
業務 SE が SQL Server INDEX 断片化に手を出す前に見る 3 箇所 — REBUILD / REORGANIZE / 放置の判断軸
みなさんこんにちは!ヒロポンです!!
業務 SE やってると、ある日突然これに踏むやつ。なんで急に??
夜間バッチで普段 5 分のクエリが 50 分。朝の業務開始までに終わらない。
統計情報は更新した。実行計画も変わってない。
ふと sys.dm_db_index_physical_stats を叩いたら、メイン INDEX の断片化率が 90%。
ここで「じゃあ REBUILD だ」と即断すると、ONLINE オプションで地雷踏んだり、ログが膨張して disk full でサービス停止したり、fill factor 戻し忘れて翌週同じ症状ぶり返したり。ろくなことにならない。俺もこれで本番夜中に起こされた口です。
この記事では業務 SE が INDEX 断片化に手を出す前に見ておくべき 3 箇所 (断片化率 / ONLINE オプション / fill factor) と、REBUILD vs REORGANIZE vs 放置の使い分けを整理する。コピペで動く DMV、実行結果 PNG、比較表 PNG 付き。
忙しい人向けに最初にまとめ
- INDEX 断片化は avg_fragmentation_in_percent (外部) と avg_page_space_used_in_percent (内部) の 2 種類があって、業務 SE が見るのは前者
- 判断軸: < 5% は放置 / 5-30% は REORGANIZE / > 30% は REBUILD・ただし
page_count < 1000は ROI ゼロなのでサイズも見る - 一番きついのは技術復旧時間より、夜間バッチが朝までに終わらず業務側に「今朝の月次集計、出ません」と電話で頭下げる 30 分。だから平時のうちに メンテウィンドウと fill factor を仕込むのが本筋
- ONLINE オプションは Enterprise Edition でしか使えない・LOB データで制限あり・Sch-M 瞬間ロックの罠
そもそも INDEX 断片化とは何か
SQL Server で INSERT / UPDATE / DELETE を繰り返すと、INDEX の物理ページがバラバラに配置されていく。これが断片化 (fragmentation)。
断片化には 2 種類ある。
📖『Pro SQL Server Internals』(Chapter 6 / INDEX FRAGMENTATION) ではこう説明されてる:
avg_page_space_used_in_percent は、各ページ上のデータ格納領域がどれだけ使われているかの平均パーセンテージを示す。この値が内部断片化を表す。
avg_fragmentation_in_percent は外部断片化に関する情報を提供する。clustered index を持つテーブルの場合、この値は順序が乱れたページの割合 — つまり、index 上で次に物理的に割り当てられているページが、現在のページの「next page ポインタ」が指すページと異なっている割合 — を示す。
つまり:
- 内部断片化 (
avg_page_space_used_in_percent): 1 ページの中の空き具合。100 に近いほど詰まってる - 外部断片化 (
avg_fragmentation_in_percent): ページ同士の並び順がどれくらい狂ってるか。0% に近いほど物理順に並んでる
業務 SE 視点で見るべきは外部断片化 (avg_fragmentation_in_percent)。これが高いとシーケンシャル I/O が効かなくなって、read-ahead もブロックされる。単純に I/O が遅くなる。
page split が断片化を生む
外部断片化が進む直接の原因は page split。INDEX 順序を保つために SQL Server が「ページの真ん中を裂いて新しいページを差し込む」操作で、ページ間の物理順序がズレる。
fill factor 100 (完全に詰まったページ) に INSERT すると、これがマジで確実に発生する。
📖『失敗から学ぶ RDB の歩き方』では、INDEX 効かない時の典型として:
表の1ブロックを利用するために最低4ブロック取得=ランダムI/O
と書かれてる。断片化が進むと、本来 1 回の I/O で済んだはずが、ブロックがバラけてランダム I/O に化けて、体感性能が数倍遅くなる。
業務 SE が本番で踏む 3 箇所
順に書くとこう。
- 罠①: 断片化率と page_count — 直すべき INDEX か、放置で OK か?
