
SQL Server tempdb スピルを業務 SE が本番で踏む 3 箇所 — 検知と回避の判断軸
みなさんこんにちは!ヒロポンです!!
業務 SE やってると一度はあるやつ。
金曜の夜、本番のバッチがいきなり 4 倍遅くなって、tempdb が 100GB に膨らんで database read-only に飛ぶ。
監視に Slack 通知が刺さりまくって、PL からは「DBA に連絡したか?」が飛んでくる。あの瞬間、背中の冷たさはマジで忘れない。
ただね。DBA に投げる前に業務 SE 側で見ておくと話が 2 段速くなる箇所が 3 つある。
これ知らないと「アプリ側の問題ですか?? DB 側の問題ですか?」で 30 分ループする。俺もこれで一晩潰した。
この記事ではその 3 箇所 (DMV / 実行計画 / tempdb 設定) を業務 SE 目線で順に整理する。コピペで動く DMV クエリと、実行結果のターミナル PNG 付き。
忙しい人向けに最初にまとめ
- tempdb スピルは Sort / Hash operator のメモリ grant が不足してディスクに書き出される現象
- 業務 SE が本番で見るのは
sys.dm_exec_query_memory_grants/ 実行計画の Estimated vs Actual / tempdb ファイル設定の 3 箇所 - 判断軸: memory grants pending > 0 なら待たされてる、Estimated 1 行 vs Actual 100 万行なら統計情報乖離、tempdb 1 ファイルなら物理競合
- 一番きついのは技術復旧時間より、止めた業務側に電話で頭下げる 30 分。夜中 DBA を叩き起こす前にここで 1 段絞り込む
そもそも tempdb スピルとは何か
SQL Server で SELECT を流すと、オプティマイザは「このクエリは何 MB メモリ使いそうか」を事前に見積もる。これを memory grant と呼ぶ。
grant されたメモリの中で Sort や Hash Match がおさまればメモリで完結する。
おさまらないとどうなるか??
ディスクに書き出される。これが スピル (spill)。書き出し先が tempdb。
📖『Pro SQL Server Internals』(Chapter 3 / Statistics and Query Memory Grants) ではこう説明されてる:
一方で、見積もりが過小だと、実行計画内のいくつかのオペレータがメモリ不足に陥る状況が起こりうる。Sort オペレータがインメモリでソートするだけのメモリを確保できなかった場合、SQL Server は行セットを tempdb にスピルさせ、そこでソート処理を行う。Hash テーブルでも同様の状況が発生する。
要するに「メモリ見積もりを過小評価するとスピルが起きる」。
過大評価しても「メモリの無駄遣い」で別の害が出る。ちょうどいい grant を出すには 統計情報が正確であることが前提なんですよね。
そして workspace memory (memory grant の財源) は、同書 (Chapter 28 / Memory-Related Wait Types) で:
SQL Server はクエリのメモリ grant を、buffer pool 内にある workspace memory と呼ばれる特別な領域から割り当てる。workspace memory の最大サイズは buffer pool サイズの 75% に制限される。デフォルトでは、1 クエリあたりのメモリ grant 最大サイズは workspace memory の 25% を超えることができない。
要するに「buffer pool の 75% が workspace、そのうち 1 クエリで使えるのは最大 25%」。
buffer pool 32GB なら workspace 24GB、1 クエリ max 6GB。これを超えるクエリは grant 待ちで Resource Semaphore に並ぶ。
俺の現場では「6GB 超えるクエリ書くな」が暗黙ルールだった。
Hash spill と Sort spill の違い
| 種別 | 発生 operator | 典型クエリ |
|---|---|---|
| Sort spill | Sort operator | ORDER BY / DISTINCT / GROUP BY (Hash 不使用時) |
| Hash spill | Hash Match (Join / Aggregate) | JOIN (大テーブル × 大テーブル) / GROUP BY 大量カーディナリティ |
両方とも症状は「実行計画の operator に黄色 ⚠ 三角マーク」が立つ。
SSMS で実行計画を開いて見つけたら、そこがスピルポイント。
業務 SE が本番で踏む 3 箇所
順に書くとこう。
- 罠①: メモリ grant pending — 待たされてる側に並んでないか?
