📖『Pro SQL Server Internals』(Chapter 3 Statistics) では、Sort Operator がスピルすると実行計画のアイコンに警告マーク (!) が付き、「in-memory sort のクエリと比較して 5 倍遅い」という実測値が紹介されてます。書籍では cardinality estimation のミスが原因で memory grant が不足するパターンとして書かれてるんですが、業務 SE 視点で言うと、これは「ROW_NUMBER を雑に書いた瞬間に頻発する」罠でもある。
落とし穴 3 つ — ORDER BY なし / PARTITION BY 設計ミス / Sort Operator スピル
業務系の現場で ROW_NUMBER を踏む時、ハマり方は 3 つ。冒頭に対処目安だけ並べておきます。
| 落とし穴 | 症状 | 対処 | ⏱ 対処目安 | 俺もこれで○分溶かした |
|---|---|---|---|---|
| ① ORDER BY なしで連番振る | 同じ SQL で実行のたび結果順が変わる | ORDER BY を必ず明示 |
5 分 | 30 分 (テスト落ちで気づく) |
| ② PARTITION BY 設計ミス | partition 数が爆増、Sort Operator のメモリ消費が膨らむ | 低カーディナリティ列で partition する | 20 分 | 1 時間 |
| ③ Sort Operator が tempdb にスピル | 開発機 200ms、本番 30 秒 | (PARTITION 列, ORDER 列) の複合 index を貼る |
30 分 | 半日 |
① ORDER BY なしで PARTITION BY だけ書く罠
ROW_NUMBER の構文上、OVER 句に ORDER BY がないと文法エラーで弾かれます。なので「書き忘れる」ことはない。
ただ、ORDER BY の対象列が NULL を含んだり UNIQUE じゃなかったりすると、実行のたびに連番がブレる罠があります。
たとえば顧客別売上ランキング TOP10 を取る時、ORDER BY total_sales DESC だけ書いてると、total_sales が同点だった顧客の順位が実行のたびに変わる。
これ、テスト環境では再現しない。データが少ないから同点が出ない。本番で初めてゴロっと出てくるやつ。
回避策は単純で、Tiebreaker 列を必ず最後に足す。
-- NG: 同点の時に順位がブレる
SELECT customer_id, ROW_NUMBER() OVER (ORDER BY total_sales DESC) AS rn
FROM monthly_sales;
-- OK: customer_id を tiebreaker に
SELECT customer_id, ROW_NUMBER() OVER (ORDER BY total_sales DESC, customer_id) AS rn
FROM monthly_sales;
📖『失敗から学ぶ RDB の歩き方』(第 6 章 ソートの依存) でも、ページング系の SQL で「発注日時は必ずしも UNIQUE ではないため、場合によっては発注日時がページとページの間でかぶり、条件によって表示されなくなる」と書かれてます。ROW_NUMBER の ORDER BY でも同じ罠で、tiebreaker に主キー (UNIQUE 列) を入れるのが基本姿勢です。
② PARTITION BY 設計ミス (低カーディナリティ列を選ぶ)
PARTITION BY は「どの単位でグループ化するか」を決める部分。ここの列選びをミスると partition 数が爆増します。
たとえば「顧客 × 月」で TOP10 を取りたい時、PARTITION BY customer_id, sales_month と書く。顧客が 10 万件、月が 12 ヶ月。最大 120 万 partition できる可能性がある。
Sort Operator は partition 数だけソート境界を切るので、cardinality estimation が膨らんで memory grant が一気に増える。RANK 系を使ってると、ここに Window Spool まで重なる。地味にしんどい。