- 罠②: ONLINE オプション — Enterprise / LOB / Sch-M ロックの 3 つの罠
- 罠③: fill factor — 静的か更新多いかで分かれる落とし所
DBA に「INDEX 直してください」だけ投げるとここを全部聞き返される。自分で 1 周見ておくと話が早い。
罠①: 断片化率と page_count の見方
まず最初に見るのが sys.dm_db_index_physical_stats。これ、全 INDEX の断片化率を一発で返してくれる。
📖『Pro SQL Server Internals』(Chapter 6) では実行モードもセットで説明されてる:
sys.dm_db_index_physical_stats は LIMITED、SAMPLED、DETAILED の 3 つの異なるモードでデータを解析できる。LIMITED モードでは、SQL Server は非リーフ index ページを使ってデータを解析する。これは最も高速なモードだが、内部断片化に関する情報は得られない。
SAMPLED モードでは、テーブルが 10,000 個以上のデータページを持つ場合に、SQL Server はテーブルから 1% のデータをサンプリングして統計情報を返す。
業務 SE 視点だと 'SAMPLED' モードが現実解。
LIMITED は外部断片化しか取れない。内部断片化 (page 詰まり) も同時に見たい時は SAMPLED。DETAILED は本番テーブルでは I/O 重くて打てない。
実際に叩く DMV クエリはこれ。
-- 全 INDEX の断片化を一発で返す (SAMPLED モード)
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
si.name AS index_name,
si.type_desc AS index_type,
ps.avg_fragmentation_in_percent AS frag_pct,
ps.avg_page_space_used_in_percent AS page_used_pct,
ps.page_count,
ps.fragment_count,
-- 判断ヒント列
CASE
WHEN ps.page_count < 1000 THEN '放置 (ROI 不足)'
WHEN ps.avg_fragmentation_in_percent < 5 THEN '放置'
WHEN ps.avg_fragmentation_in_percent < 30 THEN 'REORGANIZE'
ELSE 'REBUILD'
END AS suggested_action
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ps
JOIN sys.indexes si
ON si.object_id = ps.object_id AND si.index_id = ps.index_id
WHERE si.name IS NOT NULL
AND ps.page_count > 0
ORDER BY ps.avg_fragmentation_in_percent DESC;