- 罠②: 実行計画の Estimated vs Actual 行数乖離 — 見積もりがそもそも狂ってないか?
- 罠③: tempdb ファイル分割と autogrowth — 受け皿側がパンクしてないか?
DBA に「tempdb 飛んでます」だけ投げると、ここを全部聞き返される。
自分で 1 周見ておくと話が早い。
罠①: メモリ grant 不足の検知 (DMV クエリ)
まず最初に見るのが sys.dm_exec_query_memory_grants。
これ、今この瞬間メモリ grant を待ってる / 持ってるクエリを返してくれる。
📖『Pro SQL Server Internals』(Chapter 28 / System Troubleshooting) ではこう書かれてる:
この問題は、SQL Server:Memory Manager オブジェクトの memory grants pending パフォーマンスカウンタを見ることで確認できる。このカウンタはメモリ grant を待っているクエリの数を示す。理想を言えば、このカウンタ値は常にゼロであるべきだ。
「memory grants pending カウンタは常にゼロが理想」。
ゼロ以外ってことは、誰かが grant を持ってて、待ってる誰かが詰まってる。俺の現場では夜中 0:00 のバッチ重なる時間帯に > 0 になりがちだった。
実際に叩く DMV クエリはこれ。
-- 今この瞬間メモリ grant を持ってる / 待ってるクエリ
SELECT
mg.session_id,
mg.request_time,
mg.grant_time,
mg.requested_memory_kb / 1024 AS requested_mb,
mg.granted_memory_kb / 1024 AS granted_mb,
mg.required_memory_kb / 1024 AS required_mb,
mg.used_memory_kb / 1024 AS used_mb,
mg.queue_id, -- NULL なら grant 済・値あれば待ち
DATEDIFF(SECOND, mg.request_time, GETDATE()) AS waited_sec,
SUBSTRING(qt.text, 1, 120) AS query_head
FROM sys.dm_exec_query_memory_grants mg
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) qt
ORDER BY mg.request_time;
実行結果:
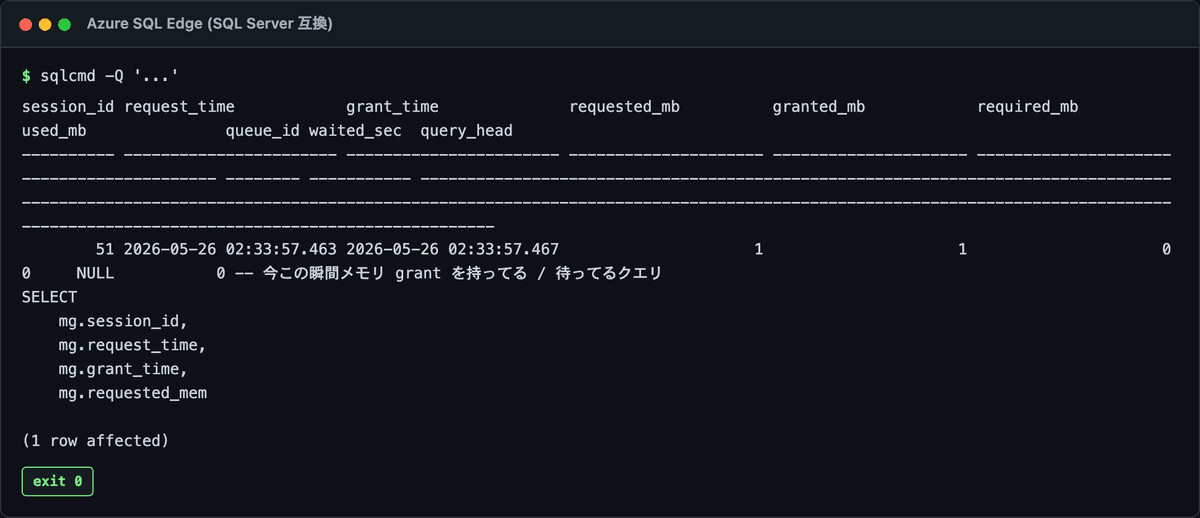
判断軸は 3 つだけ。
grant_timeが NULL → まだ grant されてない・待たされてる側granted_mb>>required_mb→ 過大 grant・他クエリの足を引っ張ってるwaited_sec> 10 → Resource Semaphore キュー詰まり
📖 同書では sys.dm_exec_query_resource_semaphores も紹介されてる。
