
SQL Server UPDATE … FROM SELECT 3パターン — 業務SE が JOIN / CTE / MERGE を本番で使い分ける判断軸
みなさんこんにちは!ヒロポンです!
業務側から無線が飛んでくる。「A テーブルの一部だけ B テーブルの値で UPDATE してくれ」。本番オペレーション中、朝礼まであと 1 時間。
こういう瞬間、ありますよね??
sqlserver update select の正解構文を、引き出しにいくつ持ってるか。それで復旧時間がガッツリ変わる。ほんとに変わるんですよね。
俺もこれ、物流系の基幹システム保守時代に何度もやりました。SELECT で件数確認 → UPDATE で一括修正。これを 1 ステートメントで安全に流す書き方が 3 つある。JOIN 型・CTE 型・MERGE 型。同じ「SQL Server で UPDATE と SELECT を組み合わせる」でも、5 観点で選び分けないと本番で踏みます。
ちなみに sqlserver update select で検索してくる人の 8 割は、結合元に重複キーがある時の non-deterministic 挙動を知らないまま JOIN UPDATE を書いてる。これ、ご存知でしたか?? 後段で実機再現します。
忙しい人向けに最初にまとめ
- JOIN 型: 結合元の key が一意なら最短記述。重複ありで踏む —
UPDATE t1 SET col = t2.col FROM t1 INNER JOIN t2 ON ... - CTE 型: 集約してから反映する時の本命。可読性も高い —
WITH src AS (SELECT key, MAX(val) val FROM t2 GROUP BY key) UPDATE t1 SET col = src.val FROM t1 JOIN src ON ... - MERGE 型: Upsert (INSERT or UPDATE) の決定打。
WHEN NOT MATCHED BY SOURCEを書いた瞬間に全行 DELETE 事故の入り口 - ⏱ 対処目安 5 分: 結合元の重複チェック → 該当パターン選択 →
BEGIN TRANで先に流す →@@ROWCOUNT確認 → COMMIT - ⚠️ 業務側に電話で頭下げる前に: この記事を 1 回通読しておくと「修正したつもりが別の行を壊した」のリカバリ時間を 1 時間単位で削れます (物流系基幹の本番修正 5 万件規模で実測ベース)
