みなさんこんにちは!ヒロポンです!
SQL Server の一時テーブル(#temp)・テーブル変数(@table)・CTE。
中間結果をちょっと置いときたい時、この3つ、毎回なんとなくで選んでないですか??
俺は昔そうでした。「変数っぽいしテーブル変数でええやろ」くらいのノリ。
で、夜間バッチが急に遅くなった。原因を追って2時間溶かした。犯人はテーブル変数です。件数が増えた瞬間に実行計画が崩れてた。
この記事では、sql server 一時テーブル まわりで毎回迷うこの3つを、統計情報・スコープ・tempdb 負荷の3軸で業務系の現場目線で切り分けます。各パターンにコピペで試せる最小サンプルと、件数で選ぶ目安つきで。
忙しい人向けに最初にまとめ
- 一時テーブル
#temp— 統計情報を持ち、後からインデックスも貼れる。大量件数・複数回参照ならこれ。ただし tempdb を使うし、再コンパイルを誘発する。 - テーブル変数
@table— 統計情報を持たず、行数が1行と見積もられる。少件数なら身軽。でも大量件数で実行計画が崩れる。 - CTE — 名前付きの使い回しビュー。中間結果は保持されず、参照ごとに再評価される。可読性・1回参照・再帰向き。
3つを分ける判断軸はこの3つ
細かい違いは山ほどある。でも業務系で実際に効くのは、次の3軸だけです。
- 統計情報を持つか — オプティマイザが行数を正しく見積もれるか。これが実行計画の質を左右する。
- スコープ — どこまで生きてるか。バッチ越え・トランザクション越えで使えるか。
- tempdb 負荷と再コンパイル — tempdb を圧迫しないか、プラン再コンパイルを誘発しないか。
この3軸で見ると、3つの性格がきれいに分かれます。
順番に見ていきましょう。
一時テーブル(#temp) — 統計情報を持つ優等生、ただし tempdb を食う
まず #temp。いちばん「ちゃんとしたテーブル」に近いやつです。
-- #temp: 統計情報を持ち、後からインデックスや制約も足せる
CREATE TABLE #集計 (区分 char(1), 金額 int);
INSERT INTO #集計 VALUES ('A', 100), ('A', 200), ('B', 50);
CREATE INDEX ix_区分 ON #集計(区分); -- 後付けできる
SELECT 区分, SUM(金額) AS 合計 FROM #集計 GROUP BY 区分;
DROP TABLE #集計;
実行するとこんな感じで、区分ごとに合計(A=300 / B=50)が返ります。
#temp の強みは、統計情報を持つこと。オプティマイザが「この区分は何行くらい」を見積もれるので、件数が増えても実行計画が素直に組まれる。インデックスも後から貼れるし、制約も足せる。スコープもセッション内なら別バッチから参照できる。
弱点は tempdb です。#temp は実体が tempdb に作られるので、多用すると tempdb が混む。
そしてもう一段地味に効くのが、再コンパイル。
これは『Pro SQL Server Internals』(p.525) でも触れられてます。一時テーブルは統計情報が古くなるたびに再コンパイルを誘発しうる、と。統計情報の更新閾値は、500行未満なら500回の変更ごと、500行以上なら「500 + 全体の20%」ごと(互換性レベル130以上だと SQRT(1000 × 行数) の動的閾値も併用される)。
