みなさんこんにちは!ヒロポンです!!
「そろそろ SQL Server、2025 に上げたいんだよね」
朝礼でプロパーがサラッとそう言い出した瞬間、心の中で「うわ、来た」ってなったこと、ないですか??
うちの現場、まだ 2016 で回ってます。基幹の夜間バッチも、画面から叩いてる生 SQL も、ぜんぶ 2016 前提で組んである。それを「上げたい」の一言で片付けられても、その場では言葉が出てこない。
で、家に帰ってから「sql server 2025 移行 判断」とかで検索する。この記事に辿り着いた人も、たぶん似たような朝を過ごしたんやと思います。
先に結論だけ。レガシー現場が 2025 で気にすべきは、派手な新機能じゃない。サポート期限と、互換性レベルを上げた時に実行計画が変わるリスク。この2つだけです。
忙しい人向けに最初にまとめ
- SQL Server 2025 の目玉(ベクトル検索とか AI 連携)は、2016 で止まってる業務系現場には今すぐ要らない
- 本当に気にすべきは2つ。①SQL Server 2016 の延長サポートが 2026年7月14日で切れる ②移行で互換性レベルを上げると新しい推定エンジン(CE)で実行計画が変わって、逆に遅くなるクエリが出る
- 上げる時は「Query Store を先に有効化してから上げる」「新CEが合わなければ互換性レベルは上げたまま旧CEだけ戻す」で段階的にやれば事故りにくい
- レガシー現場が無理に最新へ飛ぶ必要はない。サポート期限が長い2019 か 2022 を踏み台にするのが現実的な落としどころ
まず、SQL Server 2025 で「変わったこと」を一望する
判断する前に、4世代を並べて全体像を掴む。ここを上司に見せられるだけで、朝礼の空気はだいぶ変わります。
その前に、移行の話で必ず出てくる「互換性レベル」って言葉だけ定義しときます。
互換性レベルとは、データベースが「どのバージョンの SQL Server として振る舞うか」を決める設定値。エンジン本体を新しくしても、データベース単位で古い挙動のまま動かせる後方互換の仕組みです。
これが今日の話のキモになるので、頭の隅に置いといてください。
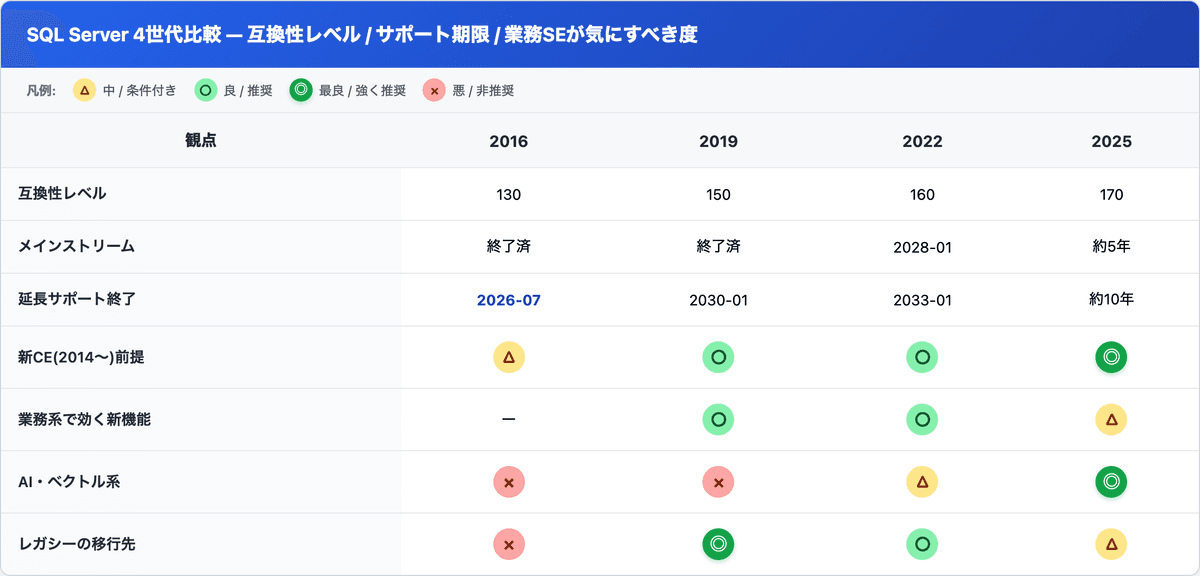
表の見方はシンプル。◎ が「ここを目指せ」、× が「今ここに留まるな / まだ要らない」です。
引っかかるとしたら、2025 の AI・ベクトル系が ◎ なのに、移行先としては △ なところ。これ、矛盾してないんですよ。「最新機能が一番盛ってある」ことと「君の現場の移行先として最適」は別の話なので。順番に見ていきます。
①サポート期限:2016 の延長サポートは 2026年7月で終わる
レガシー現場が今いちばん効くのは、正直ここ。新機能の話より先に、これです。
