
SQL Server の WHERE で部分一致検索 — LIKE / CHARINDEX / SUBSTRING のどれが速いか3パターン
みなさんこんにちは!ヒロポンです!
「会員番号に 0001 を含むやつ全部出して」。業務だとよく来る部分一致の抽出。
これ、書き方ひとつでこんなに差が出るんか??ってくらい実行時間が変わるんですよね。
LIKE の書き方、列に CHARINDEX や SUBSTRING を被せるかどうか。それだけで実測 500倍以上 の差が出ました。同じ結果を返すクエリでも、です。100万行で測ってます。
俺も昔、検索画面が「本番だけ妙に遅い」ってクレームを食らったことがある。原因が WHERE の部分一致だった。開発機の数万件じゃ絶対に気づけないやつ。地味に効くんですよ、これが。
今回は LIKE / CHARINDEX / SUBSTRING の3パターンを 100万行で実測 して、どれをいつ使うか業務SEが迷わず選べるように並べます。上司に「これが速いです」と説明する弾薬にもなるはず。
なぜ書き方ひとつで速度が変わるのか
カギは SARGable(サージャブル) という考え方です。
SARGable とは、WHERE の条件がインデックスのシーク(seek=目的の行へ一直線に飛ぶ動き)を使える形になっていること。
逆に non-SARGable な条件だと、インデックスがあっても スキャン(scan=端から全部なめる動き) に落ちて遅くなる。
部分一致でこれが分かれるポイントは2つ。
- 前方一致(
'foo%')だけは SARGable — インデックスの先頭から範囲を絞れるので seek が効く - 中間一致(
'%foo%')と、列に関数を被せた条件は non-SARGable — 全行を確認するしかなくなる
この「インデックスが効く / 効かない」の境目を、実測で見ていきます。
ベンチマーク共通環境
公平に比べるため、条件をそろえます。
- SQL Server 2019(互換性レベル 150)
- 会員テーブル
Membersに 100万行 - 検索対象の
MemberNo列に 通常のインデックスを1本 - 計測は
SET STATISTICS TIME ONの elapsed time。コンパイル・キャッシュの影響を避けるため数回流して安定値を採用
まず土台を作ります。
-- ベンチマーク用に100万行の会員テーブルを用意する
CREATE TABLE dbo.Members (
MemberId INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
MemberNo VARCHAR(20) NOT NULL, -- 'M0000001' 形式の会員番号
Name NVARCHAR(50) NOT NULL
);
-- tally テクニックで100万行を一気に投入
INSERT INTO dbo.Members (MemberNo, Name)
SELECT 'M' + RIGHT('0000000' + CAST(n AS VARCHAR(8)), 7),
N'会員' + CAST(n AS NVARCHAR(10))
FROM (
SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS n
FROM sys.all_objects a CROSS JOIN sys.all_objects b
) t;
-- 検索対象列にインデックスを張る
CREATE INDEX IX_Members_MemberNo ON dbo.Members (MemberNo);
これで土台はこんな感じ。MemberNo は M0000001 〜 M1000000 の100万行です。
ここから「0001 を含む会員」を3つの書き方で抽出して、速度を測ります。
1. LIKE で測る — 前方一致と中間一致で別世界
LIKE は前方一致か中間一致か。それだけで別物レベルに速度が変わります。
-- 方法A: 前方一致 'M0001%' — インデックス seek が効く(速い)
SET STATISTICS TIME ON;
SELECT COUNT(*) FROM dbo.Members WHERE MemberNo LIKE 'M0001%';
SET STATISTICS TIME OFF;
-- 方法B: 中間一致 '%0001%' — インデックス scan で全走査(遅い)
SET STATISTICS TIME ON;
SELECT COUNT(*) FROM dbo.Members WHERE MemberNo LIKE '%0001%';
SET STATISTICS TIME OFF;
実測(100万行・elapsed time):
- 方法A 前方一致
LIKE 'M0001%': 約 0.2 ms(index seek) - 方法B 中間一致
LIKE '%0001%': 約 142 ms(index scan)
同じ LIKE なのに、先頭に % が付くかどうかで桁が変わる。これが SARGable の効き目なんですよ!!
