
みなさんこんにちは!ヒロポンです!
SQL Server の CAST と CONVERT、普段なんとなく使ってますよね。俺もそうでした。
型を変えるだけの地味な関数。エラーなんて出るわけない、と思ってた。
でも本番でだけ、これが牙を剥く。
朝イチの集計バッチで数字が合わない。前日まで動いてたクエリが急に「変換に失敗しました」で止まる。原因を追ったら sql server cast convert まわりの型変換だった、っていうのは業務系あるあるなんですよね。
この記事では、CAST / CONVERT で業務系の現場が本番でやらかす型変換の落とし穴を3つに絞って出します。暗黙変換・カルチャ依存・桁あふれ。それぞれ「どう転ぶか」「なぜ転ぶか」「コピペで効く回避」の順で。最後に TRY_CONVERT での逃がし方と早見表も置いときます。
忙しい人向けに最初にまとめ
- 落とし穴1: 暗黙変換 — 文字列カラムを数値で比較すると、カラム側に
CONVERT_IMPLICITがかかってインデックスが効かなくなる (non-SARGable)。条件は型を揃えて書く。 - 落とし穴2: カルチャ依存 —
CONVERTでスタイル番号を省くと、セッションの言語設定で日付がmdy/dmyに化ける。スタイル23か ISO 形式を明示する。 - 落とし穴3: 桁あふれ・変換不能 —
CAST('300' AS tinyint)は範囲外で実行時に落ちる。1行の不正データでバッチ全体が止まる。TRY_CAST/TRY_CONVERTで NULL に逃がす。
⏱ 対処目安サマリ
着手前に「どれが何分で潰せるか」を先に出しときます。朝礼までに直したい人向け。
| 落とし穴 | 主な症状 | ⏱ 対処目安 |
|---|---|---|
| 1. 暗黙変換 | 本番だけ遅い / たまに変換エラー | 15分 (条件の型を揃える) |
| 2. カルチャ依存 | 日付が別の月になる / 環境で結果が違う | 10分 (スタイル番号を明示) |
| 3. 桁あふれ・変換不能 | バッチが途中で落ちる | 20分 (TRY_系に置換 + 既定値) |
全部それぞれ別の現場で踏んできました。順番に行きます。
1. 暗黙変換でデータ型の優先順位に足をすくわれる
俺はこれで朝の集計が合わなくて30分溶かしたことがある。
会員コードが文字列なのに、条件をうっかり数値で書いてたやつです。
会員コードみたいな「数字に見えるけど文字列」のカラム、業務系だと山ほどありますよね。ゼロ埋めの '0012' とか、英字混じりの 'A015' とか。
ここに数値リテラルで条件を書くと、SQL Server が勝手に型を揃えにいく。これが暗黙変換です。