SQL Server 2016 の延長サポートは 2026年7月14日で終わる。Microsoft のライフサイクルにそう書いてあります。メインストリームサポートはとっくに終わってて、今は延長サポートの最後の数ヶ月。そういう状態なんですよね。
延長サポートが切れると何が起きるか。新しいセキュリティ修正が出なくなります。バグ修正も止まる。新しい脆弱性が見つかっても、もうパッチは降ってこない。
「社内 LAN の中だけで動いてるし、外に出てないから関係ないでしょ」。思いたくなる気持ちは分かる。でも監査やセキュリティチェックでこれを突っ込まれると、ぐうの音も出ないやつです。「サポート切れの DB を業務基幹で使ってる」。それだけで指摘事項になる。
だから 2016 現場でやるべきことの優先順位は、こうなります。
- 派手な新機能を調べる前に、まず自分の現場の SQL Server のサポート期限を確認する
- 2016 以前なら、2026年7月までに「どこへ動くか」だけ決めておく
- 上げ先は最新の 2025 じゃなくていい。サポートが長くて枯れてる 2019 か 2022 で十分
ここまでが「期限の話」。次が、移行で一番事故るポイントです。
②移行で一番踏む罠:互換性レベルを上げると実行計画が変わる
この記事でいちばん伝えたいのが、ここ。バージョンを上げる作業そのものより、互換性レベルを上げた瞬間に実行計画が変わって、特定のクエリだけ急に遅くなる。これが移行の本丸の罠です。
なんでそうなるか。SQL Server 2014 から「新しい推定エンジン(CE = Cardinality Estimator)」が入りました。CE っていうのは、クエリを実行する前に「この条件だと何行くらい返ってくるか」を見積もる、頭脳の部分。この見積もりをもとに、INDEX を使うか、どの結合方式にするかをオプティマイザが決める。
互換性レベルを 120 以上(2014 以降)に上げると、この CE が新しいやつに切り替わる。多くのクエリは速くなるけど、一部は逆に遅くなる。見積もりの癖が変わるからです。
俺の想像で言ってるんじゃない。ちゃんと書籍にも釘を刺してある話です。
新しい開発では常に最新のモデルを選ぶべきだ。だがアップグレードはもっと厄介になる。最新の推定モデルはモダンなワークロードでより良い結果を出しうるが、実行計画が変わることによる性能リグレッションの可能性が常にある。すべてのワークロードとデータ分布を網羅できるモデルは作れない以上、アップグレード後はシステムを注意深くテストすべきだ。
──『Pro SQL Server Internals』(Dmitri Korotkevitch, p.111・英語原書を日本語訳)