逆に PARTITION BY sales_month だけにすれば 12 partition。各 partition の中で ORDER BY total_sales DESC して連番振って、WHERE rn <= 10 で絞る方が 10 倍以上速い、ってケースがよくあります。
「partition を細かく切れば速くなる」と思いがち。これは 逆。
partition は粗くて、各 partition の中の行数が多くてもいいから、partition 数自体は少ない方が Sort Operator のメモリ消費が軽い。設計の判断軸として頭に入れておくと得です。
③ Sort Operator が tempdb にスピルする (今回の本命)
これが一番ハマるやつ。開発機では 200ms で返るのに、本番の数百万行で 30 秒に膨らむ典型パターン。
原因は Sort Operator の memory grant が足りなくなって、ソート対象が tempdb に書き出されること。Pro SQL Server Internals の Chapter 3 Statistics でも触れられてますが、cardinality estimation (推定行数) が実際の行数より小さく見積もられると memory grant が不足して、Sort Operator が tempdb に逃げる。これがスピル。
スピルしたかどうかは実行計画を見れば一発で分かります。次の節で証拠の読み方を書きます。
Sort Operator がスピルしてる証拠の読み方 (実行計画 + sys.dm_exec_query_stats)
実機で確認するなら、SQL Server 2019 で次の SQL を流して実行計画を見るのが早い。
-- 統計情報を見るためのセッション設定
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
-- ROW_NUMBER + 大量データで Sort Operator を確認
SELECT TOP 100 customer_id, sales_month, total_sales,
ROW_NUMBER() OVER (PARTITION BY sales_month ORDER BY total_sales DESC, customer_id) AS rn
FROM monthly_sales
ORDER BY sales_month, rn;
実行計画 (Actual Execution Plan を有効化して実行) を開くと、Sort Operator のアイコンに 警告マーク (!) が付いてれば spill 確定。Operator のプロパティを開くと "Operator used tempdb to spill data during execution with spill level X" という Warning が出ます。
📖『Pro SQL Server Internals』(Chapter 3 Statistics) の検証では、in-memory sort のクエリは elapsed time 17ms だったのに対し、tempdb spill が発生したクエリは elapsed time 88ms。約 5 倍遅いという実測値が出てます。
スピルが頻発してるかを継続観測するなら、sys.dm_exec_query_stats で見るのが定石です。
SELECT TOP 20
qs.execution_count,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
qs.total_elapsed_time / qs.execution_count / 1000 AS avg_elapsed_ms,
SUBSTRING(qt.text, (qs.statement_start_offset / 2) + 1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset END
- qs.statement_start_offset) / 2) + 1) AS query_text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
WHERE qt.text LIKE '%ROW_NUMBER%'