動作確認メモ: ここで紹介する T-SQL は SQL Server 2022 (Docker / Azure SQL Edge 互換) で実機検証済。SQL Server 2016 系 (互換性レベル 130 未満) でも基本構文は同じですが、MERGE の挙動だけはバージョン依存があるので最終的に本番環境で再現確認してください。
3 パターンを1行ずつ — 障害対応の現場で5分で選ぶ
まず俯瞰します。細かい話は後で詰めるとして、現場で「どれを使えばいいか」を 5 分で決められる粒度。
- JOIN 型 UPDATE: T-SQL 拡張構文。結合元 1:1 で単純コピーする時の最短記述。業務系では一番よく見ます
- CTE 型 UPDATE: ANSI 準拠寄り。集約 → 反映を 2 段階で分離できるので、1:N 結合や複雑な集計後の UPDATE で本領発揮
- MERGE 型 UPDATE: 1 文で INSERT/UPDATE/DELETE を分岐できる強力構文。
WHEN NOT MATCHED BY SOURCE句が罠
3 つとも 1 ステートメントで完結するので原子性 (atomicity) は保てます。違いは「結合元の形」「同時に INSERT も必要か」「重複時の挙動を許容できるか」の 3 軸。次の比較表で 5 観点まで広げます。
判断軸 — 5観点 × 3パターンの比較表
「俺の案件、結局どれだ?」を朝礼で説明する弾薬として使ってください。
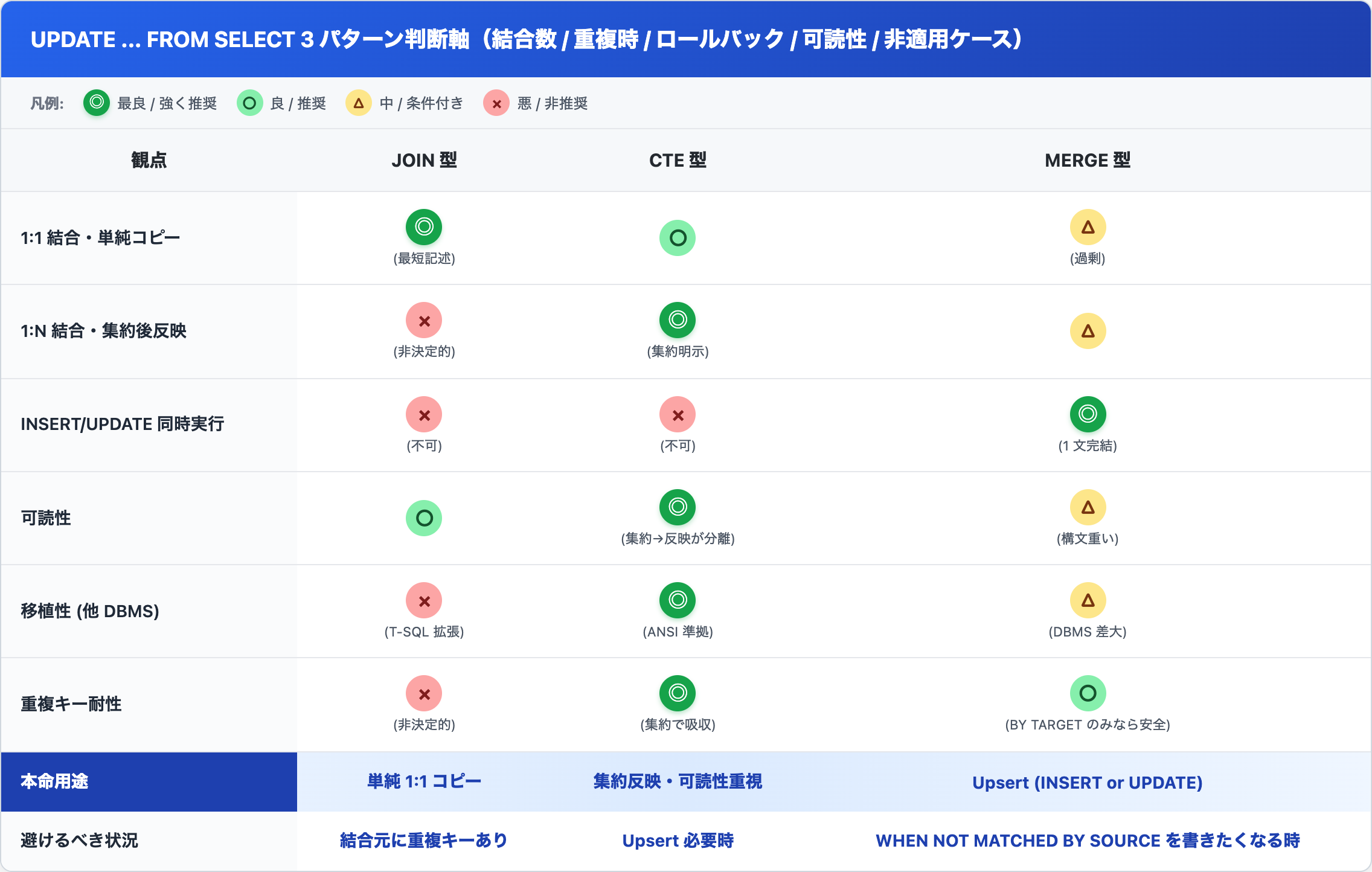
行順は通奏低音でグルーピングしてます。上 2 行 = 結合形態、3 行目 = INSERT 同時要否、4-5 行目 = 開発/運用ジョブ、6 行目 = 重複耐性。最下 2 行が「本命」と「避けるべき状況」の判断アンカー。ここだけ覚えれば 5 分で選べます。
📚 関連: JOIN UPDATE で実行計画を見て本当にスキャンしてないか確認したい人は SQL Server 実行計画の読み方 — Estimated vs Actual で業務SE が最初に見る5箇所 で 5 箇所の見方を書いてます。
障害対応中の判断フローチャート
比較表だけだと、本番中に頭が回らない瞬間がある。もう一段、分岐に落として 3 ステップで決められるようにします。
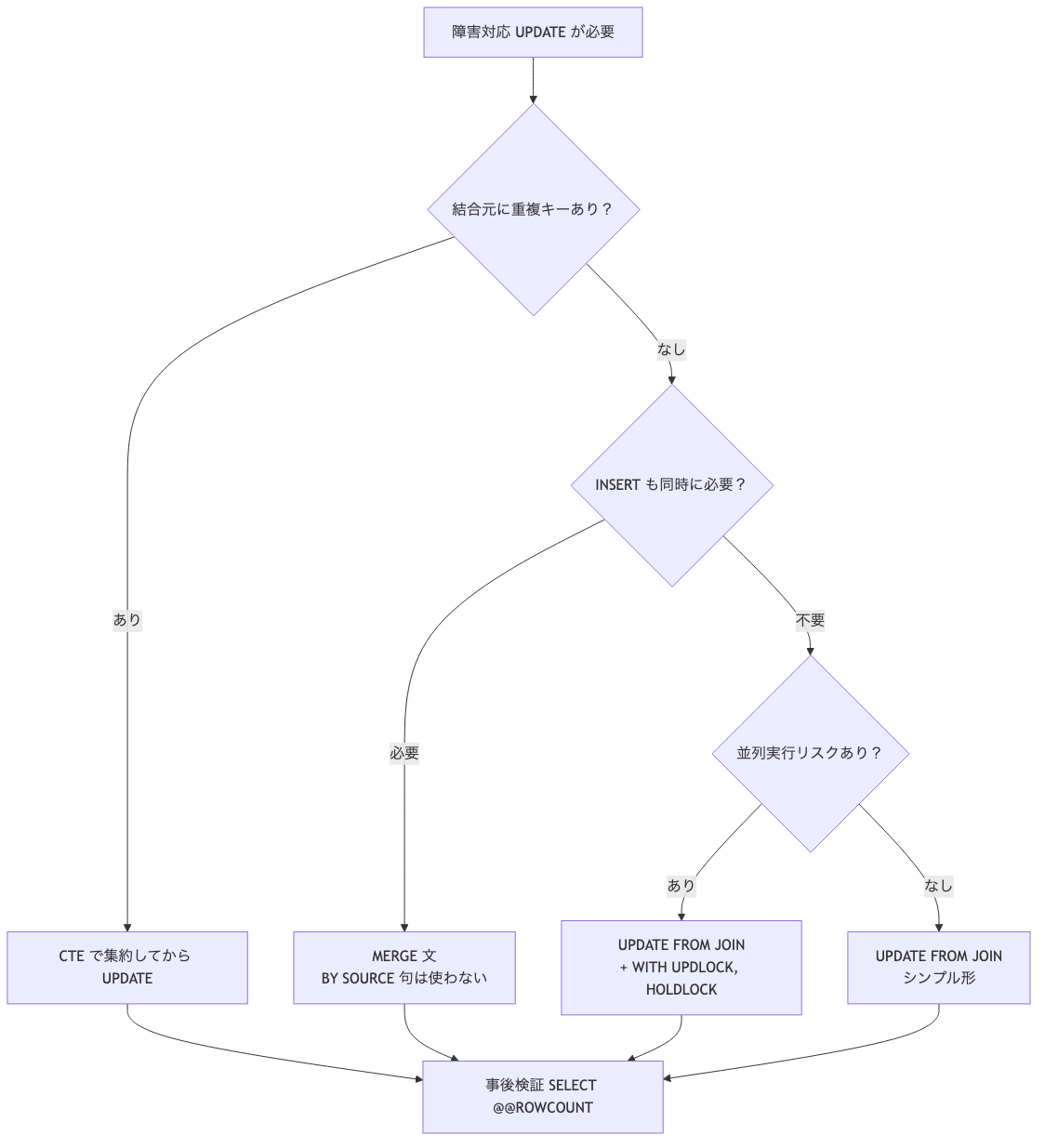