業務 SE 視点で噛み砕くと、「上げたら全部速くなる」と思い込んで無検証で本番に当てるのが一番危ない、ってこと。月次バッチとか、月初にしか走らない重いクエリほど、移行直後は気付かれずに地雷化します。
じゃあどう守るか。同じ本に、移行のときの安全弁がちゃんと書いてある。
SQL Server 2016 では、データベーススコープ構成という新機能で、データベースの互換性レベルに基づくカーディナリティ推定モデルの選択を上書きできる。
ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = ONで旧来の推定エンジンを有効にできる。──『Pro SQL Server Internals』(Dmitri Korotkevitch, p.103・英語原書を日本語訳)
これがめちゃくちゃ効くんですよ!!何が嬉しいかというと、互換性レベルは新しいバージョンに上げたまま、CE だけ旧来の挙動に戻せる。全部か無か、じゃない。新機能は取り込みつつ、推定エンジンが原因の劣化だけ個別に逃がせる。段階移行の逃げ道です。
具体的には、移行はこんな感じの順番でやります。
-- 1. まず Query Store を有効化(これで移行前後の実行計画を記録・比較できる)
ALTER DATABASE [YourDb] SET QUERY_STORE = ON;
-- 2. 互換性レベルを上げる(ここで新CEに切り替わる)
ALTER DATABASE [YourDb] SET COMPATIBILITY_LEVEL = 170;
-- 3. もし新CEで遅くなったクエリが出たら、互換性レベルは上げたまま
-- 旧CEだけ戻す(段階移行の安全弁)
ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = ON;
※
COMPATIBILITY_LEVEL = 170が有効なのは SQL Server 2025 エンジンだけです。まだエンジンを上げてない 2019 / 2022 でこの行を叩くとMsg 15048(対応する互換性レベルの上限は 2019 なら 150、2022 なら 160)で弾かれます。これは「まだ 2025 になってない」というサインなので、先にエンジンを上げてから実行してください。QUERY_STORE = ONとLEGACY_CARDINALITY_ESTIMATION = ONの2行は 2019 / 2022 でもそのまま通ります。
手順 1 の Query Store がポイント。これは移行前後で実行計画がどう変わったかを記録してくれる機能で、「移行してから遅くなったクエリ」をピンポイントで見つけられる。本にもこう書いてあります。