こっちは「Resource Semaphore キュー全体の統計」(granted / available / waiting 数) が一発で見れる。
個別クエリより全体俯瞰したい時はこっち。
-- Resource Semaphore のキュー俯瞰
SELECT
resource_semaphore_id,
target_memory_kb / 1024 AS target_mb,
max_target_memory_kb / 1024 AS max_target_mb,
total_memory_kb / 1024 AS total_mb,
available_memory_kb / 1024 AS available_mb,
granted_memory_kb / 1024 AS granted_mb,
used_memory_kb / 1024 AS used_mb,
grantee_count,
waiter_count,
forced_grant_count
FROM sys.dm_exec_query_resource_semaphores;
実行結果:
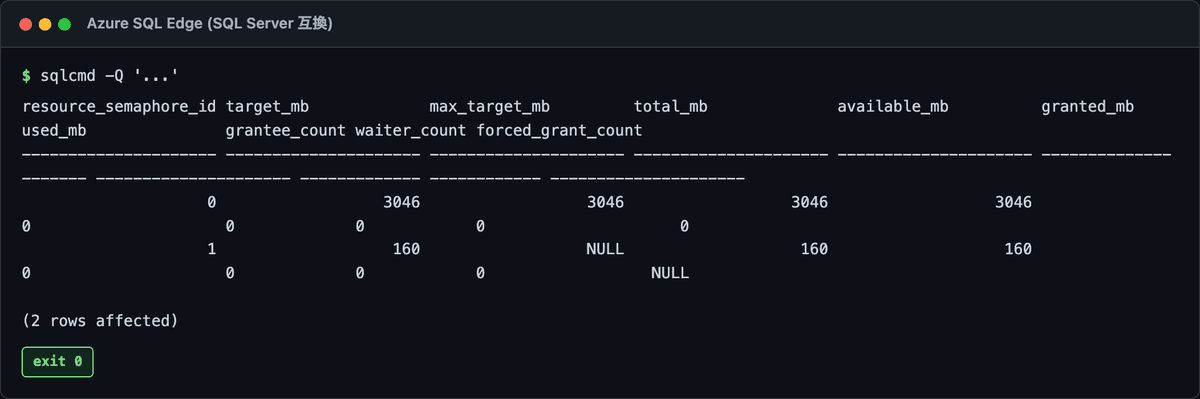
こんな感じで waiter_count > 0 が見えたらキューが詰まってる証拠。
forced_grant_count が立ってると「強制 grant (Resource Semaphore が諦めて grant した低品質 grant)」が出てて、そのクエリは高確率でスピルしてる。
SQL Server 2012 SP3 以降なら dm_exec_query_stats も使える
ここ、業務 SE 向けにバージョン別の差を 1 個書いておく。
古い SQL Server (2008 R2 とか) だと、過去の grant 情報は cache plan からしか拾えない。
が、2012 SP3 / 2014 SP2 / 2016 以降は楽できる。
📖 同書 (Chapter 28) より:
SQL Server 2012 SP3、SQL Server 2014 SP2、SQL Server 2016 では、メモリ grant のトラブルシューティングを簡素化する複数の拡張が導入された。sys.dm_exec_query_stats ビューは出力カラムにメモリ grant 関連の統計情報を提供する。
sys.dm_exec_query_stats に grant 系カラム (min_used_grant_kb / max_used_grant_kb / min_grant_kb / max_grant_kb 等) が乗ってる。
これで「過去どのクエリがどれだけ grant 使ったか」が累計で取れる。SQL Server 2016 以降なら Query Store も使える。
-- 過去 grant が大きかった TOP 10 クエリ (2012 SP3 / 2014 SP2 / 2016+)
SELECT TOP 10
qs.execution_count,
qs.max_grant_kb / 1024 AS max_grant_mb,
qs.min_grant_kb / 1024 AS min_grant_mb,