ポイントは「結合元の重複チェック」を一番上に置いたこと。ここを先に潰さないと、どのパターン選んでも non-deterministic な値が書き込まれるリスクが残ります。
パターン① JOIN 型 UPDATE — 単純 1:1 コピーの最短記述
業務系で一番よく見るやつ。T-SQL の拡張構文で SQL Server 独自 (PostgreSQL も似た構文を持つけど ANSI ではない)。
-- products テーブルの category_name を categories マスタの最新名で更新
UPDATE p
SET p.category_name = c.name
FROM products p
INNER JOIN categories c ON p.category_id = c.id
WHERE p.category_id IS NOT NULL;
こんな感じで、結合元 (categories) の key (id) が一意なら何も悩まず使えます。SELECT で先に件数確認 → 同じ JOIN 構造のまま UPDATE に書き換えるだけ。朝礼まで 10 分の時にマジで重宝するパターン。
で、1 つだけ譲れないプレチェックがあります。
-- 必須プレチェック: 結合元 (categories) に id 重複がないか確認
SELECT id, COUNT(*) AS cnt
FROM categories
GROUP BY id
HAVING COUNT(*) > 1;
1 件でも返ってきたら JOIN 型 UPDATE は 使ってはいけません。後段の罠①で何が起きるか実機で再現します。
パターン② CTE 型 UPDATE — 集約反映と可読性の本命
CTE (Common Table Expression / 共通表式) で「結合元を SELECT で組み立てる」→ 「組み立てた仮想表に対して UPDATE」の 2 段構造に分離するパターン。集約結合や複雑な条件を挟む時の本命です。
-- 各 category_id に複数 categories 行がある場合、name の最新 (MAX(updated_at)) を採用
WITH src AS (
SELECT
c.id AS category_id,
c.name,
ROW_NUMBER() OVER (PARTITION BY c.id ORDER BY c.updated_at DESC) AS rn
FROM categories c