つまり、小さい #temp を高頻度で作って捨ててると、その都度プランが作り直されてCPUを食う。地味にタチが悪い。
本命用途: 数百行を超える中間結果・複数回参照する・インデックスが欲しい時。
避けるべき状況: 数十行レベルの軽い処理でこれを乱発する(tempdb 圧と再コンパイルが無駄)。
💡 tempdb まわりでもっと踏むやつはSQL Server tempdb スピルを業務SEが本番で踏む3箇所にまとめてます。
#temp多用と地続きの話なので、別タブで開いて後で読んでくださいな。
テーブル変数(@table) — 身軽だけど「1行」と見積もられる地雷
次がテーブル変数。@ で始まる、変数っぽいやつ。
-- テーブル変数: 宣言時に主キー/UNIQUE のみ指定可。統計情報は持たない
DECLARE @集計 TABLE (区分 char(1) PRIMARY KEY, 金額 int);
INSERT INTO @集計 VALUES ('A', 300), ('B', 50);
SELECT 区分, 金額 FROM @集計 ORDER BY 区分;
身軽で、宣言したバッチ内で完結するから後始末もいらない。少件数ならこれがいちばん楽です。
でもね。ここに最大の地雷がある。
テーブル変数は統計情報を持たない。そして行数が1行と見積もられる。
これが俺が2時間溶かした犯人でした。
裏付けに『Pro SQL Server Internals』(p.310) を引くと、こう書いてある。
ステートメントレベルの再コンパイルを使わない限り、SQL Server はテーブル変数の行数を1行と見積もる。カーディナリティ推定の誤りは実行計画の中で急速に伝播することが多く、テーブル変数を使うと非常に非効率なプランを生みかねない。統計情報は一切保持されず、オプティマイザはテーブル変数内のデータ分布について何も知らない。
「1行」と思ってるテーブルに、実際は5万行入ってたら、どうなるか。
オプティマイザは「1行なら Nested Loop でいいよね」と組む。でも実際は5万行を相手に Nested Loop を回す。地獄です。
同書 p.314 でも、テーブル変数は低オーバーヘッドで一時テーブルより速い場合もあるが、大量データを入れると単一行推定と統計情報の欠如で非常に非効率なプランになる、と強く警告してる。
俺の解釈だと、これは「件数が読めない中間結果には使うな」ってこと。OLTP の数行〜数十行で完結する処理なら、身軽さが勝ちます。
SQL Server 2019 以降は「テーブル変数の遅延コンパイル」で実際の行数を見てくれるようになった。ただ、現場の互換性レベルが古いと効きません。
ん?じゃあレガシー現場は結局これ踏むやん??って、なりますよね。
なるんです。だから件数が読めないならテーブル変数を避ける、が無難。
ちなみに SQL Server 2014 以降は、宣言時にインラインで非クラスタインデックスも書けます。ただ統計情報は持たないままなので、インデックスを足しても1行推定は変わらない。「indexあるのに遅い」はこれが落とし穴です。