qs.max_used_grant_kb / 1024 AS max_used_grant_mb,
qs.max_ideal_grant_kb / 1024 AS max_ideal_grant_mb,
SUBSTRING(qt.text, 1, 120) AS query_head
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
WHERE qs.max_grant_kb > 0
ORDER BY qs.max_grant_kb DESC;
max_grant_kb >> max_used_grant_kb のクエリは過大 grant。リソースを無駄に握りに行ってる犯人候補。
業務 SE 視点だと「夜中だけ走る重いバッチ」がよく出てくる。
罠②: 実行計画の Estimated vs Actual 行数乖離
DMV で「待たされてる」がわかった。
ん? 待たされてるのはわかったけど、なぜそのクエリはそんなにメモリを要求したのか? ここを見にいく。
ここで実行計画。
オプティマイザが grant を決めるのは統計情報ベースの行数見積もり (cardinality estimation)。
つまり統計が古いと、1 行返るはずが 100 万行返って、grant 全然足りなくてスピル直行。
別記事の 業務 SE が踏む統計情報乖離 — 本番とステで実行計画が割れる時に最初に見る 3 箇所 と、まさに同じ根っこの話なんですよね。
実行計画でスピルが起きたかを 1 発で見る方法
SSMS で「実際の実行プランを含める (Ctrl+M)」を ON にして流す。
Sort や Hash Match operator のプロパティを開いて、以下 3 つを確認する。
判断軸は 1 つだけ。
Estimated Rows と Actual Rows が一桁以上ズレてたら統計情報乖離が真犯人。
grant を増やしても根本治癒しない。ここで「DBA に投げる前に UPDATE STATISTICS を本番影響時間帯に外して打つ」という判断ができる。
これ、SQL Server 実行計画の読み方 — Estimated vs Actual で業務SE が最初に見る5箇所 で実行計画の読み方は別途まとめてる。
tempdb スピル前の 1 歩手前をもう一段詳しく見たい時は、ついでに別タブ開いて後で読んでくださいな。
あと「OPTION(RECOMPILE) を脳死で付ける」は逆効果のことがある
たまに「クエリ遅いから OPTION(RECOMPILE) 付けとけ」が現場で出る。
これ、grant の見積もりがそもそも狂ってる時には毎回 grant 計算で CPU 食うだけで、スピル自体は直らないんですよね。
別記事 SQL Server で OPTION(RECOMPILE) を脳死で付けて遅くなった話 で書いた通り、統計が正確じゃないと recompile しても grant ズレたまま。
罠③: tempdb ファイル分割と autogrowth 設定の現状確認
ここまでで「スピルがなぜ起きてるか」は絞り込めた。
最後は「受け皿の tempdb が物理的にちゃんと整ってるか」。
tempdb のチェック観点は 4 つ。
-- tempdb のファイル構成と autogrowth 設定