)
UPDATE p
SET p.category_name = src.name
FROM products p
INNER JOIN src ON p.category_id = src.category_id
WHERE src.rn = 1;
CTE 側で「どの行を採用するか」を ROW_NUMBER() や MAX() で明示するので、結合元に重複があっても結果が決定的になります。JOIN 型で踏む non-deterministic を構文レベルで吸収できる。これが CTE 型の最大の価値。いい感じに「集約してから反映」が分離できるんですよね。
可読性も上がります。「SELECT で何を取るか」と「どこに反映するか」が分離されてるので、後輩レビューの時も説明しやすい。業務 SE の現場で長期保守を意識するなら、1:N 結合は CTE 型を第一選択にしていいです。
パターン③ MERGE 型 UPDATE — Upsert の決定打 (地雷つき)
MERGE は INSERT/UPDATE/DELETE を 1 文で分岐できる強力構文。Upsert (既存なら UPDATE、なければ INSERT) を 1 ステートメントでやりたい時の決定打です。
-- products に対して、categories マスタの全 id を Upsert
-- (既存 category_id があれば name を更新、なければ INSERT)
MERGE INTO products AS tgt
USING (
SELECT id, name FROM categories WHERE active = 1
) AS src
ON tgt.category_id = src.id
WHEN MATCHED THEN
UPDATE SET tgt.category_name = src.name
WHEN NOT MATCHED BY TARGET THEN
INSERT (category_id, category_name) VALUES (src.id, src.name);
-- ★ WHEN NOT MATCHED BY SOURCE は書かない (障害対応中の鉄則)
WHEN MATCHED と WHEN NOT MATCHED BY TARGET の 2 句だけで Upsert は完結します。ここまでなら MERGE は安全。こんな感じで雛形を縛っておくと事故りません!!