問題は、どっち側が変換されるか。SQL Server にはデータ型の優先順位ってルールがあって、int は varchar より優先順位が高い。
なので文字列カラムのほう、つまり列側が int に変換される。再現するとこうなります。
-- 会員コードは varchar。数字に見えるけど文字列
CREATE TABLE #会員 (会員コード varchar(10) PRIMARY KEY, 氏名 nvarchar(50));
INSERT INTO #会員 (会員コード, 氏名)
VALUES ('0001', N'田中'), ('0012', N'佐藤'), ('A015', N'鈴木');
-- NG: 文字列カラムを数値で比較 → 会員コード側が int に暗黙変換される
SELECT * FROM #会員 WHERE 会員コード = 12;
実行するとこうなります(列名は表示の都合で半角にしてます)。
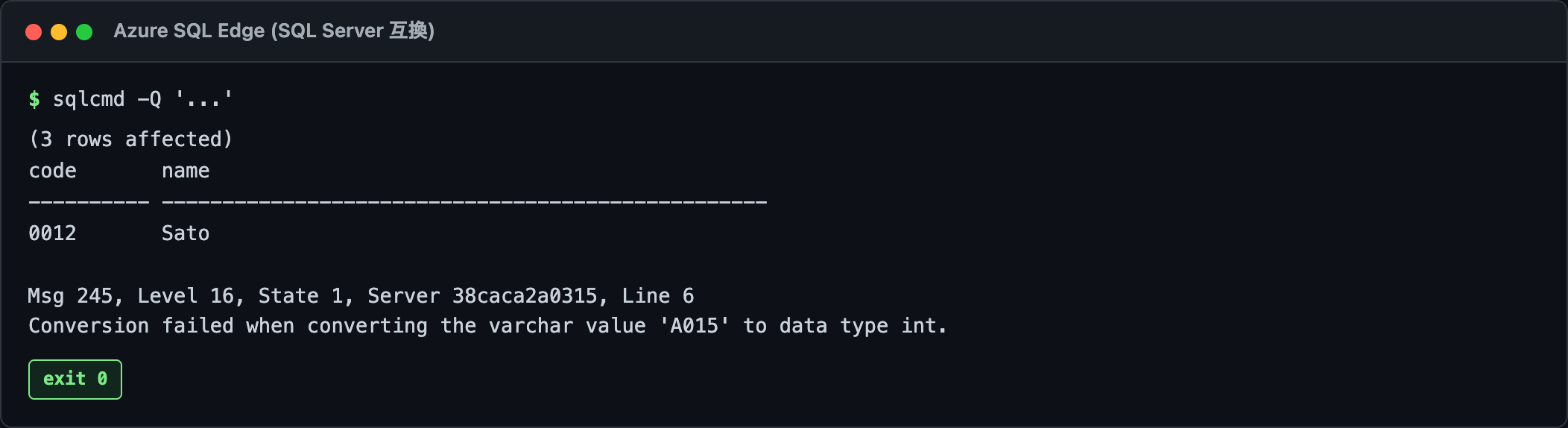
これ、'A015' が int に変換できなくて落ちます。「varchar の値 'A015' を data type int に変換できませんでした」ってやつ。
しかも 'A015' が無くても、列側に変換がかかってる時点でインデックスシークが効かない。全件スキャンです。本番だけ遅い、の正体がこれ。
直し方はシンプルで、条件も文字列で書くだけ。
-- OK: 文字列同士で比較する。暗黙変換が消えてインデックスも使える
SELECT * FROM #会員 WHERE 会員コード = '0012';
この「列側に変換がかかると終わる」って挙動、なんで起きるかを判断フローにするとこんな感じです。
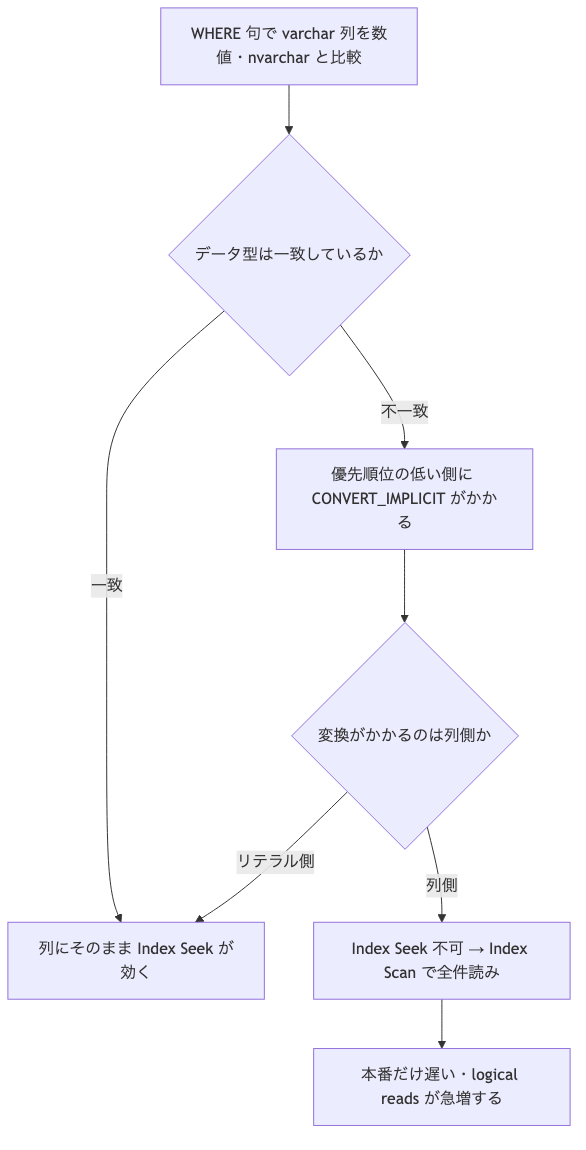
ここ、ちゃんとした裏付けが欲しくて『Pro SQL Server Internals』を引いてみたら、まさにこの話が書いてありました。
unicode 文字列 (nvarchar) のパラメータは、varchar 列に対して non-SARGable になる。これは見た目以上に大きな問題だ。今どきの開発環境はほとんど文字列を unicode として扱うため、SQL Server のクライアントライブラリは、パラメータの型を varchar と明示しない限り unicode (nvarchar) のパラメータを生成する。結果として述語が non-SARGable になり、varchar 列にインデックスが張ってあっても、不要なスキャンによって深刻な性能劣化を招きうる。