SELECT
name,
physical_name,
type_desc,
size * 8 / 1024 AS current_mb, -- size はページ数 (1page=8KB)
max_size,
is_percent_growth,
growth * 8 / 1024 AS growth_mb,
state_desc
FROM tempdb.sys.database_files;
実行結果:
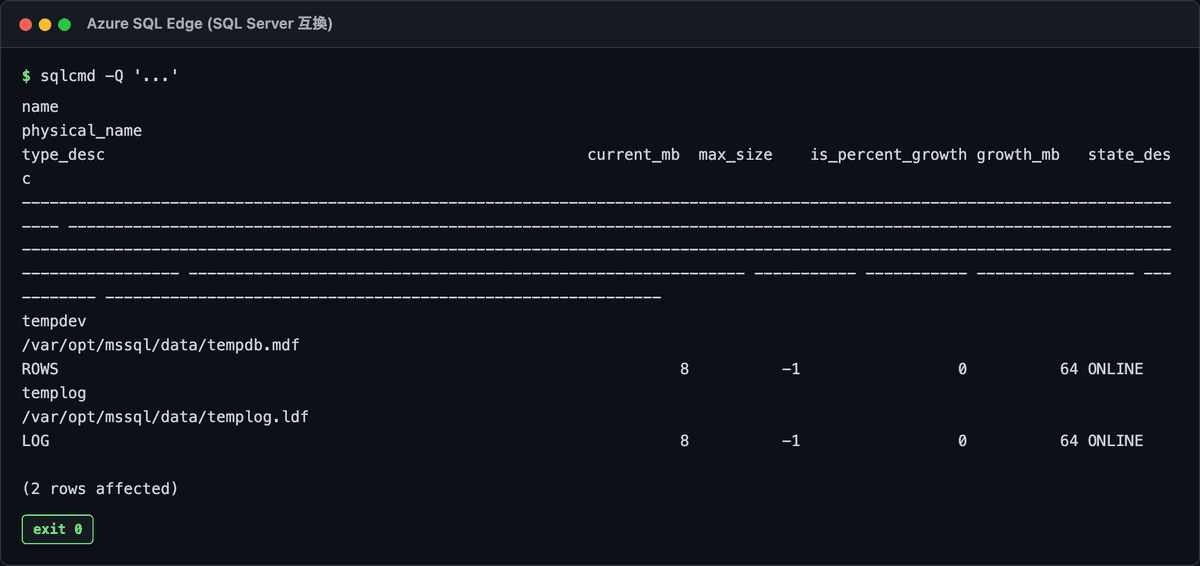
判断軸はこの 4 つ。
| 観点 | 危険サイン | 推奨 |
|---|---|---|
| データファイル数 | 1 個だけ | CPU コア数 ≤ 8 ならコア数、> 8 なら 8 個から始めて競合監視 |
| ファイルサイズ均一性 | バラバラ | 全部同じサイズで切る (proportional fill の偏り防止) |
| autogrowth サイズ | 10% (デフォルト) | 固定 MB (256MB / 512MB) で設定・100GB tempdb で 10% 拡張は痛い |
| 物理ディスク | OS ドライブと同居 | tempdb 専用 SSD・本番運用なら必須 |
業務 SE 視点だと「そもそも自分で tempdb の構成変えていいの?」って感じだと思う。
答え: 設定変更は DBA / インフラ管轄。
でも現状を SELECT して見るのは業務 SE がやって OK。ここで「データファイル 1 個でしたー」を持っていけば、DBA も「それ NUMA 構成でほぼ確実に PFS 競合してる」と即判断できる。
autogrowth 10% の地味な罠
これ俺もハマったやつ。
tempdb 50GB 運用してる現場で、夜中バッチでスピルして tempdb がいきなり 5GB 拡張要求出した瞬間、拡張中の PAGEIOLATCH で全クエリが 30 秒固まった。
ファイル拡張中は I/O ブロックされる。100GB tempdb で 10% = 10GB 一気に拡張は地獄。
これだけはやらないで。。
動作確認メモ: ここで紹介した DMV クエリは Azure SQL Edge container で
SELECT 構文の動作確認 + 結果ターミナル PNG 化まで実施済み。本番 SQL Server 2016 以降での挙動 (memory grants pending カウンタ / Resource Semaphore キュー詰まり) は実環境の負荷状態に依存する。開発機では再現しないやつなので、本番踏んでから DMV を仕込むのではなく事前に手元 SSMS にスニペット保管しておくのが現実的。
業務 SE がやるべき 3 ステップ整理 (DBA に投げる前に)
DBA に投げる前に自分で 1 周見る順番を比較表で並べる。
PNG 化してるので、SSMS の隣で開いておけば「今どこ見てる」がブレない。
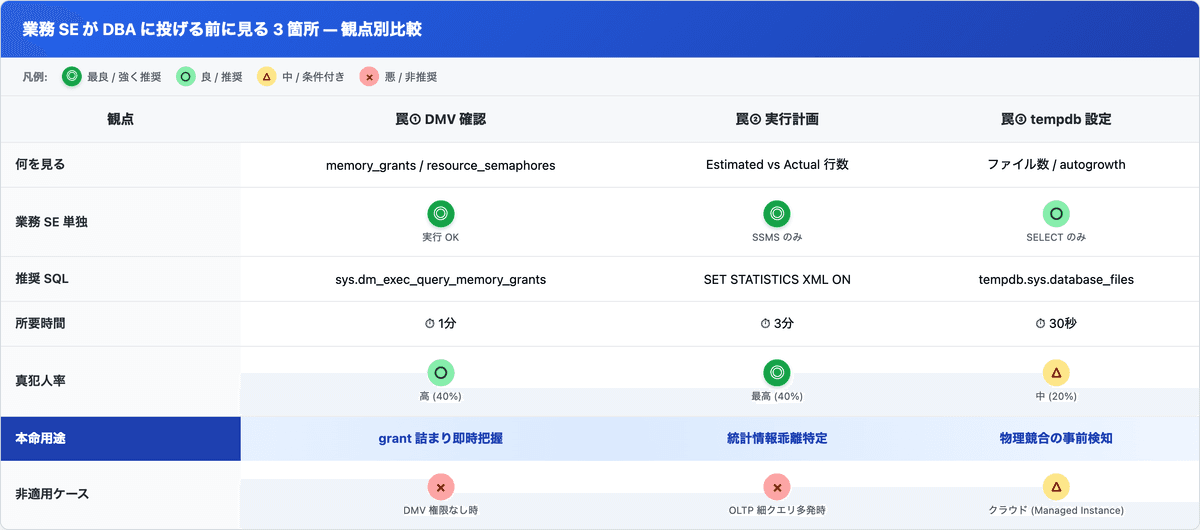

ちなみに罠③ は権限的に「VIEW SERVER STATE」と tempdb への SELECT 権限が必要なので、業務 SE 用に権限取りに行くだけで一日溶けることもある。