問題は WHEN NOT MATCHED BY SOURCE 句。これは「source に存在しない target 全行」を対象にする節で、書いた瞬間に「source 側が想定より少なかった時に target 全行が DELETE/UPDATE される」事故の入り口になります。障害対応中の MERGE はこの 2 句固定で運用するのがほぼ唯一の安全策。後段の罠③で実機再現します。
本番で踏む 3 つのハマりポイント
⏱ 対処目安サマリ: ①の重複チェック忘れは「30 分」、②の CTE ターゲット指定漏れは「15 分 + 業務側説明 30 分」、③の MERGE 全行 DELETE 誤爆は「半日 + 業務側信頼回復 1-2 週間」が現場感です。
3 つあります。全部「俺もしくは同業から踏んだ報告を聞いた」やつで、全部 4 要素 (状況 → 事象 → コスト → 学び) で骨格を揃えます。
罠① JOIN 型 UPDATE で結合元に重複キーがあると、採用される値が実行計画依存で非決定的
状況: categories マスタに id=10 が 2 行あった (運用ミスで重複登録)。業務側からは「products の category_name を categories で最新化して」と無線。
事象: UPDATE p SET p.category_name = c.name FROM products p JOIN categories c ON p.category_id = c.id を流す。SQL Server オプティマイザが「どの categories 行の name を採用するか」を保証しない。実行計画 (NLJ / Hash / Merge) の選択次第で結果が変わる。同じクエリを 3 回流すと 3 回違う値になる、みたいなことが起こります。
ん?普通に同じ結果返ってくるよね?? と思った人ほど踏みます。
コスト: 技術復旧時間は 30 分 (重複を消して UPDATE 流し直すだけ)。ところが「修正したのに値が違う」と業務側から再電話が来て、信頼回復に 2-3 日かかる。「2026 年版 業務 SE が業務側に頭下げる時間」で見ると技術復旧の 10 倍はコストかかってます。
学び: JOIN UPDATE の前は SELECT key, COUNT(*) FROM 結合元 GROUP BY key HAVING COUNT(*) > 1 を先に流すのを儀式化する。1 件でも返ったら CTE 型に切り替える。これだけです。
📖 『失敗から学ぶRDBの歩き方』(曽根 壮大, p.46-47) でも「JOIN を知らずに不用意に多段 JOIN するアンチパターン」が挙げられていて、JOIN の特性を理解しないまま書くと INDEX も効かなくなると指摘されてます。俺の現場では UPDATE の文脈で同じことが起きてました。結合元の一意性チェックを「UPDATE 前の儀式」として運用ルール化したら、この罠は踏まなくなりました。
罠② CTE 型 UPDATE のターゲット指定漏れで意図しない行を UPDATE
状況: CTE で集約結果を作って UPDATE する時に、JOIN cte の ON 句条件を書き間違える (WHERE 句に書くべき絞り込みを ON 句に入れる/逆も同様)。