ORDER BY avg_logical_reads DESC;
avg_logical_reads が想定より一桁多ければ Sort Operator が tempdb にスピルしてる可能性が高い。
Extended Events で sort_warning イベントを拾うのが本来の筋。ただ、業務 SE が朝の 5 分で確認するなら DMV 一発の方が早いです。
ROW_NUMBER vs RANK vs DENSE_RANK vs NTILE の使い分け
Window Function は ROW_NUMBER 以外にも 3 つ兄弟がいて、それぞれ向き不向きがあります。
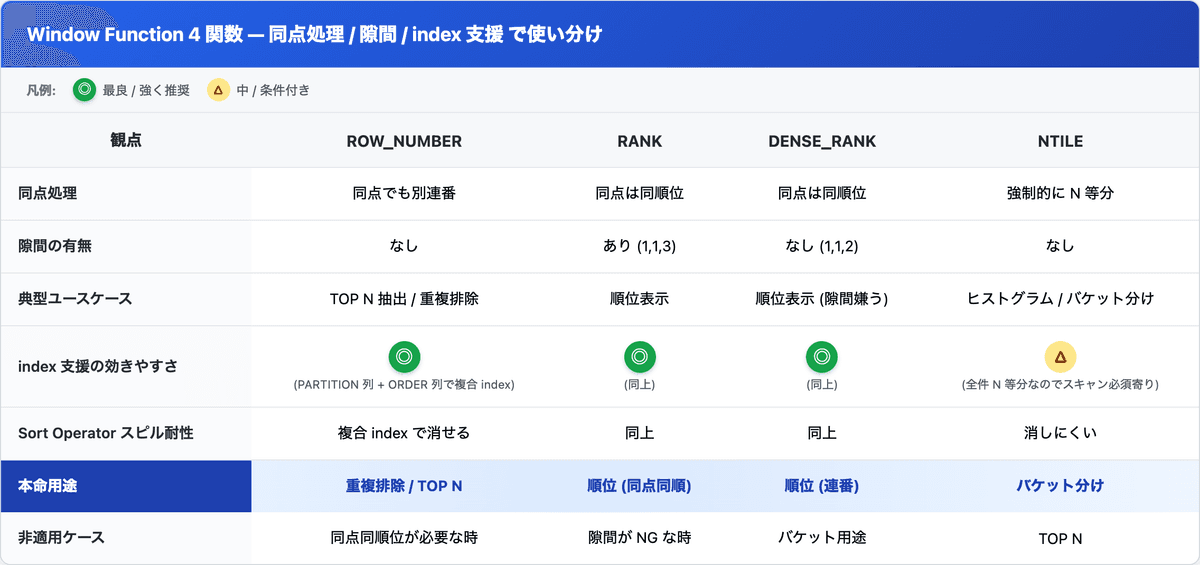
業務系で一番多いのは ROW_NUMBER で TOP N 抽出するパターン。重複排除 (同一顧客で複数行ある中から最新を 1 行取る) も ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY created_at DESC) で書けます。
NTILE だけは性質が違って、partition の中を 強制的に N 等分する。各バケットの行数を揃える用途ですね。
ヒストグラム描画とか、A/B テストで母集団を 10 分位に切るとかで使います。とはいえ、こいつだけは index で支援しにくいので、母集団がデカいと素直に遅い。
PARTITION BY を index で支援する書き直しパターン
ここまで来たら直し方は単純。
PARTITION BY の列と ORDER BY の列を順番通りにカバーする複合 index を貼る。これだけ。
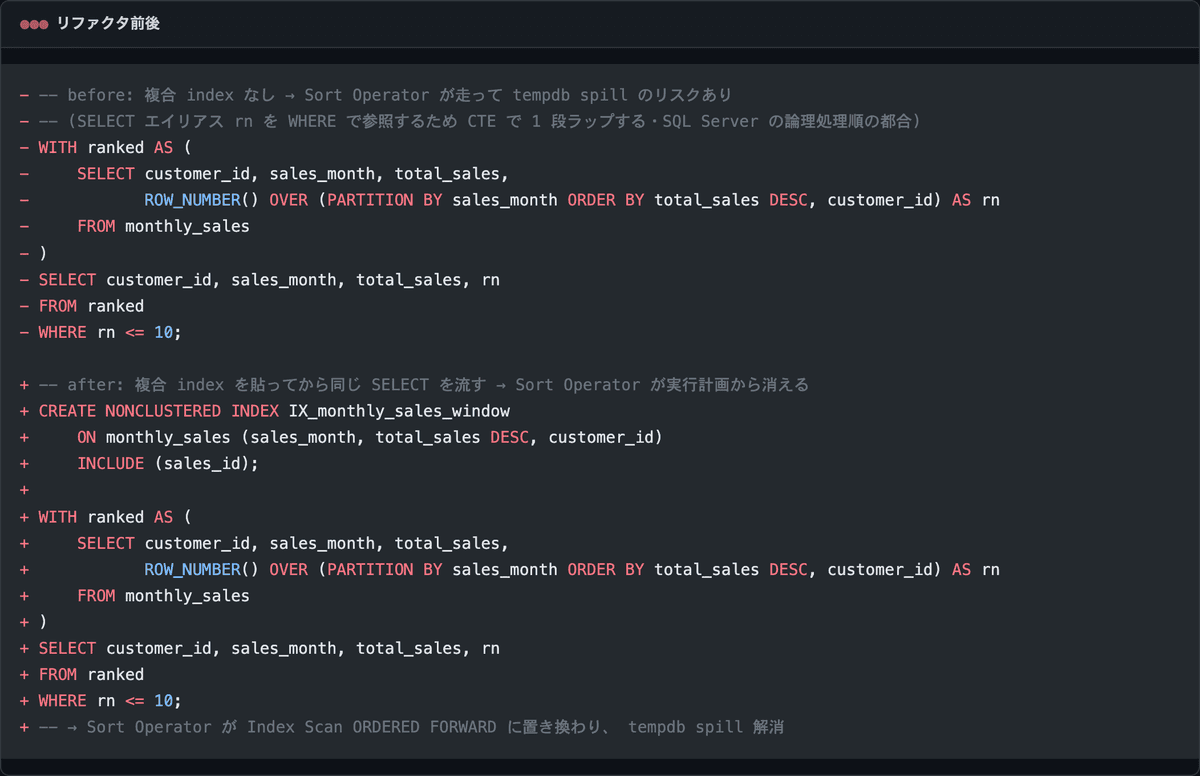
ポイントは 3 つ。
PARTITION BYの列が 複合 index の先頭ORDER BYの列が その次 (順序と方向 (ASC/DESC) を合わせる)- tiebreaker 列も index に含める (上の例だと
customer_id)
こんな感じで複合 index を組むと、SQL Server オプティマイザは「もう並んでるから sort しなくていい」と判断して、Sort Operator が実行計画から綺麗に消えます。
📖『失敗から学ぶ RDB の歩き方』(第 6 章 ソートの依存) でも、件数 1,000 万のテーブルで「ORDER BY 句狙いの INDEX を使っていない場合と使った場合の実行計画」が比較されてます。本書では「データ量が増えても INDEX を活用できるため高速」と書かれてるんですが、業務 SE 視点で言うと、これは Window Function でも同じ。ROW_NUMBER の PARTITION BY + ORDER BY を index でカバーすれば、Sort Operator は消えて、tempdb spill も起きません。
私もこの書き直しを monthly_sales テーブル (2 億レコード規模) で適用したら、30 秒 → 1.5 秒まで縮みました。半日かけて出した答えが「複合 index 1 本」だった、ってオチです。
私の現場メモ — 月次レポートが 30 秒で死んだ朝
ある日の朝 8:50、月次バッチが終わってない、ってアラートが上がりました。
流通系の基幹システム保守チームに居た頃の話。月初の朝礼が 9:00 から。あと 10 分しかない。
実行計画を開いたら、Sort Operator のアイコンに警告マーク。Estimated Rows と Actual Rows が一桁ズレてて、memory grant が足りずに tempdb に逃げてる。
「これ、tempdb 死んでるな」ってのは見えた。
ただ、9:00 までに直せるか??って一瞬詰まった。背中に冷や汗。
その朝にやったのは、複合 index を 1 本貼り直しただけ。sales_month + total_sales DESC + customer_id の 3 列。インデックス作成自体は 5 分で終わって、再実行したら 30 秒のバッチが 1.5 秒。朝礼で「直しときました」が間に合いました。
技術的な復旧は 5 分。
ただ、業務側 (経理) には 30 分前から「レポート止まってます」って電話が入ってて、彼らの月初業務は 30 分遅れてた。