ここで言う SARGable (Search ARGument able) ってのは、同書 p.75 の定義で言うと「SQL Server がインデックスシークを使える述語」のこと。逆に non-SARGable になると、いくらインデックスを張っててもシークが効かない。
業務系で刺さるのは「.NET 側の文字列がデフォルトで nvarchar 扱いになる」ってくだり。C# から string でパラメータ渡すと、テーブルの列が varchar でも裏で nvarchar のパラメータが飛ぶ。
で、列側に CONVERT_IMPLICIT がかかってスキャンになる。アプリは何も変えてないのに本番だけ遅い、ってやつの典型がこれなんですよね。varchar 列なら、パラメータ型も varchar で明示してやるのが効きます。
一行教訓: 比較は型を揃えてから。数字に見えるカラムこそ文字列で条件を書く。
実行計画まわりをもっと突っ込んで読みたい人はSQL Server 実行計画の読み方 — Estimated vs Actual で最初に見る5箇所もどうぞ。スキャンに化けてる現場を自分で掴めるようになります。
2. CONVERT のスタイル番号とカルチャ依存で日付・小数が化ける
次は日付。これが地味にいちばん怖い。
エラーすら出ずに、間違った結果が静かに返ってくるやつだからです。
CONVERT で日付の文字列を変換する時、スタイル番号を省くとどうなるか。セッションの言語設定 (DATEFORMAT) に依存します。同じ文字列が環境によって別の日付になる。
-- 同じ '03/04/2026' が、言語設定で別の日付に化ける
SET LANGUAGE us_english;
SELECT CONVERT(datetime, '03/04/2026') AS 解釈; -- 3月4日 (mdy)
SET LANGUAGE British;
SELECT CONVERT(datetime, '03/04/2026') AS 解釈; -- 4月3日 (dmy)
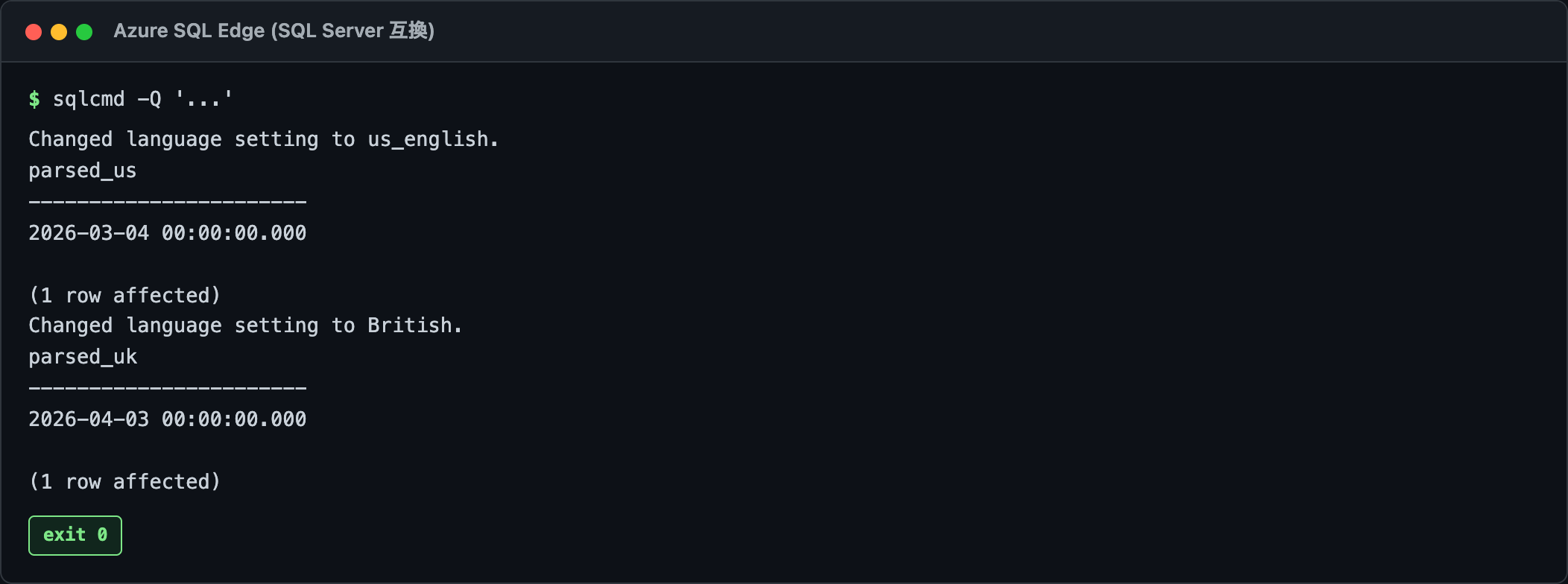
03/04/2026 が、アメリカ英語だと3月4日、イギリス英語だと4月3日。検証環境と本番でサーバーの言語設定が違ってたら、それだけで集計が1ヶ月ズレる。
ん?こんな仕様で本番運用していいんか??って正直思うけど、これが現実です。
回避は、あいまいにならない書き方を明示すること。文字列から日付にするなら、ISO の yyyy-mm-dd 形式を date 型に入れる。これなら言語設定に一切依存しません。日付から文字列にするなら、スタイル番号で書式を固定する。
-- 文字列 → 日付: ISO 形式 (yyyy-mm-dd) を date 型に入れる。言語設定に依存しない