SQL Server 2016 では Query Store という新コンポーネントが使える。これはシステム内の実行計画と実行統計をキャプチャして永続化する。これによりテスト工程を劇的に簡素化でき、性能リグレッションを素早く特定できる。
──『Pro SQL Server Internals』(Dmitri Korotkevitch, p.111, p.614・英語原書を日本語訳)
「実行計画が環境で変わる」現象自体は、CE だけが原因じゃない。日本語の本だと、こっちの説明が現場感あって分かりやすいです。
統計情報は定期的にテーブルから一定数のサンプリングを行い、それをもとに作られます。ただし、「実際のデータ分布から乖離した統計情報」が作られることがあります。(中略)データとクエリはまったく同じなのに、本番とステージングで実行計画が違う場合の原因になることもあります。
──『失敗から学ぶRDBの歩き方』(曽根 壮大, p.62)
要は、移行検証をステージングでやるなら、本番に近いデータ量と分布で、統計情報も更新した状態でやらないと意味がない。データがスカスカのステージングで「速いね」って言っても、本番では別の計画が選ばれて転ぶ。p.52 あたりでも「同じクエリでも WHERE 句の値で INDEX が効いたり効かなかったり」って話が出てて、ここは移行検証の落とし穴とそのまま地続きです。
SQL Server 2025 の新機能で、業務SEが今すぐ気にすべきものは正直ほぼ無い
ここまで「期限」と「移行の罠」を話してきました。じゃあ肝心の 2025 の新機能はどうなん?という話。
結論から言うと、2016 で止まってる普通の業務系現場に、今すぐ刺さる新機能はほぼ無いです。煽らずに正直に言います。
2025 の目玉として挙がってるのは、だいたいこのへん。
- ベクトル型・ベクトル検索:AI / 類似検索向け。RAG とか埋め込み検索をやるなら効く
- ネイティブ JSON 型:JSON を本格的に格納・検索するなら便利
- 正規表現関数:
REGEXP_LIKEみたいなのが標準で書けるようになった - Optimized locking:ロック周りの効率化
- Fabric / Azure 連携の強化:クラウド前提なら
見て分かる通り、上のほうは「AI やクラウドをこれからやる人」向けなんですよ。流通系の基幹で、DataTable と生 SQL でデータを出し入れしてる現場が、来月いきなりベクトル検索を使うかというと、使わない。
正規表現関数あたりは「お、ちょっと便利かも」と思う。けど、それだけのために 2016 → 2025 へ一足飛びする理由にはならない。
だから新機能リストを見て「うちには関係ないな」と感じたなら、その感覚は正しい。新機能が要らないことと、移行が要らないことは別で、移行が必要な理由はさっきの「サポート期限」のほうにある。ここを混同しないのが大事です。