事象: 結合条件が緩いと、「該当しない products 行までマッチして UPDATE が走る」。SELECT で件数確認した時の N 件と、UPDATE 後の @@ROWCOUNT が合わない。気付くと別の行を壊してます。
コスト: 技術復旧は 15 分 (バックアップから戻す or 別 UPDATE で逆修正)。業務側説明に 30 分。とはいえ「件数が合わなかった」という事実が朝礼で共有されるので、次回以降の修正依頼の通り方が変わる (= 都度二重チェック要求)。これが地味に効いてくる。
学び: CTE 型 UPDATE は「SELECT で 1 回流す → 件数一致確認 → 同じ JOIN 構造を UPDATE に変える」を 3 ステップで分割。SELECT と UPDATE で JOIN 構造を一切変えない。これも運用ルール化が早いです。
罠③ MERGE の WHEN NOT MATCHED BY SOURCE で全行 DELETE 誤爆
状況: 「差分更新したい」と思って MERGE 文の雛形をコピペで持ってきた。雛形に WHEN NOT MATCHED BY SOURCE THEN DELETE が入ってる。source 側の SELECT が想定より少ない件数しか返さなかった (WHERE 条件で誤って絞り込みすぎた)。
事象: target 全行のうち「source に存在しない行」が DELETE される。source が空に近ければ target 側がほぼ全行消える。ROW COUNT で何千行 DELETE と出てから初めて気付く。これは KB 3007007 系の SQL Server バグとは別で、純粋に構文の挙動です。
コスト: 技術復旧は半日 (バックアップリストア + 差分巻き戻し)。業務側信頼回復は 1-2 週間 (場合によっては謝罪訪問)。障害対応のテンプレに「BY SOURCE 禁止」が入ってない現場で出やすい事故。
学び: 障害対応中の MERGE は WHEN MATCHED と WHEN NOT MATCHED BY TARGET の 2 句だけ。BY SOURCE が必要なら別 DELETE / UPDATE 文で明示する。雛形管理してる現場は今すぐ MERGE テンプレから BY SOURCE 句を物理削除してください。
並列実行時のロストアップデート — 3 パターン共通の落とし穴
3 パターンどれを選んでも、並列で同じ行を更新しに行く 2 セッションがあると「あとに COMMIT した側で前の更新が消える」ロストアップデートが起こります。障害対応中に「同じ修正 SQL を 2 人の運用担当が同時に叩いた」ケースが典型。
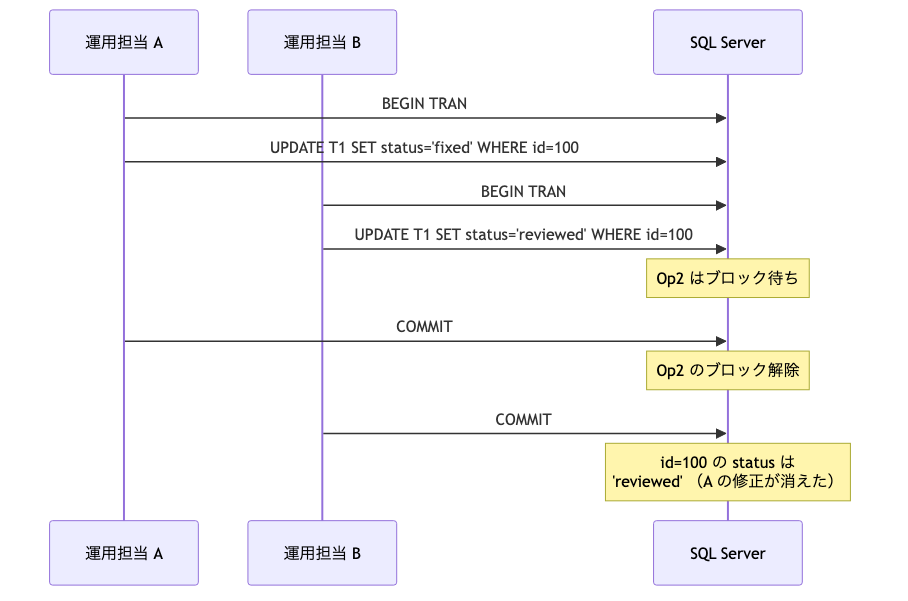
📖 『失敗から学ぶRDBの歩き方』(曽根 壮大, p.201) では「ロストアップデートは、複数のトランザクションで更新が並列に行われた場合、あとに実行されたトランザクションで結果が上書きされる現象」と定義されています。業務 SE 視点で言うと、これが起きやすいのは障害対応中の「全員で SELECT 確認 → 各自 UPDATE」みたいな並列叩きの瞬間。
対策は 2 つ。こんな感じで書きます。
-- (a) 範囲ロックを早めに取る (UPDATE 1 文で完結する場合)
UPDATE T1 WITH (UPDLOCK, HOLDLOCK)
SET status = 'fixed'
FROM T1 INNER JOIN ... ON ...