実行結果:

判断軸はこの 4 つだけ。
frag_pct < 5%→ 放置・触ると逆効果のこともfrag_pct 5-30%→ REORGANIZE (オンライン・軽量)frag_pct > 30%→ REBUILD (オフライン or ONLINE Enterprise)page_count < 1000→ 何 % でも放置 (ROI ゼロ)
page_count < 1000 の条件は Microsoft のメンテプラン公式ガイドにも入ってる。サイズが小さいと、断片化の影響より REBUILD のオーバーヘッドの方が大きい。100 ページしかない INDEX を REBUILD しても体感ゼロ。
断片化判定フロー
ここまでの判断軸を 1 枚にまとめる。
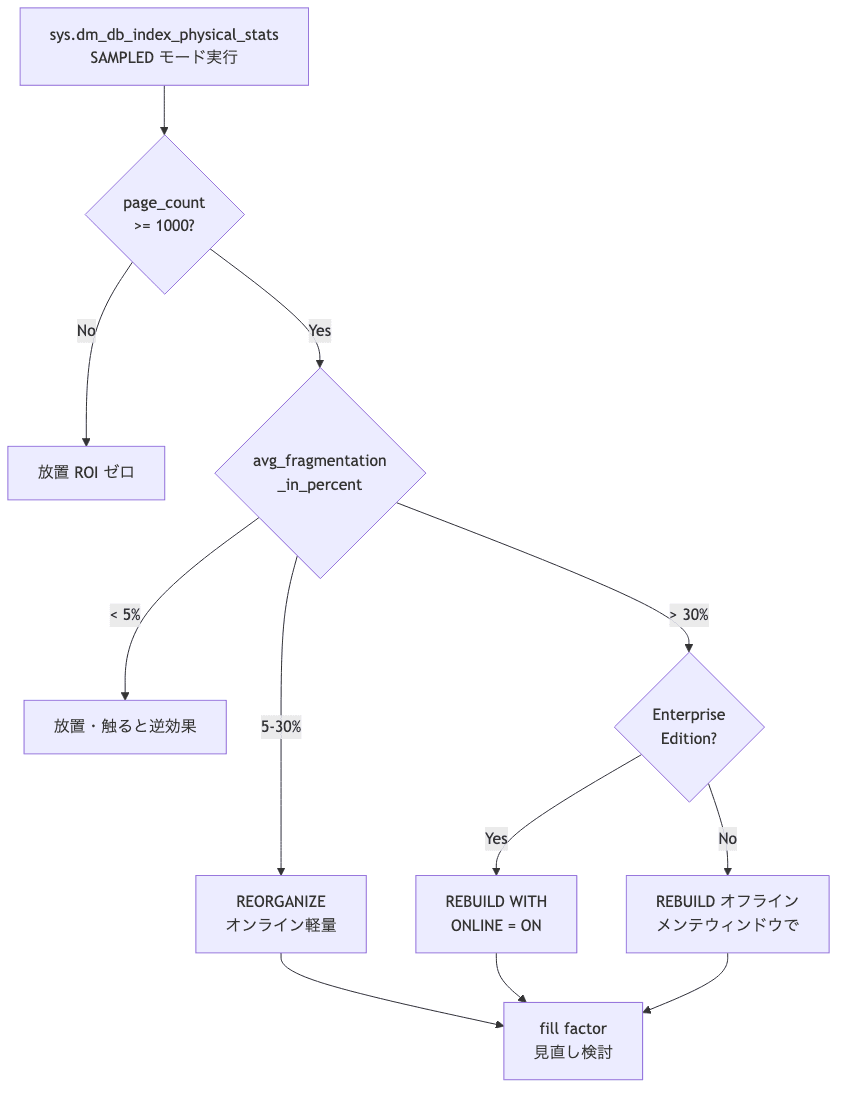
業務 SE はこの 1 枚を SSMS の隣で開いておくと迷わない。
罠②: ONLINE オプション — Enterprise / LOB / Sch-M ロックの 3 つの罠
罠① で REBUILD 対象が見つかった。「じゃあ ONLINE で打てば本番止めなくていいんでしょ?」と思いがち。
でも ONLINE オプションには 3 つの罠がある。
ん? ONLINE で打てば本番止めずに済むんじゃないの??
そう思うのは正常。でも実態は「条件付きで使える」。順に確認する。
罠 2-a: Enterprise Edition 専用 (Standard では使えない)
ONLINE オプションは長年 Enterprise Edition でしか使えない機能だった。Standard Edition では REBUILD WITH (ONLINE = ON) は構文エラーになる (SQL Server 2017 / 2019 で一部緩和されたが、制約あり)。
業務 SE の現場で意外と多いのが「ライセンスは Standard なのにメンテプランに ONLINE 入れてあって本番でコケる」やつ。SSMS の GUI でメンテプラン作る時に、GUI チェックボックスが ONLINE オプションを勝手に入れてくる場合がある。
メンテプランの T-SQL 出力を目視で確認しておくのが定石。
罠 2-b: LOB データを含む INDEX は ONLINE 制限あり
varchar(max) / nvarchar(max) / text / ntext / image / xml 等の LOB 型カラムを含むクラスタ化 INDEX は、SQL Server のバージョンによって ONLINE 対応状況が変わる。
| SQL Server | LOB を含むクラスタ化 INDEX の ONLINE REBUILD |
|---|---|
| 2008-2008 R2 | × 不可 |
| 2012 / 2014 | △ 一部 LOB 型のみ可 |
| 2016+ | ○ 大半可 (ただし制限あり) |
業務系のテーブルで「備考」「メモ」列に varchar(max) 使ってる現場、案外多い。
メンテプランが ONLINE 設定なのにここでコケる事故が起きやすい。メンテ前に該当テーブルのカラム型を INFORMATION_SCHEMA.COLUMNS でチェック。