SELECT CONVERT(date, '2026-03-04', 23) AS 確定; -- 2026-03-04
-- 日付 → 文字列: スタイル番号で書式が確定する
SELECT CONVERT(varchar(10), GETDATE(), 23) AS 今日; -- 2026-06-05
SELECT CONVERT(varchar(8), GETDATE(), 112) AS 連番用; -- 20260605
ちなみに '2026-03-04' を datetime 型に入れたい時は、スタイル 23 だと逆に落ちます。datetime の文字列パースに 23 は効かないので、その場合は ISO8601 のスタイル 126 を使うのが正解。
日付から文字列にする方は、23 で 2026-06-05、112 で 20260605 みたいに番号で書式が決まる。ログのファイル名やキー生成で使うなら 112 がいい感じに効きます。
番号を覚えるのが面倒なら、最低限「ISO 形式で書く・スタイルを省いたら負け」とだけ覚えとけば大丈夫。
ロケール依存の文字列を、ちゃんとカルチャを指定して変換したいなら TRY_PARSE っていう手もあります。.NET の書式とカルチャをそのまま使えるやつ。
ただ内部で CLR を呼ぶぶん重いので、大量行をぶん回すバッチには向かない。ここは使い分けですね。
一行教訓: 日付の CONVERT はスタイル番号を省かない。スタイル省略は環境依存のバグ製造機。
3. 桁あふれと変換不能で実行時に落ちる
3つめは、いちばん分かりやすく落ちるやつ。桁あふれと変換不能です。
CAST は、変換できない値を渡すと実行時に例外を投げて止まる。コンパイルは通る。テストデータでは動く。
本番の汚れたデータで初めて落ちる。タチが悪い。
-- 桁あふれ: tinyint は 0〜255。300 は範囲外で実行時に落ちる
SELECT CAST('300' AS tinyint);
-- 変換不能: カンマ入り文字列は int にできない
SELECT CAST('1,234' AS int);
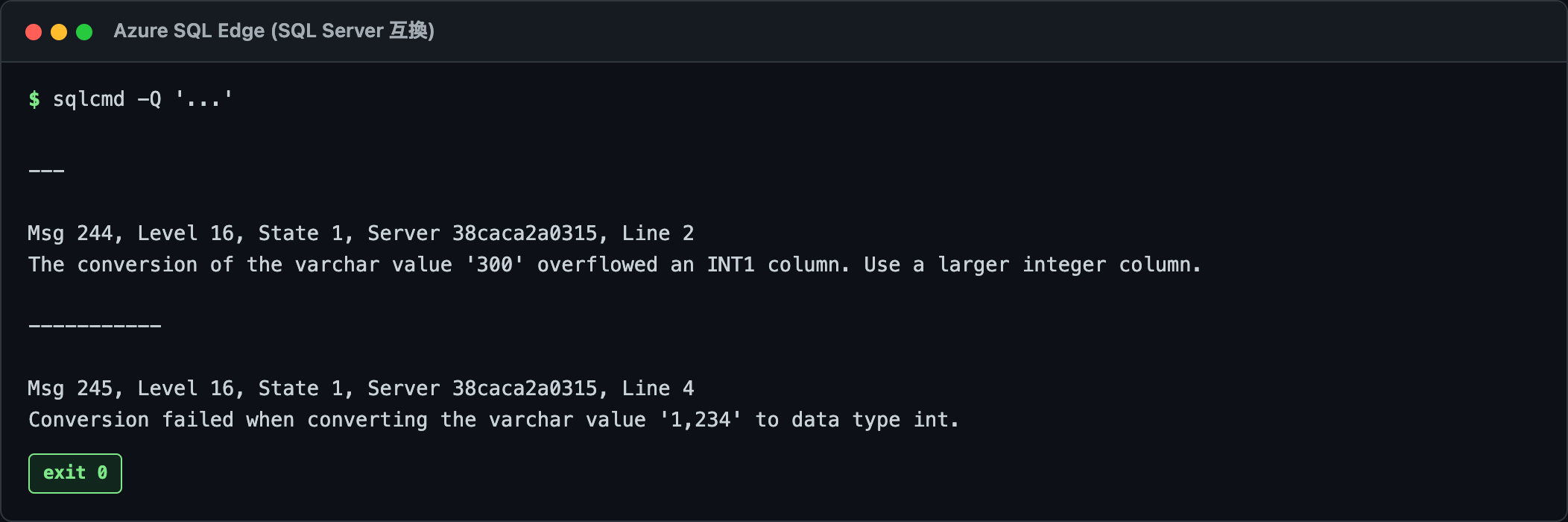
上は「varchar の値 '300' を tinyint (INT1) 列に変換するとオーバーフローしました」系のエラー (Msg 244)、下は「varchar の値 '1,234' を data type int に変換できませんでした」(Msg 245)。
怖いのは、これが SELECT の1列で起きるとバッチ全体が止まること。10万行のうち1行が '1,234' だっただけで、全部こける。