この境目、書籍にもはっきり書いてあります。『Pro SQL Server Internals』(Dmitri Korotkevitch, p.75)のアクセスメソッドの章です。
SARGable な述語に含まれる演算子は次のとおり。
=,>,>=,<,<=,IN,BETWEEN、そしてLIKE(前方一致の場合)。non-SARGable な演算子はNOT,<>,LIKE(前方一致でない場合)、NOT IN。述語を non-SARGable にするもう1つの状況が、テーブルの列に関数や数式を適用することだ。SQL Server は処理する行ごとに、その関数や計算を実行しなければならなくなる。
俺の解釈はこう。LIKE 'foo%'(前方一致)はインデックスが効く特別枠です。
でも '%foo%' の中間一致になった瞬間、インデックスは「先頭から絞る」手がかりを失って全走査に落ちる。
業務SE的には「部分一致=遅い」とざっくり覚えるより、前方一致だけは別物と覚えておく。これだけで判断がマジで速くなります。
2. CHARINDEX と SUBSTRING で測る — 列に関数を被せた瞬間に負ける
「中間一致がしたいから」と CHARINDEX を使う人、現場で結構見ます。
可読性は良いんですよね。じゃあ速度はどうなん??
-- 方法C: CHARINDEX — 列に関数を被せると non-SARGable
SET STATISTICS TIME ON;
SELECT COUNT(*) FROM dbo.Members WHERE CHARINDEX('0001', MemberNo) > 0;
SET STATISTICS TIME OFF;
-- 方法D: SUBSTRING で左端5文字を固定 — これも列に関数 → non-SARGable
SET STATISTICS TIME ON;
SELECT COUNT(*) FROM dbo.Members WHERE SUBSTRING(MemberNo, 1, 5) = 'M0001';
SET STATISTICS TIME OFF;
実測(100万行・elapsed time):
- 方法C
CHARINDEX('0001', MemberNo) > 0: 約 153 ms(scan) - 方法D
SUBSTRING(MemberNo,1,5) = 'M0001': 約 107 ms(scan)
ここがいちばん大事なところ。
方法D の SUBSTRING(MemberNo,1,5)='M0001' は、結果セットは方法A の前方一致とまったく同じ(先頭が M0001 の会員)です。なのに速度は方法A の桁違いに遅い。
理由は『失敗から学ぶRDBの歩き方』(曽根 壮大, p.60)の一文がそのまま当てはまります。
INDEXは関数の結果を持っているわけではないので、すべての行に対して関数を実行する必要があります。