罠 2-c: Sch-M ロックは ONLINE でも瞬間発生する
ONLINE REBUILD は処理中の大半はオンライン。でも、開始時と終了時に Sch-M (Schema Modification) ロックが瞬間的にかかる。この瞬間、該当テーブルに触ってる全クエリがブロックされる。
これ、「ONLINE = 一切ブロックしない」と勘違いしてると痛い目見る。短いとはいえ Sch-M 中は SELECT も止まる。
実際にロック競合を見るための DMV はこれ。
-- 現在のロック保持状況 (Sch-M / Sch-S を含む)
SELECT
request_session_id AS session_id,
resource_type,
resource_associated_entity_id,
resource_lock_partition,
request_mode, -- Sch-M / Sch-S / S / X / IX 等
request_type,
request_status -- GRANT / WAIT / CONVERT
FROM sys.dm_tran_locks
WHERE resource_type IN ('OBJECT', 'KEY', 'PAGE')
AND request_mode IN ('Sch-M', 'Sch-S', 'X', 'IX')
ORDER BY request_session_id;
実行結果:

REBUILD 実行時に別セッションでこれを叩くと、Sch-M のかかり方が見える。業務時間帯にやる時は「Sch-M で 1-2 秒止まる前提」で業務側に説明しておく。
動作確認メモ: ここで紹介した DMV は Azure SQL Edge container で SELECT 構文の動作確認 + 結果ターミナル PNG 化まで実施済み。本番 SQL Server での REBUILD ONLINE の Sch-M 瞬間ロック挙動は実環境の負荷とトランザクション状態に依存する。開発機の小規模 INDEX では数十ミリ秒で抜けるが、本番 2 億行クラスのテーブルでは数秒オーダーで止まる可能性ありなので、平時にスナップショットを取って傾向を把握しておくのが現実的。
罠③: fill factor の決め方
罠① と罠② で「直すべき INDEX」と「直し方」は決まった。ここで終わりにすると翌週同じ症状がぶり返す。
直接の原因は fill factor の戻し忘れ / 設定ミス。
fill factor は「INDEX ページに何 % まで詰めるか」を決めるパラメータ。デフォルトは 0 (= 100 詰め) もしくは 100。
📖『Pro SQL Server Internals』(Chapter 7 / DESIGNING AND TUNING THE INDEXES) でも page_count・avg_page_space_used_in_percent・avg_fragmentation_in_percent の 3 つを設計指標として扱ってる。fill factor は avg_page_space_used_in_percent の初期値を意図的に下げるチューニング。
静的か更新多いかで分かれる