結局、上げる/上げないをどう決めるか
判断材料が出揃ったので、フローに落とします。朝礼で「で、どうするの?」と聞かれた時、この順で考えれば詰まらない。
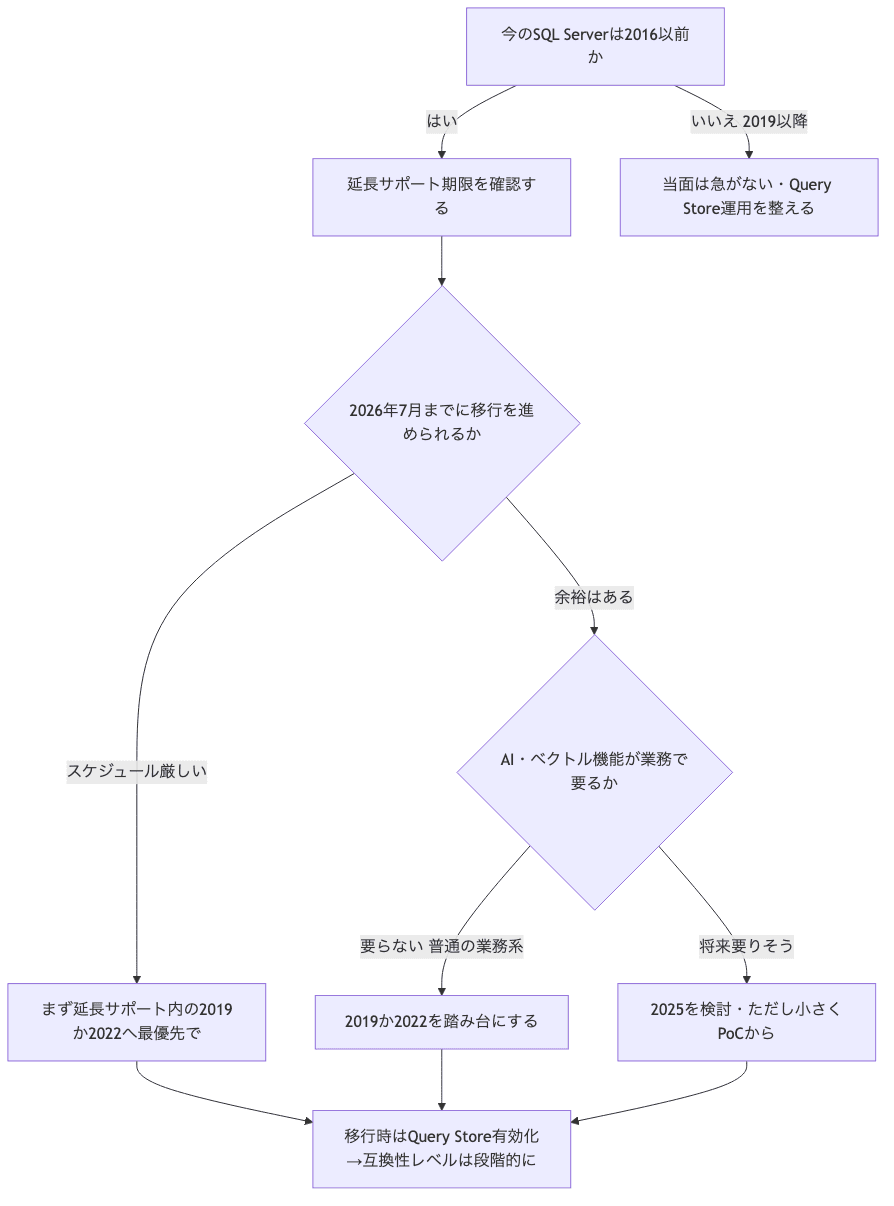
このフローを回す前に、まず自分の現場の「今」を数字で押さえます。互換性レベルが実はバージョンより低く据え置かれてる現場、けっこうあるので。
-- 今のサーバーのバージョンとエディションを確認
SELECT @@VERSION;
-- 各データベースの互換性レベルを確認(バージョンより低いまま放置されてないか)
SELECT name, compatibility_level
FROM sys.databases
ORDER BY name;
実行結果はこんな感じで出ます。
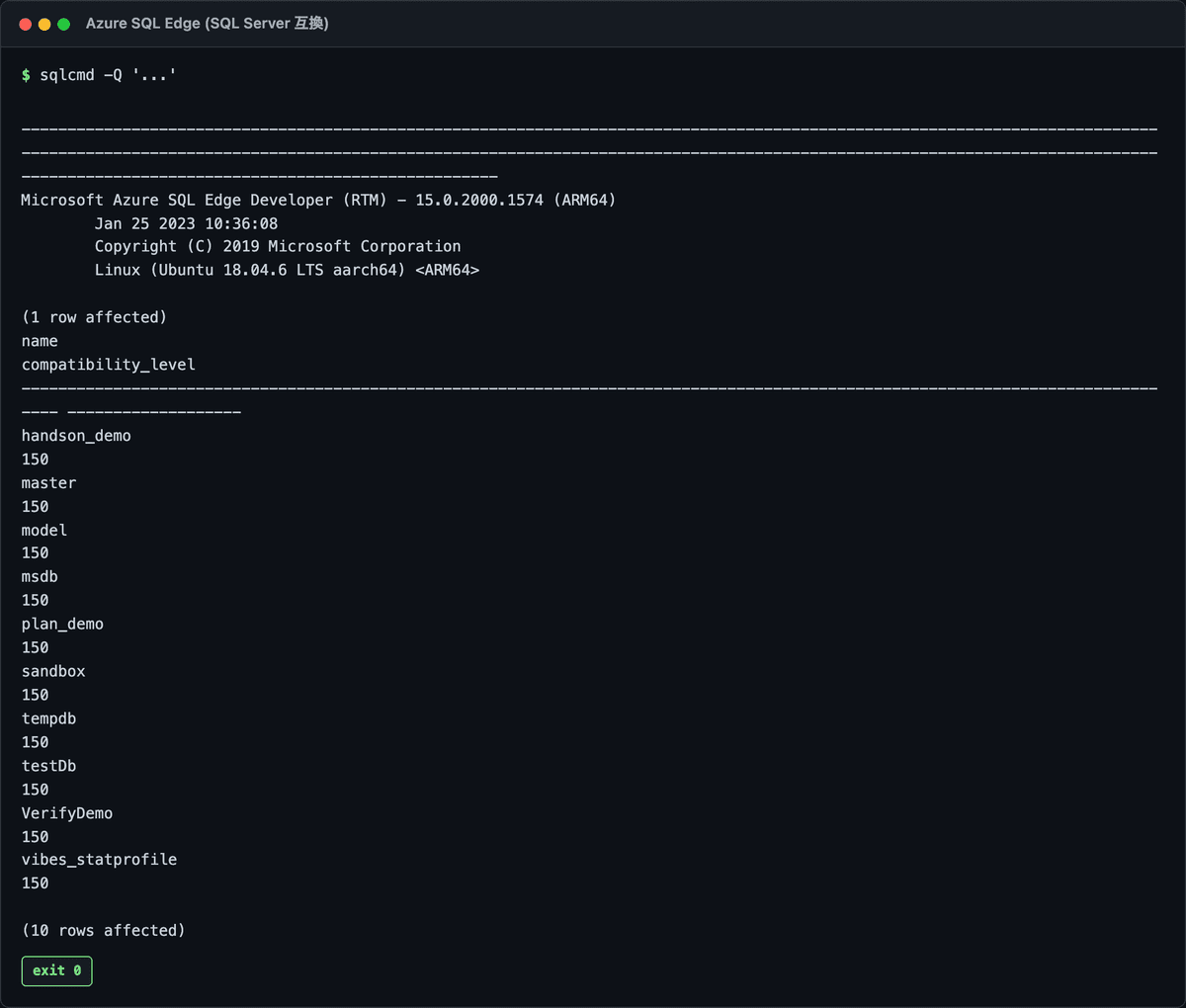
これを叩くと、「サーバーは 2016 なのに、特定の DB だけ互換性レベル 110(2012相当)で動いてた」みたいな事実が出てくることがある。移行のとき、ここを揃えるかどうかでまた挙動が変わるので、現状把握は最初にやっとくと楽です。
俺の現場ではこう考えてる
机上の話だけだと薄いので、現場目線も足しときます。
俺がいた流通系の基幹は、2億レコード超のテーブルを夜間バッチで回してる、わりと重めの環境でした。こういう現場で移行が怖いのは、新機能の習得コストじゃない。月初にしか走らない重いバッチが、移行後に倍の時間かかって、気付くのが翌月になるやつ。これがいちばん寒い。
実際、昔これで痛い目を見たことがあって。互換性レベルを上げた検証を、データの少ない開発機でしかやらずに本番へ当てたら、月初のバッチが想定の倍近く時間を食って冷や汗かいた。原因は、まさにさっきの新CEで結合の見積もりが変わってたやつ。Query Store を先に入れとけば一発で分かったのに、それを知らずに原因究明で丸半日。
だから今は、レガシー現場の移行には「枯れたバージョン+段階移行」を勧めてます。最新は追わない。2019 か 2022 まで上げて、Query Store でクエリを見張りながら、互換性レベルは様子を見て上げる。地味だけど、いい感じに段階を踏めるし、これがいちばん事故らない。
ん?じゃあ結局 2025 はスルーでよくない??と思うかもですが、そうとも言い切れない。AI 連携をやれと言われる日は、業務系現場にもいずれ来る。その時に「うちの DB はまだ動ける状態か」を判断できる目を、今のうちに持っとくと強い。バージョンの選定眼って、地味に効くスキルなんですよ。
ハマりポイント(移行で踏む4つの落とし穴)
移行作業で踏みやすいのは、ざっくり4つ。先に数えとくと心の準備ができるので並べます。各項目の頭に対処の目安時間も付けときました。