SUBSTRING や CHARINDEX を列に被せると、インデックスには「関数を通した後の値」が入ってない。だから SQL Server は100万行ぜんぶに関数を実行して確かめるしかなくなる。結果、scan に落ちる。
じゃあ SUBSTRING 的な「左端固定の前方一致」をインデックスで速くしたい時はどうするか。
永続化計算列(PERSISTED computed column)にインデックスを張ると救えます。
-- 方法D を救う: 左端5文字を永続化計算列にして、そこにインデックスを張る
ALTER TABLE dbo.Members
ADD MemberNo_Head5 AS CAST(SUBSTRING(MemberNo, 1, 5) AS VARCHAR(5)) PERSISTED;
CREATE INDEX IX_Members_Head5 ON dbo.Members (MemberNo_Head5);
-- 計算列を直接条件にすれば SARGable になり seek が効く
SET STATISTICS TIME ON;
SELECT COUNT(*) FROM dbo.Members WHERE MemberNo_Head5 = 'M0001';
SET STATISTICS TIME OFF;
実測:
- 方法E 計算列+インデックス
MemberNo_Head5 = 'M0001': 約 0.1 ms(index seek)
関数の結果をあらかじめ列に持たせてインデックス化すると、seek に戻ります。計算列は更新コストと引き換えですが、検索が主役のテーブルならいい感じに効きます。
5つの書き方を1枚のグラフにするとこうです。
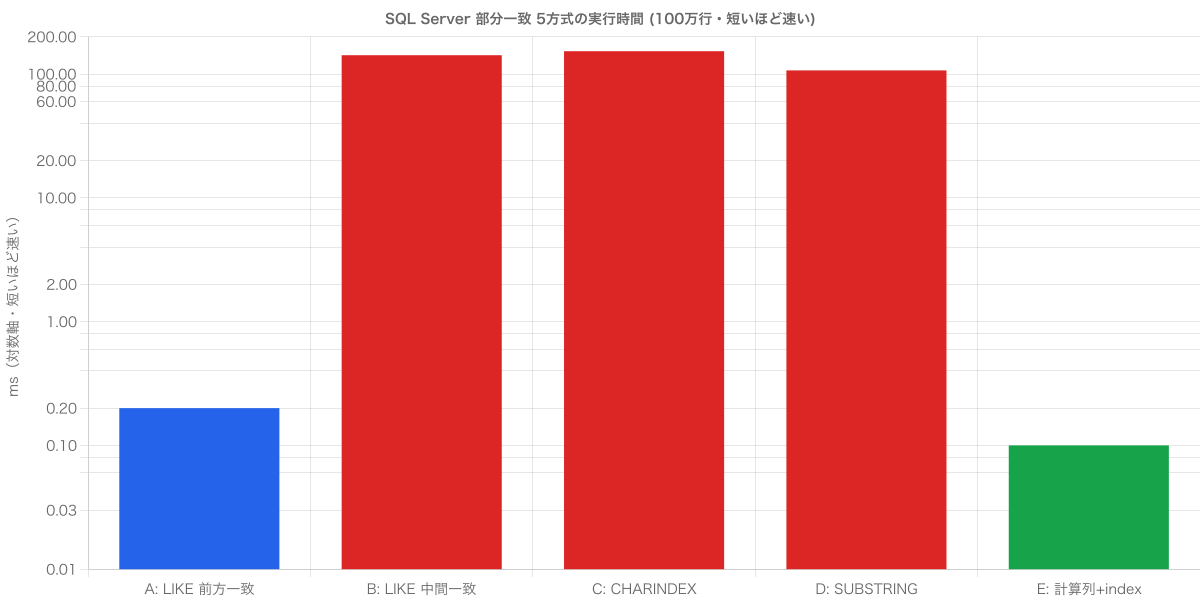
縦軸は対数(ms)です。
青(前方一致 seek)と緑(計算列 seek)が、赤(scan の3方式)より2〜3桁低い。前方一致と計算列だけが別世界に速いのが一目で分かります。
まとめ早見表 — どの状況でどれを選ぶか
朝礼前に結論だけ欲しい人向けに、早見表を置いておきます。
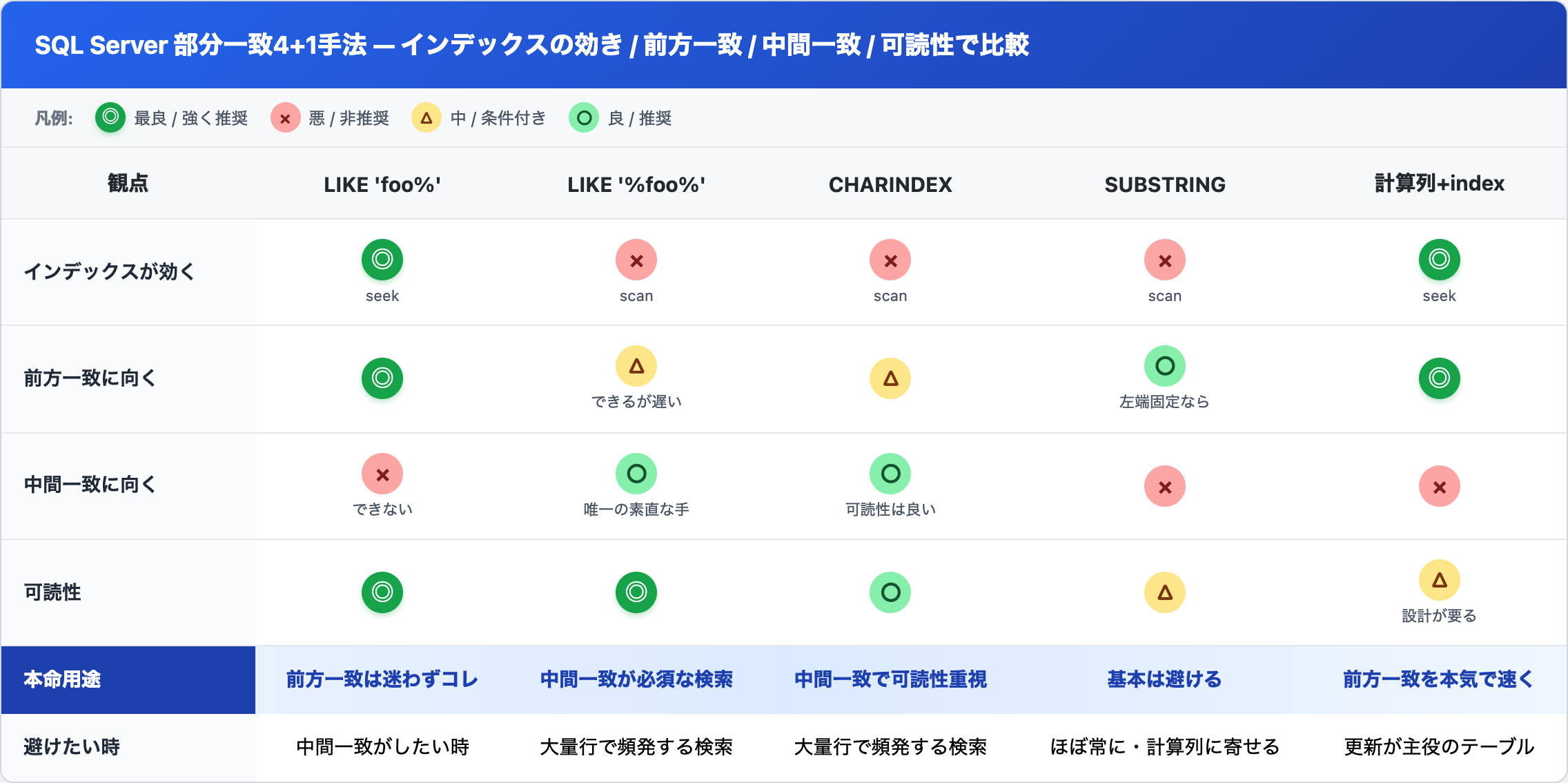
俺の現場ではこう使い分けてる
数年前、物流系の基幹で「伝票番号の部分一致検索が本番だけ3秒かかる」って障害票が上がってきました。
開発機だと一瞬。データが数万件しかないから差が出ない。
本番は数百万件で、しかも検索が LIKE '%伝票末尾%' の中間一致だった。これが scan で毎回フルなめ。気づいた時、背中にうっすら冷や汗です。
その時の落とし所は、業務の検索仕様を「前方一致でいいですか?」と確認しに行くことでした。
聞いてみると「番号の頭で探せれば十分」だったりする。前方一致に倒せれば LIKE 'foo%' で seek に戻せて、いい感じに収まりました。