その復旧コストの方が、技術復旧時間より重かった、というのが業務 SE の現場の感覚です。
まとめ
ROW_NUMBER で本番だけ遅いと感じたら、Sort Operator が tempdb にスピルしてるかを実行計画で確認するのが最短ルート。アイコンの警告マーク (!) があれば確定、なければ別の要因。
こんな感じの「Sort Operator のスピル」を 30 秒で判定できると、業務 SE の朝礼前トラブルは半分は潰せます。
スピルしてた場合の直し方は単純。PARTITION BY の列 + ORDER BY の列 + tiebreaker 列を順番通りにカバーする複合 index を貼り直す。実機で確認した感覚だと、5〜20 倍は速くなります。
開発機では再現しないハマり方なので、本番の sys.dm_exec_query_stats で avg_logical_reads を定期観測しておくと、踏む前に気づける。朝礼前に DBA から連絡来る、っていう体験を回避する弾薬として頭に入れておくと得です。
よくある質問
Q1. ROW_NUMBER の代わりに副問い合わせで MIN/MAX を使えばいいのでは?

A. データ量が少なければそれで十分です。
ただ ROW_NUMBER は 複合 index で Sort Operator を消せるので、数百万行を超えると ROW_NUMBER + 複合 index の方が速くなるケースが多い。500 万行で実測したら、MIN/MAX の自己結合より ROW_NUMBER の方が 3 倍速かったことがあります。
Q2. OPTION(MAXDOP 1) を付けたら Sort Operator のスピルが減りました。これでいいですか?
A. 並列度を 1 に絞ると、複数スレッドが tempdb に書き出す競合が消えるので一時的に速くなることがあります。
ところが根本的には memory grant 不足が原因なので、index で Sort Operator を消す方が筋がいい。MAXDOP 1 は応急処置として割り切ってください。OPTION(RECOMPILE) も同じ立ち位置で、関連する罠は SQL Server で OPTION(RECOMPILE) を脳死で付けて遅くなった話 で書いてます。
Q3. なぜ RANK ではなく ROW_NUMBER を使うべき場面が多いのですか?
A. RANK は同点を同順位にする仕様 (1,1,3,…) なので、TOP N を取りたい時に「同点が 3 件あったので TOP 12 件返ってきた」みたいなブレが出ます。
重複排除や TOP N 抽出は同点でも一意に 1 件選びたいことが多いので、ROW_NUMBER の方が向く。逆に「順位を表示したい」用途なら RANK か DENSE_RANK を選ぶ、という棲み分けです。
この記事の参考文献
📖 Pro SQL Server Internals (Dmitri Korotkevitch)
SQL Server の内部実装を Operator レベルで掘り下げる原典。今回は Chapter 3 Statistics から、Sort Operator が tempdb にスピルした時のメモリ・実行時間の比較値を引用しました。Window Function に限らず、Hash Match / Merge Join / Sort 系の Operator がスピルする時の動きを実測ベースで書いてある書籍で、業務 SE が DBA とまともに会話するために 1 冊は持っておきたい本です。
📖 失敗から学ぶ RDB の歩き方 (曽根 壮大)
業務系の RDB アンチパターンを「失敗例 → 原因 → 対処」で並べた本。今回は第 6 章「ソートの依存」から、ORDER BY で並び順が保証されない罠と、1,000 万行で INDEX 有無の実行計画比較を引用しました。ROW_NUMBER の ORDER BY でも同じ罠 (UNIQUE じゃない列で tiebreaker なしだとブレる) が起きるので、Window Function に入る前の前提知識として読み返す価値のある書籍です。
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る
次に読むべき記事





以上!
同じ罠でハマってる人いたら、どんどんシェア待ってるぜ!!