| テーブル種別 | fill factor 推奨 | 理由 |
|---|---|---|
| 履歴・マスタ (静的) | 100 | UPDATE/INSERT がほぼないので詰めて I/O 効率優先 |
| 業務トランザクション (更新多) | 80-90 | page split を抑えるために事前に空間確保 |
| 中間 (週次更新等) | 90-95 | 中間域・運用見ながら調整 |
100 (デフォルト) のまま運用すると、更新の多いテーブルで page split が多発して、結果として断片化率が短期間で 30% を超える。これが「REBUILD した直後に再び断片化する」やつの正体。
fill factor の現状確認 SQL
-- 全 INDEX の fill factor 現状
SELECT
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
i.type_desc AS index_type,
i.fill_factor, -- 0 は実質 100 と同じ意味
i.is_padded,
si.user_updates AS update_count_since_restart
FROM sys.indexes i
LEFT JOIN sys.dm_db_index_usage_stats si
ON si.object_id = i.object_id AND si.index_id = i.index_id
WHERE i.name IS NOT NULL
AND OBJECTPROPERTY(i.object_id, 'IsUserTable') = 1
ORDER BY si.user_updates DESC;
実行結果:

user_updates が大きい (更新が多い) のに fill_factor = 0 のままになってる INDEX が、page split 多発の犯人候補。ここを 85 とか 90 に下げると、断片化の進行が穏やかになる。
REBUILD と一緒に fill factor を変える書き方
-- 更新多い INDEX を REBUILD + fill factor 85% で再構築
ALTER INDEX [IX_Orders_OrderDate] ON [dbo].[Orders]
REBUILD
WITH (
FILLFACTOR = 85,
ONLINE = ON, -- Enterprise + 非 LOB のみ
SORT_IN_TEMPDB = ON, -- tempdb で並べ替え (本体 DB ログ抑制)
PAD_INDEX = ON
);
SORT_IN_TEMPDB = ON を入れると、REBUILD 中のソート処理が tempdb で行われて、本体 DB のトランザクションログ膨張を抑えられる。
なお tempdb 側の容量を喰うので、tempdb の状態は事前確認 (別記事 SQL Server tempdb スピルを業務 SE が本番で踏む 3 箇所 — 検知と回避の判断軸 で書いた DMV で見ておくと良い)。
業務 SE がやるべき 3 ステップ整理 (DBA に投げる前に)