1行のために10万行ぜんぶやり直し??って、まあまあ理不尽ですよね。
ここで効くのが TRY_CAST / TRY_CONVERT。変換に失敗した行を例外じゃなくて NULL で返してくれる。
-- TRY_系は失敗時に NULL を返す。バッチ全体が止まらない
SELECT TRY_CAST('300' AS tinyint) AS 桁あふれ, -- NULL
TRY_CONVERT(int, '1,234') AS 変換不能, -- NULL
COALESCE(TRY_CAST('300' AS tinyint), 0) AS 既定値; -- 0
NULL のまま流したくないなら COALESCE で既定値に逃がす。これで「1行の不正データで夜間バッチが全死」を防げます。TRY_ を付けるだけでこんな感じに守れるから、置換コストもほぼゼロ。
ただし注意が1つ。TRY_CONVERT は「値が変換できない」時に NULL を返すだけで、そもそも型同士が変換不能な組み合わせ (明示的にキャストできない型) を渡すと、NULL じゃなくてエラーになります。
なんでもかんでも握り潰してくれる魔法じゃない。そこだけ頭の隅に。
一行教訓: 外部由来・手入力由来のデータを変換するなら、迷わず TRY_CAST / TRY_CONVERT。
CAST / CONVERT / TRY_CONVERT / TRY_PARSE の使い分け早見表
4つの関数を「書式 (スタイル) 指定 / 失敗時の挙動 / カルチャ指定 / 本命用途・非適用」の軸で並べときます。迷ったらここを見れば選べる、を目指した表です。

◎ 最良 / ○ 良 / △ 条件つき / × 非対応 / ! 要警戒。
ざっくり言うと、普段は CAST、書式が要るなら CONVERT、汚れたデータには TRY_系、ロケール解釈は TRY_PARSE。この4択で業務系の型変換はだいたい片付きます。
まとめ — 暗黙変換に頼らず明示変換を作法にする
3つの落とし穴、根っこは全部同じです。「SQL Server が気を利かせて勝手に型を揃える」ことに乗っかると、本番で足をすくわれる。
- 暗黙変換は、列側に変換がかかってインデックスを殺す → 条件の型を揃える
- カルチャ依存は、スタイル省略で日付が環境依存になる → スタイル番号を明示する
- 桁あふれ・変換不能は、汚れた1行でバッチが全死する → TRY_系で NULL に逃がす
要は、暗黙の変換に任せず、自分で明示的に変換する。これを作法にしとくだけで、夜中に叩き起こされる回数がぐっと減ります。
地味なところほど本番で効くんで、ここだけは覚えて帰ってください!!