本命用途: 少件数(目安は数百行まで)・関数(TVF)の中・OLTP の軽い処理。
避けるべき状況: 数千行を超える中間結果(実行計画が崩れる)。
CTE — 中間結果を保持しない「使い回しビュー」
3つめが CTE(共通テーブル式)。WITH で始まるやつ。
-- CTE: 名前付きの使い回し。中間結果は保持されず参照ごとに再評価される
WITH 集計 AS (
SELECT 区分, SUM(金額) AS 合計
FROM (VALUES ('A',100),('A',200),('B',50)) AS v(区分, 金額)
GROUP BY 区分
)
SELECT * FROM 集計 WHERE 合計 >= 100;
CTE のいちばん誤解されがちな点。中間結果を物理的に保持しない。
#temp みたいに「一度計算した結果を取っておく」わけじゃない。名前を付けた SELECT を、参照されるたびに毎回実行する。
だから同じ CTE を2回 JOIN すると、その重い集計が2回走る。ここ、踏みやすい。
なので「重い中間結果を何度も参照する」用途には向かない。そこは #temp に落とすほうが速いです。
逆に、CTE が圧倒的に強いのが再帰。組織階層とか連番生成は、CTE の独壇場。
-- CTE の独自の強み: 再帰 (連番生成・組織階層の展開など)
WITH 連番 AS (
SELECT 1 AS n
UNION ALL
SELECT n + 1 FROM 連番 WHERE n < 5
)
SELECT n FROM 連番; -- 1〜5 が返る
これ、#temp やテーブル変数だとループを書かないと出せないやつが、CTE なら宣言的に書ける。いい感じにスッキリします。
本命用途: 可読性を上げたい・1回しか参照しない・再帰が要る時。
避けるべき状況: 重い中間結果を複数回参照する(毎回再評価されて遅い)。
早見表 — 3つの判断軸でまとめて比較
ここまでの話を1枚にまとめます。朝礼や設計レビューで「なんでこれ選んだの?」と聞かれた時の弾薬にどうぞ。
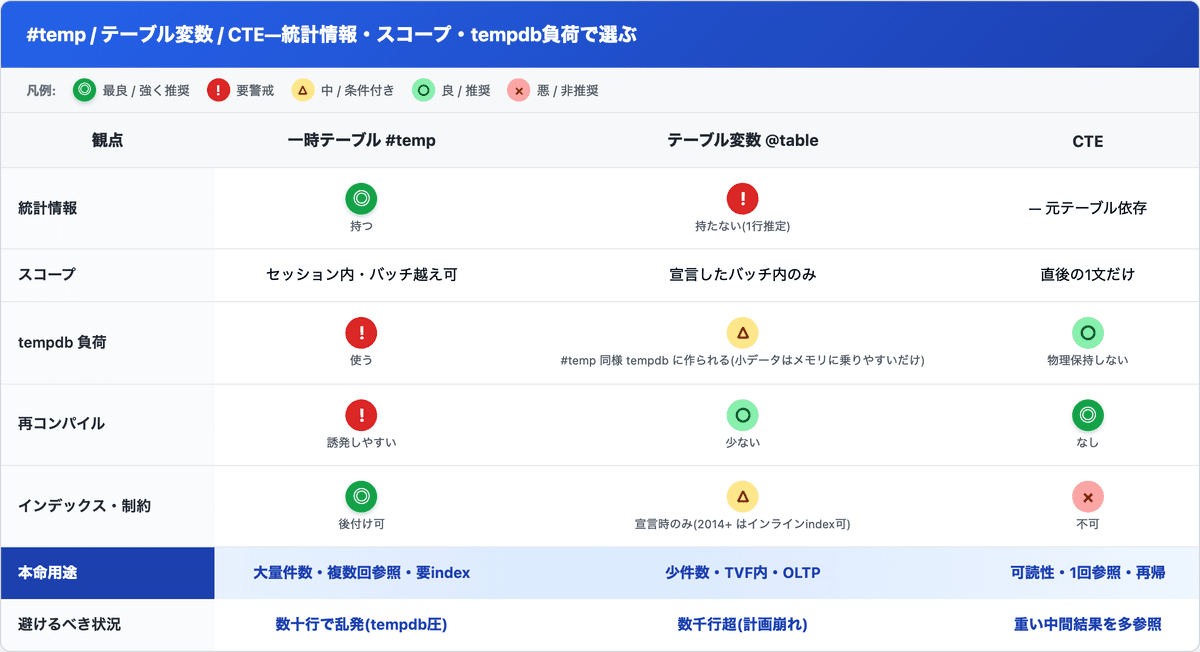
◎ 最良 / ○ 良 / △ 条件つき / × 不可 / ! 要警戒。
件数で選ぶ — 迷ったらこの順で決める
「結局ケースバイケース」で終わらせると、読者(=昔の俺)が困る。だから件数を軸にした決断フローを置いときます。
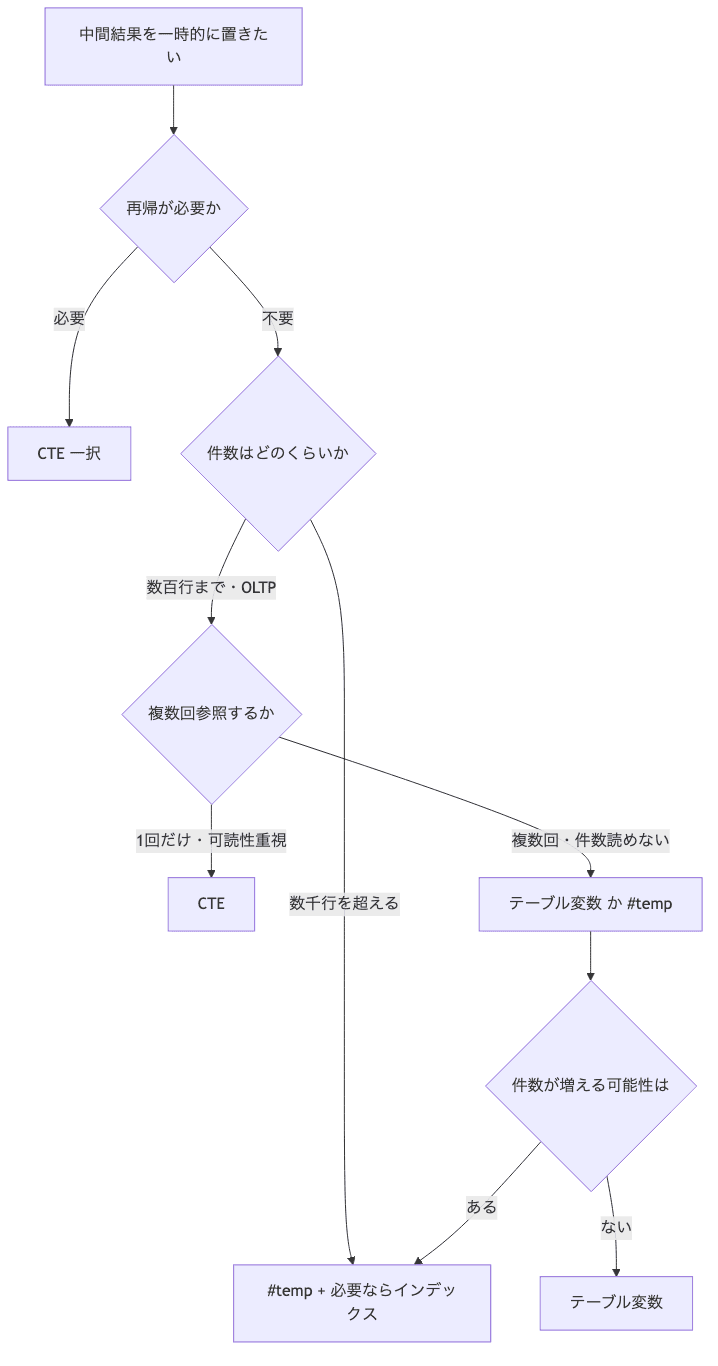
ざっくり言うと、再帰なら CTE、件数が読めない/多いなら #temp、少件数で軽いならテーブル変数。
この3択で振り分けると、業務系の中間結果はだいたいいい感じに片付きます。
俺の現場ではこう使い分けてる
物流系の基幹システムを保守してた頃の話。
夜間バッチで日次集計を回してました。最初はテーブル変数で書いてたんです。それが月初だけ件数が跳ねて、その日だけバッチが3倍遅くなる。これに、しばらく悩まされた。
原因は、さっきの「1行推定」でした。
普段は数十行だから問題なかった。それが月初の数万行で実行計画が崩れてた。#temp に変えて、区分にインデックスを貼ったら安定した。ほっとしました。
逆に、画面の表示用に1回だけ集計を整形するような軽い処理は、今でも CTE で書いてます。可読性が段違いなので。