これは事前に PM 通して取っといたほうがいい。
俺の現場メモ
物流系の基幹システム保守やってた時の話。
月末バッチ (毎月 30 日深夜 1:00 起動) が、ある月から急に 20 分が 90 分になった。
アプリ側は何も変えてない。やったのは前日の DBA 側「マスタテーブルのインポート (3000 万件)」のみ。
最初は「DB 側で何かやったでしょ」で DBA に投げた。
帰ってきた答え:「アプリ側の問題じゃないですか?」。これで 30 分溶けた。
dm_exec_query_memory_grants 流したら、該当クエリが6GB 要求して 1.2GB しか grant されてない (max workspace 比 25% 上限ヒット)。実行計画見たら Sort operator に黄色三角、Estimated 12 万行 vs Actual 3000 万件。
答え: インポート直後の統計情報が更新されてなかった。
UPDATE STATISTICS dbo.MasterTable WITH FULLSCAN を業務時間外に打って再実行したら 18 分に戻った。
ここまで DMV 1 本 + 実行計画 1 枚 + UPDATE STATISTICS 1 文。トータル 40 分。
技術的にはこれで解決。
でもね。一番きつかったのは復旧時間じゃなくて、翌朝業務側に「昨夜のバッチ遅延の原因と再発防止策を 30 分後の朝会で説明してください」と電話で言われた瞬間。
電話切った後、画面の前で完全に固まった。
技術復旧 40 分 < 業務側への信頼回復 60 分。こっちのコストのほうが重い、ってのは業務 SE やってる人ならわかると思う。
DMV 仕込んでなかったら、あれなしじゃ DBA エスカレで朝までいってた。仕込みは平時のうちに。
まとめ
ここまでで業務 SE が tempdb スピル本番踏んだ時に見るべき 3 箇所の絞り込み方は揃った。要点だけ並べると:
- tempdb スピルは Sort / Hash operator のメモリ grant 不足でディスクに書き出される現象
- 業務 SE が本番で見る 3 箇所: DMV (
memory_grants/resource_semaphores) / 実行計画 (Estimated vs Actual) / tempdb 設定 (ファイル数 / autogrowth) - 一番多いのは統計情報乖離による grant 過小評価 →
UPDATE STATISTICSで直る - 物理的に tempdb 自体が貧弱なケースもあるが、設定変更は DBA 管轄・現状 SELECT は業務 SE が事前に取れる
- 平時のうちに DMV スニペットを SSMS に保管 → 本番踏んでから探さないこと
DBA に「全部丸投げ」すると関係が悪くなる。
でも「3 箇所見てきました、罠② 統計情報乖離っぽいです、UPDATE STATISTICS 業務時間外に打って OK?」と持っていくと話が一気に速くなる。
業務 SE のアドバンテージは、アプリ側の業務文脈と DB 側の現状を両方持って交渉できることなんですよね。
よくある質問
Q1. なぜ OPTION(RECOMPILE) を付けてもスピルが直らないことがあるの?

