
SQL Server の EXISTS と IN の使い分け — NOT IN で NULL に泣かない3パターン
みなさんこんにちは!ヒロポンです!
「マスタに登録済みの明細だけ抽出して」。業務でよくある存在チェック。
これ、EXISTS でも IN でも JOIN でも書けるんですよね。
じゃあ何が違うん??同じ結果が出るなら、どれでもよくない?
よくないんです。
特に NOT IN は、サブクエリに NULL が1件混ざるだけで結果が全件消えるという地雷を踏みます。本番でデータが丸ごと消えて青ざめる、あれ。
今回は、EXISTS が「そもそも何を判定してるのか」から始めて、IN との違い、JOIN で重複が増える理由、そして NOT IN の NULL 地雷とその回避まで、業務SEが納得して選べるように積み上げます。
そもそも「存在するか」をどう聞いているのか
まず前提から。
「ある明細の商品が、商品マスタに登録されているか」を SQL で聞く方法は、大きく3つあります。
EXISTS— マスタに該当行が1個でもあるか、を相関サブクエリで聞くIN— 明細の商品IDが、マスタの商品ID一覧に含まれるか、を聞くJOIN— マスタと突き合わせて、繋がった行だけ残す
どれも「存在するか」を聞いてるんですが、聞き方が違う。
聞き方が違うと、重複の出方も、NULL の扱いも、速さも変わってくる。ここを腑に落とすのが今回の目的です。
以降のコードは、こんな感じの土台で動かします。商品マスタには、わざと「ProductId が NULL の汚い行」を1件混ぜてあります。現場ではよくあるやつ。
-- 注文明細 (ProductId 300 はマスタに未登録)
CREATE TABLE dbo.OrderDetails (DetailId INT PRIMARY KEY, ProductId INT NOT NULL);
INSERT INTO dbo.OrderDetails VALUES (1, 100), (2, 200), (3, 300);
-- 商品マスタ (ProductId が NULL の行を1件まぜてある)
CREATE TABLE dbo.Products (ProductId INT NULL, Name NVARCHAR(20));
INSERT INTO dbo.Products VALUES (100, N'りんご'), (200, N'みかん'), (NULL, N'不明');
-- 商品タグ (商品100に2タグ → あとで JOIN の重複の種になる)
CREATE TABLE dbo.ProductTags (ProductId INT, Tag NVARCHAR(20));
INSERT INTO dbo.ProductTags VALUES (100, N'fruit'), (100, N'sale'), (200, N'fruit');
ここまでで分かったこと: 存在チェックには EXISTS / IN / JOIN の3つの聞き方がある。聞き方で挙動が変わる、というのがこの先の本題。
EXISTS と IN は何が違うのか
まず素直な存在チェックから。EXISTS と IN を並べます。
-- EXISTS: マスタに該当行があるか。相関サブクエリで聞く
SELECT d.* FROM dbo.OrderDetails d
WHERE EXISTS (SELECT 1 FROM dbo.Products p WHERE p.ProductId = d.ProductId);
-- IN: 明細の ProductId が、マスタの ProductId 一覧に含まれるか
SELECT d.* FROM dbo.OrderDetails d
WHERE d.ProductId IN (SELECT ProductId FROM dbo.Products);
どちらも結果は DetailId 1, 2。ProductId 300 はマスタに無いので除外されます。
この向き(存在する方)では、EXISTS と IN は同じ結果。
違うのは中の動きです。
EXISTS は 相関サブクエリで、明細1行ごとに「マスタに該当が1個でもあるか」を確認して、1個見つけた時点で打ち切ります。セミジョインと呼ばれる動きですね。IN のほうは、サブクエリの結果リストと値を突き合わせる。
結果が同じなら好みでよくない??って思いますよね。
でも後半の NOT 形で運命が分かれます。そこが本題です。
ここまでで分かったこと: 存在する方の判定では EXISTS と IN は同じ結果。EXISTS は「1個見つけたら打ち切る」相関サブクエリ。
JOIN で書くと何が起きるか
存在チェックを JOIN で書く人も多いです。
でも JOIN には、存在チェックには無い副作用がある。突合先に複数行あると、行が増えるんですよね。
-- JOIN: 明細を ProductTags に繋ぐと…
SELECT d.* FROM dbo.OrderDetails d
INNER JOIN dbo.ProductTags t ON t.ProductId = d.ProductId;
実行結果:

ProductTags には商品100のタグが2件(fruit / sale)あります。すると DetailId 1 が 2回 出てくる。明細は1行のはずなのに、タグの数だけ増殖するんです。
存在を聞きたいだけなのに、JOIN だと「繋がった分だけ行が出る」。これが EXISTS との決定的な違い。
EXISTS は「あるか / ないか」しか見ないので、繋がる相手が何件いようと 行は増えません。
「マスタの列も一緒に取りたい」なら JOIN でいい。でも「存在するかだけ知りたい」なら EXISTS のほうが事故りません。
ここまでで分かったこと: JOIN は突合先が複数あると行が重複する。存在チェックだけなら EXISTS(行が増えない)が安全。
NOT IN が NULL で全件消える罠
ここが今回の山場です。
「マスタに 無い 明細を出したい」。素直に NOT IN で書きますよね。
-- NOT IN: マスタに無い明細を出したい (期待は DetailId 3)
SELECT d.* FROM dbo.OrderDetails d
WHERE d.ProductId NOT IN (SELECT ProductId FROM dbo.Products);
実行結果:

期待は DetailId 3(ProductId 300 はマスタ未登録)。
でも実際に返るのは 0行。1行も出ません。
原因は、マスタに混ぜておいた ProductId = NULL の行です。SQL の比較は 三値論理(TRUE / FALSE / UNKNOWN)で動いていて、何かと NULL を比べた結果は UNKNOWN になる。
300 NOT IN (100, 200, NULL) は、中で 300 <> 100 AND 300 <> 200 AND 300 <> NULL に展開されます。最後の 300 <> NULL が UNKNOWN。TRUE AND TRUE AND UNKNOWN は UNKNOWN になって、WHERE は TRUE の行しか返さないので、この明細は消えます。
サブクエリに NULL が1件でも混ざると、NOT IN は全件これをやらかす。マジでタチ悪いやつ。
回避はシンプルで、NOT EXISTS に書き換えるだけです。
-- NOT EXISTS: NULL に強い。期待どおり DetailId 3 が返る
SELECT d.* FROM dbo.OrderDetails d
WHERE NOT EXISTS (SELECT 1 FROM dbo.Products p WHERE p.ProductId = d.ProductId);
実行結果:

NOT EXISTS は「該当行が無いか」を見るだけで、NULL との値比較をしません。だから NULL が混ざっても巻き込まれない。
これで DetailId 3 がちゃんと返ります!!
事故の流れを図にすると、こんな感じです。
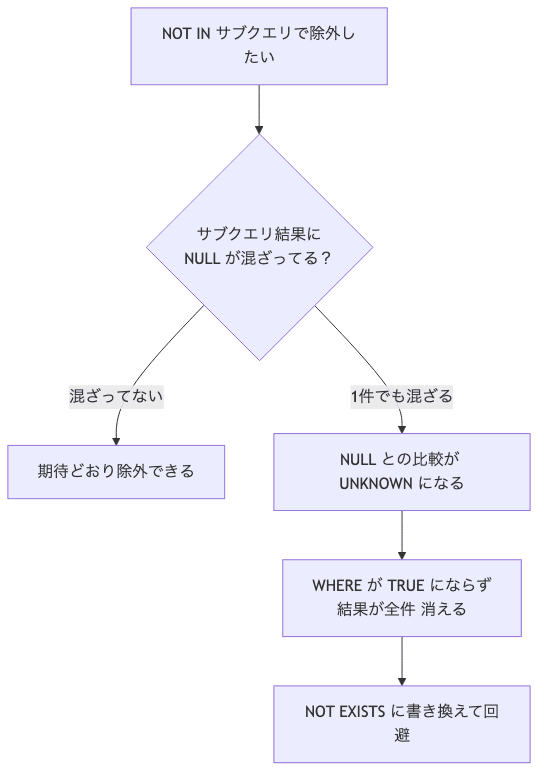
ここまでで分かったこと: NOT IN はサブクエリに NULL が1件でも混ざると三値論理で全件落ちる。NULLable な列を相手にする否定の存在チェックは NOT EXISTS で書く。
使い分けの早見表
3手法の性格を1枚にすると、こんな感じになります。