よくある質問
Q1. 文字列カラムを数値で比較すると、なぜ本番だけ遅くなるんですか?
データ型の優先順位で文字列カラム側に暗黙変換 (CONVERT_IMPLICIT) がかかり、述語が non-SARGable になってインデックスシークが効かなくなるからです。テストはデータが少なくてスキャンでも一瞬なので気付かず、本番の行数で初めて顕在化します。条件は文字列同士で書きましょう。
Q2. CAST と CONVERT、結局どっちを使えばいいんですか?
書式 (スタイル) を指定する必要がなければ CAST で十分です。ISO 標準に沿った素直な書き方で、可読性も高い。日付や数値を特定の書式で文字列化する、あるいは文字列を特定の書式で解釈する時だけ CONVERT を使う、と覚えておくと迷いません。
Q3. TRY_CONVERT を付けておけば、もう型変換で落ちないですか?
「値が変換できない」ケースは NULL に逃がせますが、万能ではありません。そもそも明示的にキャストできない型同士の組み合わせを渡すと、TRY_CONVERT でもエラーになります。あくまで「不正な値が混じる列の防御」として使うものだと考えてください。
Q4. 暗黙変換が起きているかどうか、どこで気付けますか?
実行計画です。述語のところに CONVERT_IMPLICIT(...) が出ていたら、その列で暗黙変換が走っています。Index Seek のはずが Index Scan になっていたら、まずここを疑います。読み方は実行計画の読み方記事にまとめてあります。
次に読むべき記事
- SQL Server DISTINCT の3つの罠 — 複数列 / NULL / 大量行 — 重複排除で結果がズレる系のもう一つの定番。型変換と同じく本番で化けるやつ
- SQL Server UPDATE … FROM SELECT 3パターン — JOIN / CTE / MERGE の使い分け。更新系で型変換と合わせて踏みやすい
- C# TryParse の正解 — int / DateTime / Enum.TryParse の3つのハマり — アプリ側でも同じ「変換失敗を NULL に逃がす」発想が要る。SQL の TRY_系とセットで
- SQL Server 実行計画の読み方 — Estimated vs Actual で最初に見る5箇所 — 暗黙変換がスキャンに化けてるのを自分で掴むための応用編
- SES の年収・単価を逆算する — 額面からマージンまで — 型変換が早く潰せる業務SEは現場で重宝される。その「単価」を数字で見ておく話
型変換で手こずってる同業がいたら、この記事ぶん投げてやってください。どんどんシェア待ってるぜ!!
以上!
この記事の参考文献
- 『Pro SQL Server Internals』 Dmitri Korotkevitch 著 (Apress, 2016) — 引用ページ: p.75, p.78
SQL Server の内部構造 (ストレージ / インデックス / トランザクション / 統計情報 / 実行計画) を DBA レベルで深掘りした技術書。この記事で書いた「暗黙変換が non-SARGable を生んでインデックスシークを殺す」という話の根拠は同書 Chapter 2 (SARGable predicates と data types) に拠っています。業務で遭遇する性能問題の根本原因を理解したい業務SE / DBA 向けのバイブル。
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る

コメント