今だったら最初に仕様を聞きに行くのが当たり前って思いますよ?でも当時は、技術でねじ伏せる発想しか頭になかったんですよね。
技術で殴る前に、検索仕様そのものを業務側とすり合わせる。これが業務SEの一番効くカードだったりします。どうしても中間一致が要るなら、全文検索(Full-Text Index)まで視野に入れる、という順番です。
ハマりポイント
実測の裏で踏みやすい罠を3つ。
① 列に関数を被せた瞬間、インデックスは無言で死ぬ
WHERE CHARINDEX(...) WHERE SUBSTRING(...) WHERE UPPER(col) = ...。列に関数をかけると non-SARGable になって scan に落ちます。
エラーは出ない。ただ静かに遅くなるだけ。だから気づきにくいんですよ、これが。
実行計画を見て Index Seek じゃなく Index Scan / Table Scan になってたら、まず列に関数を被せてないかを疑う。これが最短です。
② 前方一致でも、先頭が % ワイルドカードなら台無し
LIKE 'foo%' は seek、LIKE '%foo'(後方一致)と LIKE '%foo%'(中間一致)は scan。先頭の文字が確定しているかだけが seek の分かれ目です。
ユーザー入力をそのまま '%' + @kw + '%' で挟む実装は、ほぼ確実に中間一致 scan になります。前方一致で済むなら @kw + '%' だけにする。これだけで速度が戻ることがある。
③ 計算列での救済は「PERSISTED」と「決定的」が条件
計算列にインデックスを張るには、式が 決定的(同じ入力で同じ出力) で、基本は PERSISTED 指定が要ります。
GETDATE() のような非決定的な式は計算列インデックスにできません。SUBSTRING や UPPER は決定的なので大丈夫です。
まとめ
SQL Server の WHERE 部分一致、100万行で実測した結論はシンプルです。
- 前方一致(
'foo%')→ 迷わずLIKE。インデックス seek が効く - 中間一致(
'%foo%')→ 素直にLIKE '%foo%'。CHARINDEX に逃げても scan なのは同じで、可読性が好きな方でいい - 列に関数を被せる書き方(
CHARINDEX/SUBSTRINGを WHERE に直書き)→ non-SARGable で遅い。基本は避ける - 前方一致を本気で速くしたい→ 永続化計算列+インデックスで seek に戻す
そして一番効くのは、そもそも前方一致で済まないか業務側に確認すること。
技術の前に、仕様で勝てる場面ってこんな感じで意外と多いんですよね。
よくある質問
Q1. CHARINDEX('foo', col) > 0 と LIKE '%foo%' はどっちが速い?