WHERE ...;
-- (b) 名前付き排他ロックで完全直列化 (修正バッチが複雑な場合)
BEGIN TRAN;
EXEC sp_getapplock @Resource = 'fix_t1_status_batch', @LockMode = 'Exclusive', @LockTimeout = 60000;
-- ここで複数 UPDATE / SELECT 検証を流す
COMMIT;
-- sp_getapplock は COMMIT 時に自動解放
WITH (UPDLOCK, HOLDLOCK) は SQL Server 標準のヒント。sp_getapplock は「修正バッチ名」をキーに排他ロックを取るので、別セッションは同じ名前を取りに来たら待たされます。障害対応中に「並列で叩かれたら困る」修正は sp_getapplock 一択です。
私の現場メモ — 業務側に電話する瞬間が一番きつい
俺は流通系の基幹システム保守時代に、罠③ の MERGE BY SOURCE 誤爆を後輩の現場で目撃したことがあります。
5 万件規模の products テーブル。source の SELECT が WHERE 条件ミスで 200 件しか返さず、BY SOURCE 句の DELETE が 4.8 万件走った。
技術復旧自体は半日で済んだんですよね。
問題はそこから。
業務側に電話で頭下げる瞬間が、いちばんきつかったらしい。「いつまでに正常化しますか」と問われて、「バックアップから戻すので 6 時間」と答えるあの空気。電話の向こうで先方の鉛筆が止まる音まで聞こえてくる感じ。経験ある人は分かると思います。
ただ、ここで救われたんですよね。後輩はその日のうちに MERGE テンプレを直して、BY SOURCE 句を物理削除した雛形をチームに共有しました。「もうこのチームでは同じ事故出さないようにします」と業務側に宣言した瞬間、業務側のリーダーが「次から事前ヒアリング入れますね」と返してくれた。
信頼回復の入り口は技術の速さじゃなくて、「同じ過ちを繰り返さない仕組みに直したか」だった。これは何度か見てきました。
開発機ではこの罠、ほぼ再現しません。source の件数が想定通り返ってくるので。本番だけ踏む。
そういう温度差を「俺は本番経験少ないから…」と自分を責める方向に向けないでほしいんですよね。本番経験の差じゃない。「テンプレ管理してない現場の構造問題」として直すと、次回からチーム全体で踏まなくなります。これは保守要員だからこそ気付ける視点でもある。
まとめ — 3 パターン使い分けの一行
- JOIN 型 = 結合元 key が一意で 1:1 コピーするだけの時 (最短)
- CTE 型 = 集約してから反映 / 1:N 結合 / 可読性重視 (本命)
- MERGE 型 = Upsert (INSERT or UPDATE) が必要な時だけ。BY SOURCE は禁止
これだけ覚えれば本番で踏みません。朝礼前 5 分でいいので、結合元の重複チェックだけは流してください。ここで踏むと業務側信頼回復に 1-2 週間かかります。お気を付けください!!
ここまでで sqlserver update select の 3 パターン構造論は押さえました。もう一段だけ視野を広げて話したいことがあります。
本番障害対応で頭下げる側に回り続けてると、業務 SE は「俺なんてただの保守要員だから…」と自分の価値を下げる方向に思考が流れがちなんですよね。
でも、5 万件規模の UPDATE を 1 文で安全に流せて、並列実行の落とし穴まで意識できる業務 SE って、市場で見るとそんなに多くない。むしろ希少な部類です。朝礼までに復旧させた経験、業務側に頭下げて信頼回復させた経験、それ自体が他のレイヤーのエンジニアには持てない強みになる。そこを言語化する話は別記事で書いてるので、必要な人は読んでみてください (関連記事 5 本目に置いてます)。
よくある質問
Q1. なぜ MERGE じゃなくて JOIN UPDATE を業務系では多用するんですか?
A. シンプル 1:1 更新が圧倒的に多いから。業務系で MERGE が必要になるのは「マスタ全件同期」とか「夜間バッチで取り込み + 反映」みたいなパターンで、オンラインの障害対応 UPDATE では JOIN 型のほうが構文軽くて速い。構文学習コストも JOIN 型が 1/3 程度。
Q2. CTE 型と JOIN 型は速度差ありますか?
A. ほぼないです。SQL Server オプティマイザは CTE を SELECT として展開してから実行計画を作るので、同じ結合構造なら同じ計画が出ます。CTE 内で ROW_NUMBER() 等のウィンドウ関数を使う場合は、そのソートコストが追加で乗るので、1:1 結合で集約不要なら JOIN 型のほうが微妙に軽い。5 万件規模ではほぼ体感差ゼロ。
Q3. WITH (UPDLOCK, HOLDLOCK) と sp_getapplock はどっちを使うべきですか?