A. recompile は実行計画を毎回作り直すだけで、memory grant の見積もり精度は統計情報依存のまま。統計が古いと recompile しても grant ズレ続けるのでスピル直らない。真っ先に打つべきは UPDATE STATISTICS。詳しくは別記事 SQL Server で OPTION(RECOMPILE) を脳死で付けて遅くなった話 に書いた。
Q2. tempdb のファイル数を増やすだけでスピルは減るの?
A. スピル自体は減らない。ファイル数を増やすのは「PFS / GAM ページの競合 (PAGELATCH 待ち)」を分散させるため。スピルの量を減らしたいなら、grant 見積もりを直す (統計情報更新) か、クエリを軽くする (index 追加 / 結合順最適化) のが正攻法。役割が違うので混同しない。
Q3. クラウド (Azure SQL Database) でも同じ DMV 使える?
A. ほぼ使えるが一部制限あり。sys.dm_exec_query_resource_semaphores は Azure SQL Database でも参照可、Managed Instance なら ProSql 同書の手順がほぼそのまま動く。ただし tempdb の物理ファイル構成 (罠③) はマネージドサービス側が管理してるので、業務 SE が見るよりサービス階級 (DTU / vCore) の見直しが先になる。
Q4. DMV の権限取れない・閉鎖環境の現場ではどうする?
A. 業務 SE 視点では「SSMS で実行計画の Sort/Hash Match に黄色三角が立ってるか」だけ見れれば 8 割わかる。DMV ゼロでも、SET STATISTICS XML ON で実行計画を出力 → 解析。残り 2 割は DBA に「黄色三角が立ってる operator のメモリ grant を確認してほしい」と具体的に依頼する。これだけでも空振りは半減する。
Q5. SQL Server 2008 R2 でも DMV は同じ?
A. sys.dm_exec_query_memory_grants と sys.dm_exec_query_resource_semaphores は SQL Server 2005 から入ってるので OK。一方で sys.dm_exec_query_stats の memory grant 関連カラム (max_grant_kb 等) は SQL Server 2012 SP3 / 2014 SP2 / 2016 以降。古いバージョンだと cached plan から手で拾うしかない。ProSql 本にも「2008 R2 だと cached plan 解析が必要」と書かれてる。
関連記事





以上!
同じ罠でハマってる人いたら、どんどんシェア待ってるぜ!!
この記事の参考文献
ここで取り上げた知見は以下の書籍から引用しています。業務 SE 視点で再構成していますが、元の体系的な知識を学ぶには各書籍を直接読むのがおすすめです。
📖『Pro SQL Server Internals』— Dmitri Korotkevitch
引用範囲: Chapter 3 (Statistics and Query Memory Grants) / Chapter 28 (Memory-Related Wait Types / System Troubleshooting)
本の特徴: SQL Server のストレージエンジン・クエリオプティマイザ・メモリ管理・実行計画の内部挙動を、DMV と実機検証ベースで網羅した洋書の決定版。memory grant / workspace memory / Resource Semaphore / tempdb スピルなど、業務 SE が本番で踏む箇所の「なぜそうなるか」を 1 冊で押さえられる。
こんな人におすすめ: SQL Server を業務で扱う SE / DBA・DMV と実行計画でパフォーマンスチューニングを内製したいエンジニア・英語の技術書に抵抗がない人
(アフィリエイトリンク準備中)
📖『失敗から学ぶRDBの歩き方』— 曽根 壮大
引用範囲: p.158
本の特徴: RDB の設計・運用・性能チューニングで「業務 SE が現場で踏みがちな失敗パターン」を実例ベースで網羅。BTree インデックス / 統計情報 / 実行計画乖離など、SQL Server 案件でも直接効く知識多数。
こんな人におすすめ: 業務 SE / DBA / DB 設計担当・SQL を業務で書くエンジニア全般
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る