IN は「WHERE ProductId IN (100, 200, 300)」みたいに少数の固定リストを相手にするときが本領です。
サブクエリ相手の存在チェック、特に否定形は EXISTS / NOT EXISTS に寄せておくのが無難。
俺の現場ではこう使ってる
業務系の現場だと、マスタと明細の突合は毎日のように出てきます。
昔の俺は、存在チェックを何も考えず IN / NOT IN で書いてました。動くから。
テストデータは綺麗で NULL なんて無いから、開発機では普通に通るんですよね。
事故ったのは、本番のマスタに「移行時に紛れ込んだ NULL 行」が1件あった案件。NOT IN で抽出してた夜間バッチが、ある日から急に 0件 を返すようになって、後続処理が空振り。
朝、業務側から「データ来てないんですけど」の内線。原因にたどり着くまで、ログとデータをだいぶ往復しました。背中に汗かきながら。
今だったら「あ、サブクエリに NULL 混ざったな」って一発で分かる話なんですよ?
でもね。。当時は NOT IN がそんな地雷を踏むなんて、頭の片隅にもなかったんですよね。
それ以来、否定の存在チェックは問答無用で NOT EXISTS、肯定でも基本は EXISTS に寄せる、と決めてます。IN を使うのは値が手書きの固定リストのときだけ。
これだけで「データが消える / 増える」系の事故が、いい感じに無くなりました。マジで楽になった。
まとめ
EXISTS / IN / JOIN の使い分け、整理するとこうです。
- 肯定の存在チェックは
EXISTS— 1個見つけたら打ち切る相関サブクエリ。行も増えない INは少数の固定リスト相手のときだけ — サブクエリ相手、特に否定形は避けるJOINは突合先の列も欲しいとき — ただし突合先が複数行あると重複が増えるので注意- 否定の存在チェックは
NOT EXISTS—NOT INはサブクエリのNULL1件で全件消える(三値論理の罠)
「存在するか」を聞くだけのつもりが、書き方で結果が変わる。
聞き方の性格を押さえておけば、本番でデータが消える事故は避けられます。
よくある質問
Q1. EXISTS と IN、肯定形ならどっちでもいい?

結果は同じになります。
ただ EXISTS は最初の1個で打ち切る相関サブクエリで、大きいテーブルでは有利なことが多いです。IN はサブクエリ結果との突合になる。迷ったら EXISTS に寄せておくと、否定形(NOT EXISTS)に切り替えるときも一貫して書けます。
Q2. なぜ NOT IN は NULL で全件消えるの?
SQL の比較が三値論理(TRUE / FALSE / UNKNOWN)だからです。
サブクエリの結果に NULL が混ざると、値 <> NULL が UNKNOWN になり、NOT IN 全体が TRUE になれません。WHERE は TRUE の行しか返さないので、結果が全件落ちます。NOT EXISTS は値比較をしないので、この影響を受けません。
Q3. JOIN で重複が出ないようにするには?
突合先のキーが一意(PRIMARY KEY や UNIQUE)なら、JOIN でも重複は出ません。
一意でないテーブルに存在チェック目的で繋ぐと重複するので、その場合は EXISTS を使うか、SELECT DISTINCT で潰します。ただし「存在チェックだけ」なら最初から EXISTS のほうが素直です。
Q4. NOT IN はもう使わない方がいい?
サブクエリ相手で、その列が NULL を含みうるなら避けるべきです。
逆に、WHERE Status NOT IN ('A', 'B', 'C') のように 手書きの固定リストで NULL を含まないことが確実なら、NOT IN でも問題ありません。リスクは「サブクエリ + NULLable 列」の組み合わせに集中しています。
関連記事





以上!
「NOT IN で本番が空振りした」経験ある人いたら、どんどんシェア待ってるぜ!!
執筆者
バイブス父さん — 業務SE 7年(SIer 正社員2 / フリーランス5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SIer の正社員からフリーランスに転じ、複数のエージェント経由で案件を回してきた経験ベースで「業務SE視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524(日々の現場メモ更新中)
📝 About Me で経歴詳細を見る