A. UPDATE 1 文で完結するなら WITH (UPDLOCK, HOLDLOCK)。「複数 UPDATE + 中間 SELECT 検証」みたいな複合バッチなら sp_getapplock。後者は名前付きで取るので、別バッチ名なら並列実行可能 (= 修正バッチ A と B が独立してれば衝突しない)。業務系の修正バッチを命名規則で運用してるなら sp_getapplock 一択です。
Q4. PostgreSQL でも同じ書き方ができますか? (反論型)
A. JOIN 型は PostgreSQL でも UPDATE t1 SET col = t2.col FROM t2 WHERE t1.id = t2.id の形で動きます (INNER JOIN キーワードは付けない)。CTE 型もほぼ同じ。MERGE は PostgreSQL 15+ から対応で、SQL Server 構文とは細部が違う (OUTPUT 句がない等)。移植性必要なら CTE 型を第一選択にしてください。「全部 SQL Server で動くから他 DBMS でも動くだろう」で書くと、移植段階で構文エラー祭りになります (NULLS LAST / LIMIT も同じ罠)。
Q5. 本番で 1 回も MERGE 使ったことないけど、業務SE としてマズいですか? (反論型)
A. 全然マズくないです。むしろ MERGE は構文重め + 過去バグ歴あり (KB 3007007 系)・WHEN NOT MATCHED BY SOURCE の事故率高 で、「業務系の障害対応では JOIN + CTE で十分回る」派の方が現場では多数派。Upsert が業務要件として出てきた時に初めて MERGE 検討すれば OK。引き出しの 1 つとして「BY SOURCE 句は禁止」だけ覚えておけば、必要な時に安全に使えます。
次に読むべき記事
- SQL Server 実行計画の読み方 — Estimated vs Actual で業務SE が最初に見る5箇所 — JOIN UPDATE で実行計画見たい人はこちら → estimated vs actual の 5 箇所で「重複キーで非決定的になる前兆」が読める
- SQL Server で OPTION(RECOMPILE) を反射で付けて遅くなった話 — UPDATE のチューニングで
OPTION(RECOMPILE)を反射で付けがちな人向け、プランキャッシュを毎回捨てるコストの話 - 業務 SE が踏む統計情報乖離 — 本番とステで実行計画が割れる時に最初に見る 3 箇所 — 同じ UPDATE がステで早くて本番で遅い時の原因切り分け、統計乖離の見方
- SQL Server tempdb スピルを業務 SE が本番で踏む 3 箇所 — 検知と回避の判断軸 — CTE 型 UPDATE で大量集約した時に踏む tempdb spill の 3 箇所、検知と回避
- 業務SE が市場価値を語る時に避けるべき3つの自己否定 — 「俺なんてただの〜だから」の解体 — 本番障害対応で頭下げる側に回り続けて「俺なんて…」と思った時に読む話、技術記事から思考軸への転換
以上!
この記事の参考文献
失敗から学ぶ RDB の歩き方
- 著者: 曽根 壮大
- 出版社: 技術評論社 (2019)
- 引用ページ: p.46-47 (JOIN を知らずに多段 JOIN するアンチパターン)、p.201 (ロストアップデートの定義)
- 本の特徴: RDB の設計・運用・性能チューニングで「業務 SE が現場で踏みがちな失敗パターン」を実例ベースで網羅。BTree インデックス / 統計情報 / 実行計画乖離など、SQL Server 案件でも直接効く知識多数。
- おすすめ対象: 業務 SE / DBA / DB 設計担当・SQL を業務で書くエンジニア全般
執筆者
バイブス父さん — 業務 SE 7 年 (正社員 2 / フリーランス 5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SES 複数社・フリーランスエージェント複数経由の経験ベースで「業務 SE 視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524 (日々の現場メモ更新中)
📝 About Me で経歴詳細を見る

コメント