1. 互換性レベルを上げ忘れて「上げた気」になる(⏱確認5分)
エンジンを 2022 にしても、データベースの互換性レベルが 130 のままだと、新CEは使われない。「バージョン上げたのに何も変わらない」と首をかしげるやつ。俺もこれで「あれ、効いてなくない??」って 30 分悩んだことがある。さっきの compatibility_level 確認クエリで一発です。
2. 統計情報を更新せずに検証して「速い」と勘違いする(⏱対処30分)
ステージングのデータが古い・少ないと、本番と別の実行計画が選ばれる。「検証では速かったのに本番で遅い」の典型。コストは技術的な手戻りだけじゃない。「検証 OK 出したよね?」と業務側に詰められる、信頼の目減りがきつい。本番に近いデータ量+統計情報の更新まで含めて検証する。
3. 重いバッチの劣化に翌月まで気付かない(⏱予防は事前のQuery Store)
毎日走るクエリは移行直後に気付ける。怖いのは月次・四半期次のやつ。これは Query Store を移行前に有効化して、計画の変化を記録しておくのが唯一の予防策。事後に「なんで遅くなったの」を追うと半日コースです。
4. 全部いっぺんに上げようとして戻せなくなる(⏱段階化で回避)
エンジン・互換性レベル・CE を一気に最新化すると、何が劣化要因か切り分けられなくなる。LEGACY_CARDINALITY_ESTIMATION で CE だけ戻せる安全弁があるんだから、使う。一段ずつ上げて、一段ずつ確認する。
まとめ
長くなったので要点だけ。
- 2016 現場が最優先で気にすべきは延長サポートが 2026年7月14日で切れること。新機能より先にここ
- 移行で一番事故るのは互換性レベルを上げた時の新CEによる実行計画リグレッション。Query Store を先に入れて、劣化したら
LEGACY_CARDINALITY_ESTIMATIONで CE だけ戻す - 2025 の AI・ベクトル系は、普通の業務系現場には今すぐ要らない。移行先は枯れてる 2019 か 2022 が現実的
- レガシーで止まってる自分を「遅れてる」と思わなくていい。判断軸を持って動けるなら、それは遅れじゃなくて堅実です
枯れたバージョンで止まってること自体は、罪じゃない。理由を説明できないまま止まってるのと、判断して止めてるのは、まったく違う。この記事が後者になる手助けになれば、いい感じです。
よくある質問
SQL Server 2016 のまま使い続けたら、すぐ動かなくなりますか?

すぐ止まるわけじゃないです。延長サポートが切れても DB は動き続ける。問題は「新しい脆弱性が見つかってもパッチが出ない」状態になること。社外に開いてない閉域でも、監査で指摘される材料になります。動くかどうかより、説明責任の話。