DBA に投げる前に自分で 1 周見る順番を比較表で並べる。SSMS の隣で開いておけば「今どこ見てる」がブレない。

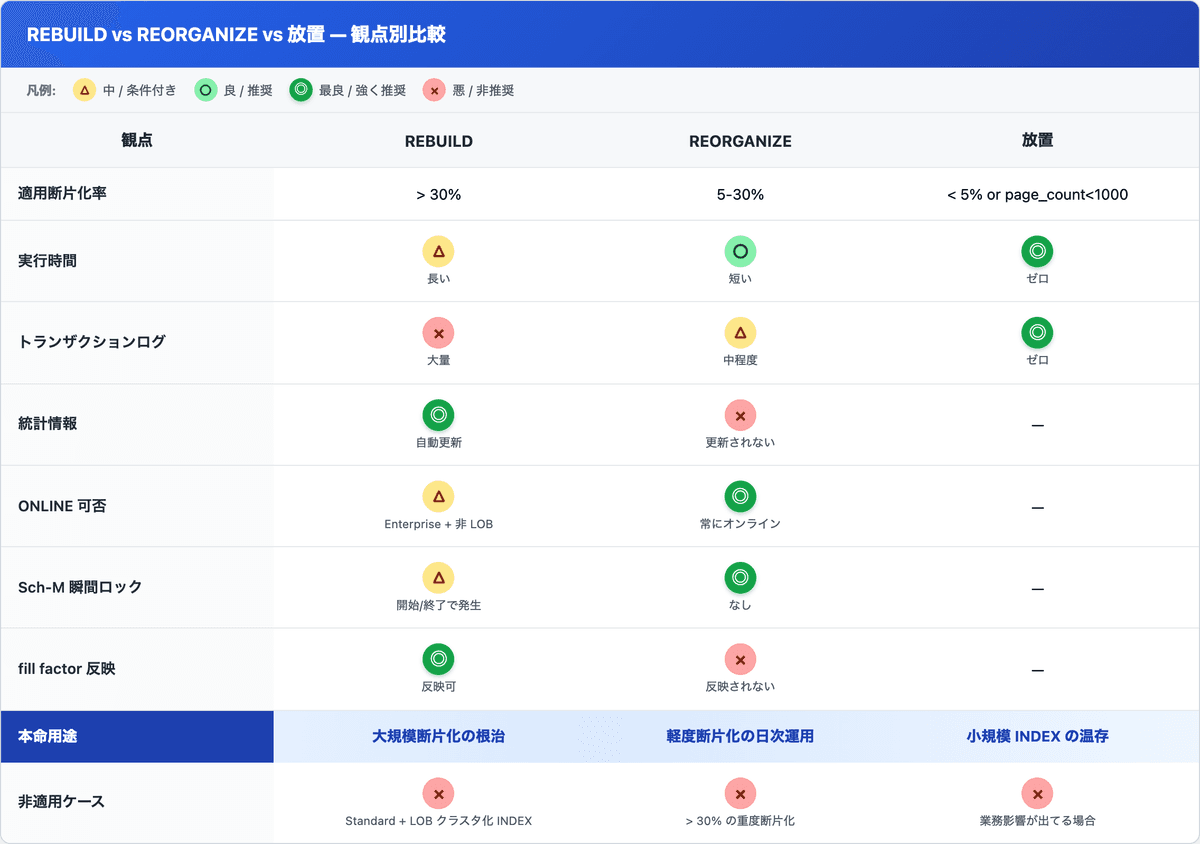
罠③ の fill factor 反映は REBUILD でしか効かないことに注目。REORGANIZE は既存ページ間で並べ替えるだけで、fill factor は変えられない。
だから「fill factor を変更したい時はかならず REBUILD」になる。
俺の現場メモ
物流系の基幹システム保守やってた時の話。月末の在庫集計バッチ (毎月 28 日深夜 2:00 起動) が、ある月から急に 12 分が 80 分になった。統計情報は普通に更新されてた。
最初は「クエリプラン変わったか?」で実行計画を見たけど、ほぼ同じ。ふと sys.dm_db_index_physical_stats を叩いたら、在庫マスタのクラスタ化 INDEX の断片化率が 92%。page_count は約 18,000 で十分大きい。
その日のうちにメンテウィンドウを取って REBUILD WITH (FILLFACTOR = 85, SORT_IN_TEMPDB = ON) 実行。所要時間 7 分。翌月のバッチは 14 分で終わった。
ここまでで技術的には解決。
で、一番きつかったのは復旧 7 分じゃなくて、業務側に「今朝の在庫集計が朝礼までに間に合いません、原因と対策を 30 分以内に説明してください」と電話で言われた瞬間。背中に冷や汗。
技術復旧 7 分 + 業務側への信頼回復 60 分。こっちの方が重い。業務 SE やってる人なら、わかってもらえると思う。
その後 fill factor を 85 にしてからは、月末の断片化率が 30% 前後で頭打ちになって、月次 REORGANIZE で凌げるようになった。平時のチューニングが本番夜中起こされる回数を確実に減らす。実感した案件だった。
まとめ
ここまでで業務 SE が INDEX 断片化に手を出す前に見るべき箇所は揃った。要点を並べると:
- 断片化は 外部断片化 (
avg_fragmentation_in_percent) を見る・内部断片化は補助 - < 5% / 5-30% / > 30% の閾値 +
page_count < 1000除外で判断 - ONLINE オプションは Enterprise + 非 LOB + Sch-M 瞬間ロック許容の 3 条件
- fill factor は 静的=100 / 更新多=80-90 で page split を事前に抑える
- REORGANIZE は fill factor 反映しないので、fill factor 変更時はかならず REBUILD
DBA に「INDEX 直してください」だけ投げると関係が悪くなる。
でも「3 箇所見てきました、罠③ fill factor 100 のままで page split 多発してます。メンテウィンドウで REBUILD + fill factor 85 で OK?」と持っていくと話が一気に速くなる。
こんな感じで現状把握 + 判断軸を持って交渉できるのが業務 SE のアドバンテージなんですよね。
よくある質問
Q1. なぜ REBUILD した直後にまた断片化するの?