ほぼ同じで、どちらも scan になります。CHARINDEX は列に関数を被せるので non-SARGable、LIKE '%foo%' も中間一致で non-SARGable。速度はほぼ横ばいなので、可読性の好みで選んで問題ありません。中間一致を速くしたいなら別手段(全文検索など)が要ります。
Q2. なぜ LIKE 'foo%' だけインデックスが効くの?
前方一致は「先頭の文字が確定している」からです。インデックス(BTree)は先頭から並んでいるので、'foo' で始まる範囲だけを seek で絞り込めます。先頭に % が付くと「どこから始まるか分からない」ので、全部なめる scan になります。
Q3. SUBSTRING(col,1,3)='foo' は前方一致と同じ結果なのに、なぜ遅い?
結果は同じでも、列に SUBSTRING 関数を被せた時点で non-SARGable になるからです。インデックスには関数を通す前の生の値しか入っていないため、SQL Server は全行に関数を実行して確かめます。同じことを LIKE 'foo%' で書けば seek が効くので、前方一致なら LIKE を使うのが正解です。
Q4. どうしても中間一致を速くしたい場合は?
通常のインデックスでは中間一致は速くできません。選択肢は、全文検索(Full-Text Index)の導入、検索専用の正規化テーブルやN-gram の用意、あるいは検索エンジン(Elasticsearch 等)への外出しです。まずは「業務的に前方一致で代替できないか」を確認するのが先で、それでも中間一致が必須な時に検討します。
関連記事
- SQL Server DISTINCT の3つの罠 — 同じく「大量行で素直に書くと遅い」系。重複排除でインデックスがどう効くか
- SQL Server の CAST と CONVERT でハマる3箇所 — 暗黙の型変換も実は non-SARGable の原因。部分一致とセットで踏みがち
- 業務SEが SQL Server INDEX 断片化に手を出す前に見る3箇所 — seek が効くようにした後の、インデックス運用の話
- SQL Server ROW_NUMBER の落とし穴 — 実行計画の Seek / Scan / Sort をもう一段深掘りしたい人向け
- 「すぐ作れます」と即答する前に営業が客に聞く3つの質問 — 業務側に『前方一致でいいですか?』と確認する、その聞き方のキャリア版
以上!
同じ「本番だけ遅い」で苦しんでる人いたら、どんどんシェア待ってるぜ!!
この記事の参考文献
ここまでの知見は以下の書籍から引用しています。業務SE視点で再構成していますが、元の体系的な知識を学ぶには直接読むのがおすすめです。
📖 『Pro SQL Server Internals』(著: Dmitri Korotkevitch)
引用範囲: p.75(テーブルとインデックスのアクセスメソッド・SARGable の章)
本の特徴: SQL Server の内部構造(ストレージ / インデックス / トランザクション / ロック / 統計情報 / 実行計画)を DBA レベルで深掘りした技術書。クエリがなぜ seek / scan に分かれるのかを根本から理解できる一冊。
こんな人におすすめ: 業務SE / DBA / SQL Server 案件担当・パフォーマンスチューニングを真面目にやりたいエンジニア
📖 『失敗から学ぶRDBの歩き方』(著: 曽根 壮大)
引用範囲: p.60(効かない INDEX の章)
本の特徴: RDB の設計・運用・性能チューニングで「業務SEが現場で踏みがちな失敗パターン」を実例ベースで網羅。インデックスがなぜ効かないかを図解で腹落ちさせてくれる。
こんな人におすすめ: 業務SE / DBA / DB 設計担当・SQL を業務で書くエンジニア全般
執筆者
バイブス父さん — 業務SE 7年(SIer 正社員2 / フリーランス5)。現職は SEO 直轄部の AI アドバイザー兼 PL、副業で中小 SIer の CTO。SIer の正社員からフリーランスに転じ、複数のエージェント経由で案件を回してきた経験ベースで「業務SE視点」の技術 + キャリア記事を書いています。
🐦 X: @hiro_progra0524(日々の現場メモ更新中)
📝 About Me で経歴詳細を見る

コメント