「件数が読めるか」「何回参照するか」「再帰か」。この3つを頭の中で回して選ぶ。これがいちばん事故らないやり方でした。
まとめ
3つの違いは、突き詰めると「統計情報を持つか」「いつまで生きてるか」「実体をどこに持つか」の差です。
- #temp — 統計情報あり・tempdb 使用・再コンパイル誘発 → 大量件数・複数回参照
- テーブル変数 — 統計情報なし・1行推定 → 少件数・OLTP
- CTE — 物理保持なし・参照ごと再評価 → 可読性・再帰
「変数っぽいからテーブル変数」みたいなノリで選ぶと、件数が跳ねた日に痛い目を見ます。
件数と参照回数で選ぶ。これだけで、夜間バッチが急に遅くなる事故はぐっと減らせます!!
よくある質問
Q1. テーブル変数が大量データに向かないのはなぜですか?

統計情報を持たず、行数が1行と見積もられるからです。実際の件数が多いと、オプティマイザが小さいテーブル前提のプラン(Nested Loop など)を選んでしまい、大量件数でそれを回すことになって遅くなります。件数が読めない・多いなら #temp が安全です。
Q2. CTE と #temp、どっちが速いですか?
ケースによります。CTE は中間結果を保持せず参照ごとに再評価されるので、同じ重い集計を複数回参照するなら #temp に落とした方が速いことが多いです。逆に1回しか参照しない・可読性を上げたいだけなら CTE で十分です。
Q3. テーブル変数でも統計情報が効くようにできますか?
SQL Server 2019 以降の「テーブル変数の遅延コンパイル」なら実際の行数を見てくれます。ただしデータベースの互換性レベルが 150 以上である必要があり、古いレガシー環境では効きません。その場合は OPTION (RECOMPILE) で都度プランを作り直す手もありますが、CPU コストとのトレードオフです。
Q4. CTE は何回でも JOIN していいですか?
書けますが、CTE は参照ごとに再評価されるので、重い CTE を何度も JOIN すると同じ処理が複数回走ります。重い中間結果を多用するなら、CTE ではなく #temp に一度落とす方が安全です。
次に読むべき記事





中間結果の選び方で迷ってる同業がいたら、この記事ぶん投げてやってください。どんどんシェア待ってるぜ!!
以上!
この記事の参考文献
- 『Pro SQL Server Internals』 Dmitri Korotkevitch 著 (Apress, 2016) — 引用ページ: p.310, p.314, p.525
SQL Server の内部構造(ストレージ / インデックス / トランザクション / 統計情報 / 実行計画 / tempdb)を DBA レベルで深掘りした技術書。この記事の「テーブル変数は1行推定で統計情報を持たない」「一時テーブルは再コンパイルを誘発する」という根拠は本書 Chapter 13(Temporary Objects and tempdb)と Chapter 26(Plan Caching)に拠っています。業務で遭遇する性能問題の根本原因を理解したい業務SE / DBA 向けのバイブル。
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る