なぜ最新の 2025 じゃなく、わざわざ古い 2019 や 2022 を勧めるんですか?
新しいバージョンほど、出たばかりは初期不具合や情報の少なさがある。業務基幹は「枯れてる」ことが価値なんですよ。2019 / 2022 はサポート期限も十分長い(2030 / 2033)。AI 機能が要らないなら、わざわざ最前線に立つ理由がない。逆に、AI 連携が要件にあるなら 2025 を PoC から始める、で OK。
互換性レベルは上げずに、エンジンだけ新しくするのはアリですか?
アリです。むしろ移行直後はそれが安全。エンジンを 2022 にして、互換性レベルは一旦 130(2016相当)のまま動かす。これでサポート期限の問題は解消しつつ、実行計画は当面そのまま。落ち着いてから Query Store を見ながら互換性レベルを上げていけばいい。全部いっぺんにやらないのがコツです。
ここまで読んで「バージョンの選定とか移行判断、地味だけど現場で一番頼られるやつだな」と思った人へ。この「枯れた技術を、理由を持って選べる目」って、実は単価にも効くスキルなんですよね。下の記事でその話をしてます。
次に読むべき記事





以上!
この記事の参考文献
この記事の「互換性レベルを上げた時の実行計画リグレッション」と「Query Store・旧CEへの退避」の根拠として、以下の書籍を参照しました。
-
Pro SQL Server Internals(Dmitri Korotkevitch 著 / Apress / 2016 / 引用ページ: p.103, p.111, p.614・英語原書を本文中で日本語訳)
SQL Server の内部構造(ストレージ / インデックス / トランザクション / ロック / 統計情報 / 実行計画)を DBA レベルで掘り下げた技術書。今回はカーディナリティ推定エンジンのアップグレード時リグレッションと Query Store の節を参照しました。 -
失敗から学ぶRDBの歩き方(曽根 壮大 著 / 技術評論社 / 2019 / 引用ページ: p.52, p.62)
RDB の設計・運用・性能チューニングで業務 SE が現場で踏みがちな失敗パターンを実例ベースで網羅。今回は統計情報の乖離で本番とステージングの実行計画が変わる節を参照しました。
執筆者
バイブス父さん — 業務 SE 7 年 (SIer 正社員 2 / フリーランス 5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SIer の正社員からフリーランスに転じ、複数のエージェント経由で案件を回してきた経験ベースで「業務 SE 視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る