A. fill factor が 100 (デフォルト) のままだと、更新の多いテーブルで page split が多発して短期間で断片化が再進行する。REBUILD 時に WITH (FILLFACTOR = 85) のように指定して、ページに余裕を持たせるのが根治策。REORGANIZE では fill factor は反映されないので注意。
Q2. page_count < 1000 の小さい INDEX を REBUILD する意味は本当にない?
A. ほぼない。SQL Server の read-ahead は 64 ページ単位で動くため、1000 ページ未満の INDEX では断片化していてもスキャンが一瞬で終わる。Microsoft のメンテプランガイドでも page_count >= 1000 を REBUILD/REORGANIZE 対象の閾値として推奨している。例外は「小さい INDEX が業務クリティカルクエリの実行計画に直結している」ケースで、これは断片化より統計情報や index design 自体を見直すほうが効く。
Q3. ONLINE = ON で打てば本番中でも安全?
A. 条件付きで安全。① Enterprise Edition であること、② 該当 INDEX が LOB 型カラムを含まない (or SQL Server バージョンが対応している) こと、③ Sch-M 瞬間ロックで数秒のブロッキングが発生する可能性を業務側に共有していること、この 3 つが揃って初めて「安全」と言える。Standard Edition で ONLINE 構文を打つと即構文エラーで失敗する。
Q4. REORGANIZE は何回繰り返しても劣化しない?
A. ほぼ劣化しない。REORGANIZE はリーフページ間の並べ替えと圧縮を漸進的に行うだけで、トランザクションログも REBUILD より大幅に少ない。日次 / 週次のメンテで気軽に回せる軽量オペレーション。ちなみに 30% を超えた断片化を REORGANIZE で 1 回で解消するのは難しいので、そうなる前に REBUILD で根治しておく。
Q5. fill factor を 70 みたいに低くするとどうなる?
A. page split は確かに減るが、同じデータ量を保持するのにページ数が増える → ストレージ消費と I/O 量が増えて、読み取り性能が落ちる。fill factor の落とし所は 80-90 が現実解で、70 まで下げるのは page split が極端に多発しているケース (例えば連番でないキーで大量 INSERT が来るテーブル) に限る。業務 SE が手探りで設定するなら 90 から始めて、月次の断片化率を見ながら 5 ずつ下げる運用がおすすめ。
関連記事





以上!
同じ罠でハマってる人いたら、どんどんシェア待ってるぜ!!
この記事の参考文献
ここまでの知見は以下の書籍から引用しています。 業務 SE 視点で再構成していますが、 元の体系的な知識を学ぶには各書籍を直接読むのがおすすめです。
📖『Pro SQL Server Internals』— Dmitri Korotkevitch
引用範囲: Chapter 6 (INDEX FRAGMENTATION) / Chapter 7 (DESIGNING AND TUNING THE INDEXES)
本の特徴: SQL Server のストレージエンジン・index 内部構造・統計情報・実行計画の挙動を、DMV と実機検証ベースで網羅した洋書の決定版。sys.dm_db_index_physical_stats の LIMITED/SAMPLED/DETAILED モード差、avg_page_space_used_in_percent / avg_fragmentation_in_percent / page_count を設計指標として扱う観点まで、業務 SE が本番で踏む箇所の「なぜそうなるか」を 1 冊で押さえられる。
こんな人におすすめ: SQL Server を業務で扱う SE / DBA・DMV と実行計画でパフォーマンスチューニングを内製したいエンジニア・英語の技術書に抵抗がない人
(アフィリエイトリンク準備中)
📖 『失敗から学ぶRDBの歩き方』 — 曽根 壮大
引用範囲: p.56 / p.62 / p.66
本の特徴: RDB の設計・運用・性能チューニングで「業務 SE が現場で踏みがちな失敗パターン」 を実例ベースで網羅。 BTree インデックス / 統計情報 / 実行計画乖離など、 SQL Server 案件でも直接効く知識多数。
こんな人におすすめ: 業務 SE / DBA / DB 設計担当・SQL を業務で書くエンジニア全般
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る



